Recientemente descubrí un bug en la versión de la biblioteca libsoup de Raspbian y, por extensión, de Debian Bookworm: si tenemos un servidor hecho con dicha biblioteca, cuando el cliente cierra una conexión, el servidor no cierra el socket. El resultado es que éste se queda en estado CLOSE_WAIT para siempre (o, al menos, hasta que se reinicie el servidor), con lo que poco a poco se van consumiendo los posibles File Descriptors hasta que llega un momento en el que ya no se pueden realizar ni aceptar más conexiones. Este bug está en la versión 3.2.2, que es la que lleva Debian Estable, pero fue corregido en la versión 3.3.0.
Lo primero que hice fue notificar el bug a Debian, indicando además el commit con el parche que lo soluciona. Pero dado que no sabía cuanto tiempo iban a tardar en aplicarlo, decidí buscar una solución.
Lo primero que pensé fue en utilizar pinning para instalar la versión 3.6.1 disponible en testing; por desgracia, la actualización me obligaba a actualizar un montón más de paquetes, y no me quería arriesgar a romper algo en mi Raspberry Pi.
La segunda opción, que fue la que utilicé, consistió en compilar desde las fuentes la última versión de libsoup e instalarla en /usr/local. Dado que este directorio tiene más prioridad que /usr, se cogería primero mi versión.
Lo que hice fue bajar el repositorio, cambiar a la versión, configurar el proyecto con meson, compilarlo e instalarlo con ninja, y reconstruir la caché de bibliotecas:
Hace tiempo escribí un artículo sobre cómo hice un cargador «inalámbrico» para mis cascos bluetooth, que me permitía cargarlos simplemente colgándolos del soporte. Tras todo este tiempo, esos viejos cascos (que eran un apaño que hice juntando unos cutres bluetooth con unos decentillos de cable) han llegado al final de su vida útil, así que me compré unos nuevos. Y, obviamente, los he adaptado para poder cargarlos igual. Así han quedado:
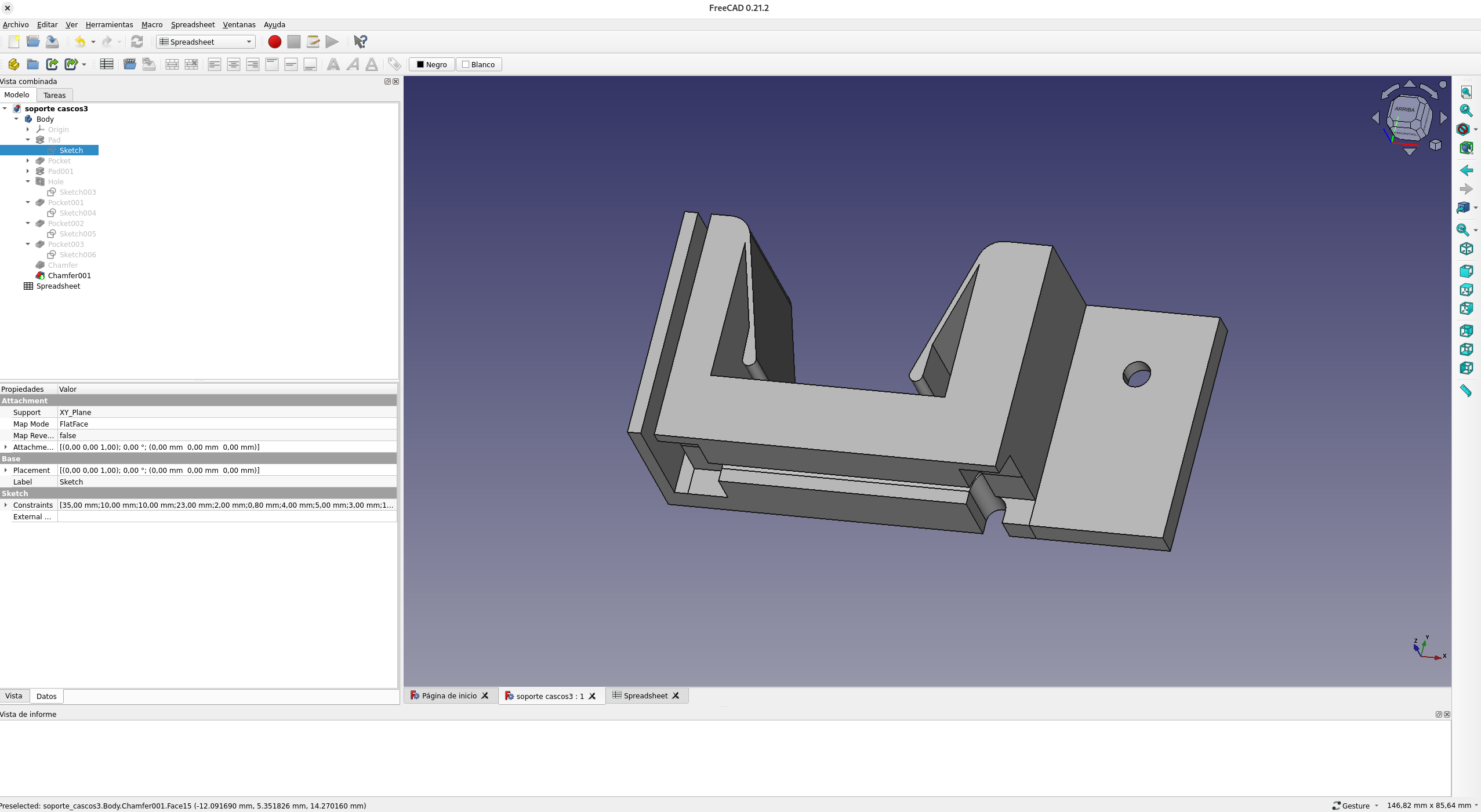
Lo primero que tuve que hacer fue modificar el soporte original, pues el ancho de la diadema era menor. Ya aproveché y lo hice paramétrico, de manera que poniendo el ancho de la diadema en la hoja de cálculo, automáticamente crea el bloque con el tamaño adecuado para que los contactos estén tres milímetros más cerca.
Una vez hecho el soporte, tocó cubrir las lengüetas con cinta de cobre y conectar el transformador.
Tras montarlo, me fijé que podía tener problemas de contacto, así que añadí más cinta de cobre de manera que ésta llegase hasta los bordes de las lengüetas.
Ahora tenía que hacer la conversión de mis cascos. Por motivos obvios, esta vez no quería desmontarlos ni manipularlos, así que decidí hacer un sistema «externo», que además fuese sencillo de transportar a otros cascos en el futuro.
Empecemos por recordar el esquema del sistema:
Este es el esquema original: en el soporte tendremos entre 9 y 12 voltios en continua. Dicha tensión pasará por un puente rectificador para que no importe en qué sentido colgamos los cascos. La salida del puente tendrá, debido a la caída de tensión en los diodos, 1,4 voltios menos (o sea, entre 7,6 y 10,6 voltios), pero sigue siendo demasiada para nuestros cascos, así que añadimos un regulador de tensión conmutado para bajarla a los cinco voltios que necesitamos. Estos cinco voltios irán a un conector USB-C estándar, que se enchufará al conector de carga de mis cascos.
Lo primero que hice fue soldar el puente de diodos al regulador:
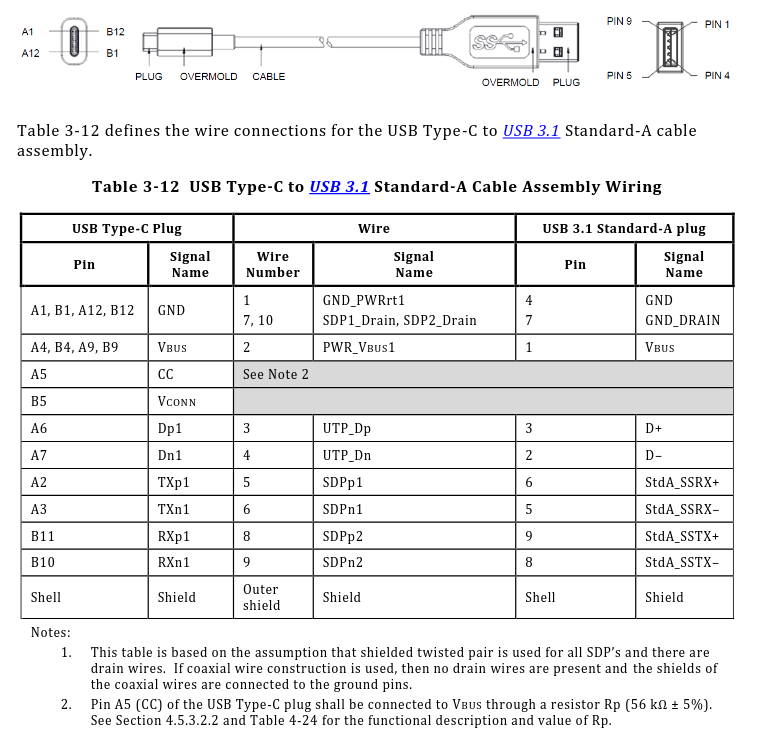
Una vez hecho esto, corté un cable USB-A a USB-C, quedándome con la parte del conector USB-C, y lo conecté a la salida del regulador. Esta era la opción más simple, pues, tal y como indica el estándar en la página 77, para que un conector USB-C pueda cargar algo, es imperativo que tenga, como mínimo, una resistencia de 56Kohm entre el pin A5 (CC) y alimentación, de manera que el dispositivo (en este caso nuestros cascos) sepa que puede alimentarse de él. Los cables USB-A a USB-C ya traen esta resistencia, por lo que eso que nos ahorramos. No recomiendo usar un cable USB-C a USB-C, pues tendríamos que añadir nosotros la resistencia, y, honestamente, no compensa.
También conecté dos cables a la entrada del puente rectificador, cables que, posteriormente, soldaré a las láminas de los cascos.
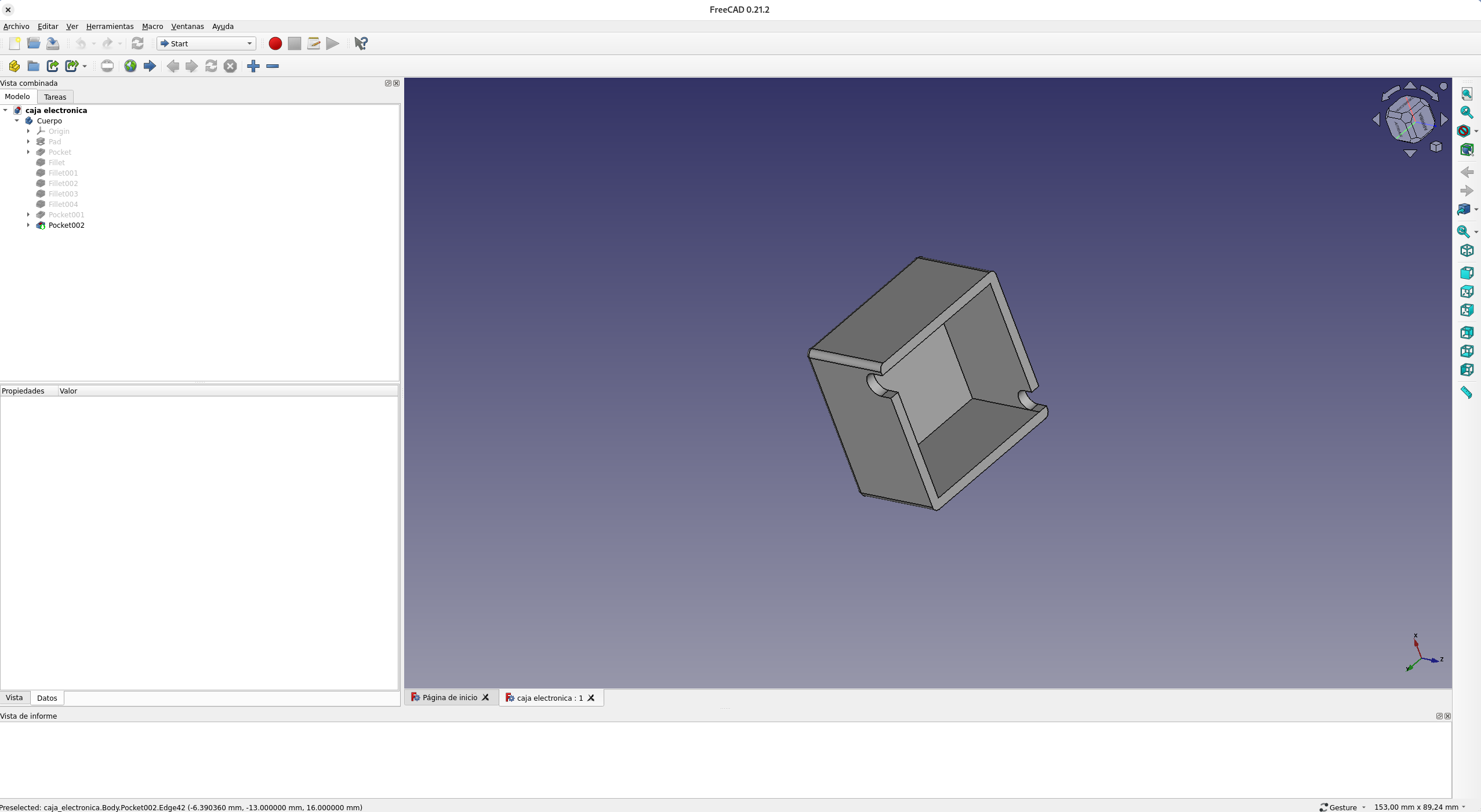
El siguiente paso fue hacer una cajita donde meter esto. ¡Bendita impresión 3D!
Llegó el momento de modificar los cascos. Lo primero fue pegar la cinta de cobre en la diadema, de manera que queden dos contactos para la carga. Para ello, primero la pegué en la parte superior, dejando un buen margen de cinta:
Tras ello, hice varios cortes transversales para poder doblar la cinta sobre el borde de la diadema, y que de esta forma quede una buena zona de contacto para el soporte.
Repetí el proceso en el lado opuesto, y así conseguí los dos contactos de la diadema. Una vez hecho esto, metí el circuito dentro de la caja y la pegué en el auricular derecho, donde está el conector.
Procedí a soldar los dos cables a las dos tiras de cobre de la diadema…
Y protegí el conjunto con un poco de cinta aislante del mismo color que los cascos, además de conectar el cable USB-C al conector de carga.
¡Y ya está! Mis nuevos cascos ya se cargan sólo con colgarlos del soporte.
Hace tiempo hice un programita para la Raspberry Pi 3 que utilizaba la biblioteca lg para realizar E/S desde C. Por desgracia, cuando intenté hacerla funcionar en una Raspberry Pi 5, no funcionó. Tras muchas pruebas y buscar documentación, descubrí que la clave estaba en la llamada de inicialización a lgGpioChipOpen(): en una RPi 1, 2, 3 o 4, el valor que hay que pasarle es 0, para que abra /dev/gpiochip0, pero en una RPi 5 hay que pasar el valor 4.
Un truco para saber programáticamente en qué modelo estamos consiste en leer /sys/firmware/devicetree/base/model. En mi Raspberry Pi 5 devuelve la cadena Raspberry Pi 5 Model B Rev 1.0. En una RPi 4 que tengo, devuelve Raspberry Pi 4 Model B Rev 1.1.
La Raspberry Pi lleva desde su primera versión un conector DSI que permite conectar una pantalla táctil directamente, alimentándose desde la misma placa y todo a través de un único cable.
Por desgracia, este conector cambió en la versión 5, y ahora tiene dos (que valen tanto para pantallas como para cámaras), pero más pequeños que el original, con lo que los viejos cables no sirven y hay que comprar uno específico.
Eso hice, pero todos los que encontré tienen un problema: las pistas de ambos conectores están hacia el mismo lado, pero los nuevos conectores están «al revés», así que me encontré con que la única manera de conectar la pantalla implica, o retorcer 180 grados el cable…
… o colocar la RPi5 boca abajo…
Y por desgracia, tampoco servía ponerla «de delante hacia atrás», porque el conector de la pantalla quedaba justo debajo:
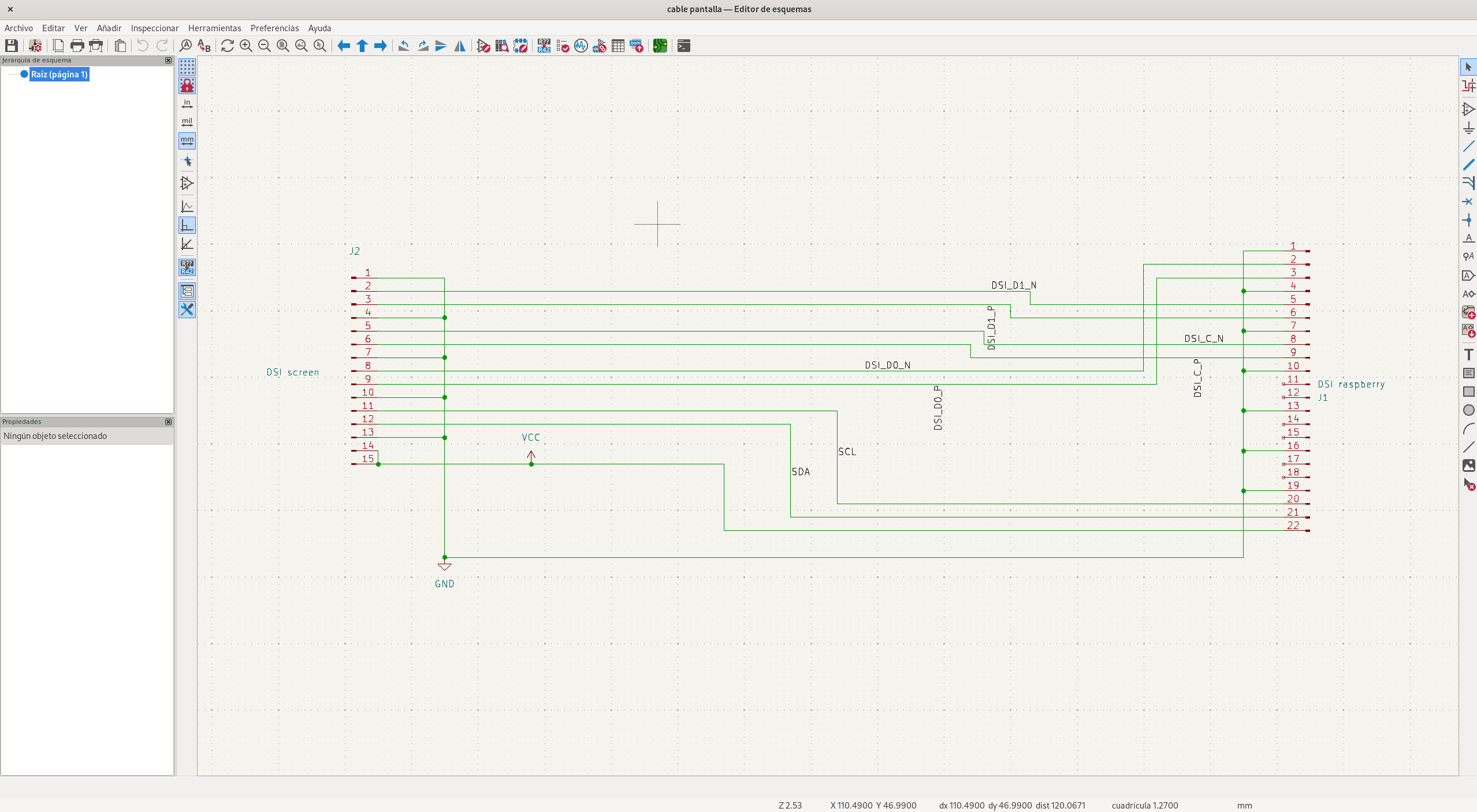
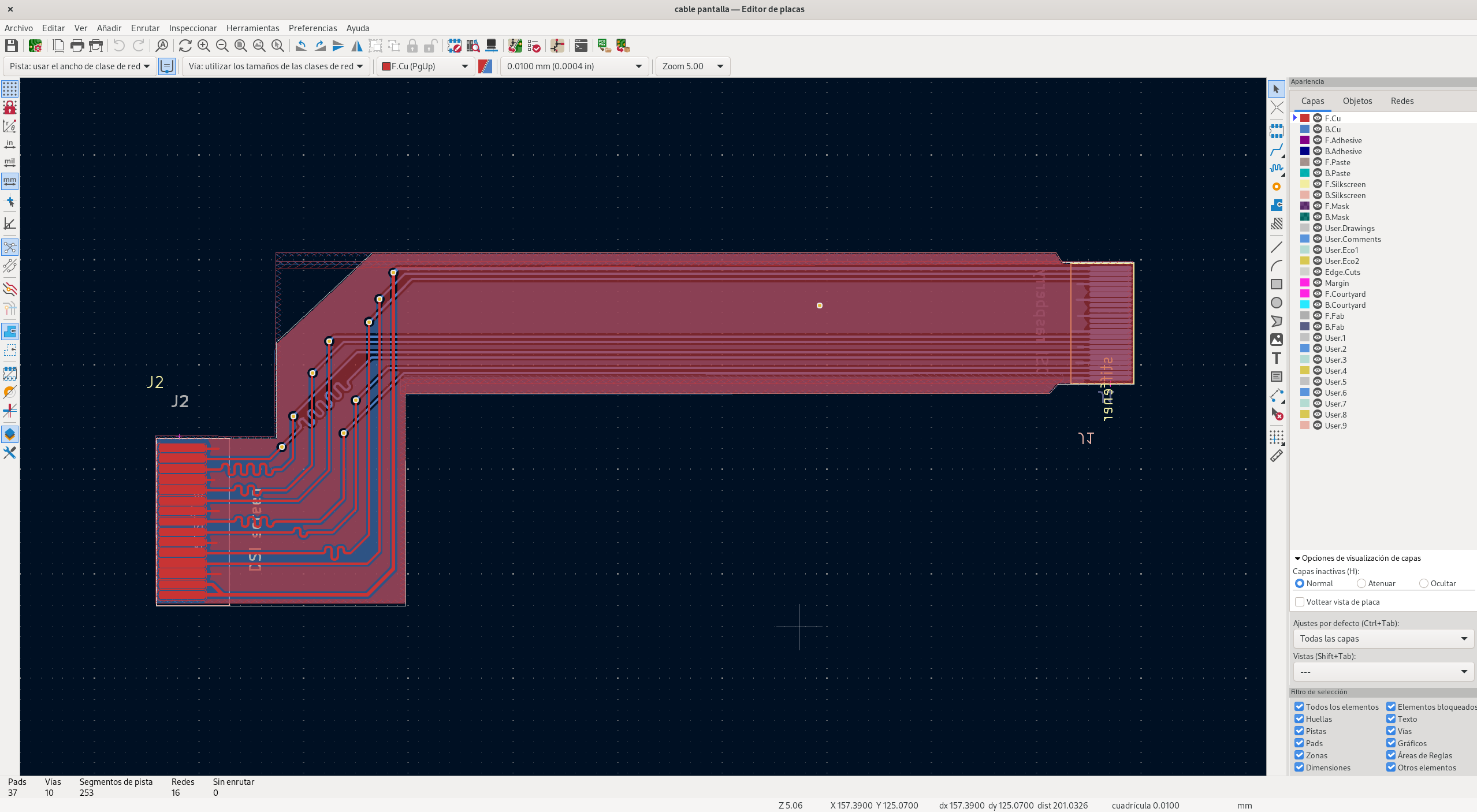
Ante esto, decidí liarme la manta a la cabeza y diseñar mi propio cable de conexión para la RPi5, así que cogí Kicad y empecé por diseñar el esquemático que necesitaba:
Básicamente hay que conectar alimentación y las distintas masas, las dos señales (SCL y SDA) del bus I2C para la pantalla táctil, y los tres pares diferenciales de la señal DSI (uno de reloj, DSI_C_x, y dos de datos, DSI_Dy_x). Las señales para el conector DSI de la pantalla las saqué a partir del conector de la Raspberry Pi 4. El pinout del conector de la RPi5 fue un poco más complicado de encontrar, pero al final apareció.
Tras ello, me fui al editor de placas y diseñé esto:
Un detalle importante fue asegurarse de que la longitud de los tres pares fuese la misma, para garantizar que las señales lleguen sincronizadas (no hay que olvidar que la señal de reloj utiliza un par propio). Para ello, seleccionando una pista, Kicad no sólo nos dice la longitud del segmento seleccionado, sino también la longitud total. Una vez encontrada la pista más larga, vamos al resto y utilizamos la herramienta de afinado de longitud, que tiene este icono:
para ir ajustando la longitud de cada una, de manera que midan lo mismo. Cabe recordar que una vez trazado el «gusanito», es posible ajustar el ancho, de manera que si no conseguimos a la primera la longitud correcta, debemos dejarlo más largo y luego reducir el ancho.
Si nos fijamos, también lo hice con el I2C, aunque en este caso no era realmente necesario, pues la velocidad es muy baja.
Idealmente, además, debería haber ajustado la separación de los pares de pistas para mantener la impedancia correcta; por desgracia, DSI es una especificación cerrada, por lo que no tenía acceso a esa información. Afortunadamente, todo funcionó a la primera.
A la hora de mandarlo fabricar, tuve que especificar que lo quería como una placa flexible, y además indicar que quiero que incluya stiffeners (las «pegatinas» que se ponen en la cara opuesta de cada conector para darle rigidez y que no se rompan).
Y este es el resultado: un cable que se adapta perfectamente a la RPi5 y la pantalla, sin dobleces ni cosas raras, y dejando completamente libre la zona superior del procesador y memoria para poder poner un disipador y ventilador.
Los esquemáticos están disponibles bajo una licencia MIT (vamos, que puedes usarlo con libertad) en mi repositorio de Gitlab.
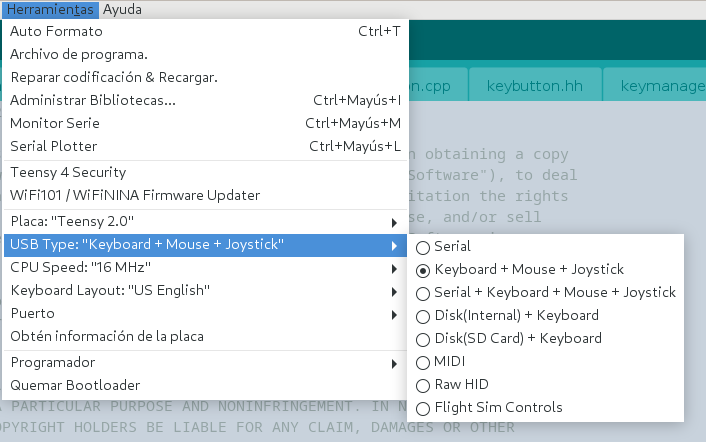
He empezado a añadir funcionalidades extra a mi teclado. En concreto, controles multimedia (volumen, etc). Y ya he encontrado un bug raro: sólo funcionan si la placa está en modo «keyboard+mouse+joystick», pero no en modo «serial+keyboard+mouse+joystick».
Las placas Teensy se pueden poner en varios modos desde el entorno de Arduino. Aquí los podemos ver:
Lo normal es utilizar el modo «Keyboard + Mouse + Joystick» para productos finales, y el modo «Serial + Keyboard + Mouse + Joystick» para depuración, pues podemos enviar texto a la consola. Sin embargo, por algún motivo, si la placa está en este último modo, los códigos de las teclas multimedia (KEY_MEDIA_VOLUME_INC, KEY_MEDIA_VOLUME_DEC, etc) no funcionan: no se recibe absolutamente nada (y lo he comprobado leyendo directamente de /dev/input/eventXX).
Después de muchos años, Terminus acaba de llegar a la versión 2.0. Y no ha sido «porque sí», sino porque ahora incorpora una nueva funcionalidad que creo que lo convierte en aún más útil: Drag’n’Drop.
Ahora es posible arrastrar un terminal agarrándolo por la barra superior (la que se pone roja cuando el terminal tiene el foco), y cambiarlo de sitio, bien dentro de la misma pestaña, en otra pestaña de la misma ventana o de otra ventana, en una nueva pestaña de la misma ventana o de otra ventana, o incluso en una nueva ventana. Esta característica permitirá evitar el «arrepentirse» de estar ejecutando algo en otra pestaña cuando ahora vendría mejor tenerlo junto a ese otro terminal; o si tenemos algo en la ventana tipo «Guake» y nos interesaría tenerlo en una ventana independiente, etc.
A mayores incorpora alguna que otra característica nueva, como permitir configurar el auto-ocultamiento del cursor. Así, si está activo, al teclear cualquier cosa, el cursor del ratón desaparecerá (y así no molesta), apareciendo de nuevo tan pronto se mueva el ratón.
Como de costumbre, se puede descargar en mi página web.
¡¡Hace unos días me han llegado las placas de PCBWay!! Pero como estuve fuera, hasta hoy no he podido poner nada.
Se trata de la versión 1.17 del teclado, que frente al diseño 1.0 de los teclados que construí hasta ahora, tiene tres NeoPixels, huella para el protector ESD, correcciones de compatibilidad con Teensy, serigrafía en los pines de programación, y algunos otros detallitos menores (como el maravilloso recuadro blanco para escribir anotaciones). Y el acabado es, sencillamente, perfecto. ¡Un 10 para PCBWay!
Después de la experiencia que he tenido, creo que estos teclados los voy a construir con pulsadores Cherry «de verdad». Iré contando.
Una nueva entrada para comentar que PCBWay ha tenido la gentileza de patrocinar este proyecto, con lo que podré actualizar mis actuales teclados a la versión 1.13 de la placa, con sus tres NeoPixels y demás.
Recientemente estuve haciendo algunos cambios extra en el diseño. Por ejemplo, combiné en ambos diseños la tecla SHIFT corta + tecla de «menor y mayor» de las distribuciones ISO, junto con la tecla SHIFT larga de las distribuciones ANSI. Esto permite combinar distribuciones, algo que puede ser interesante para aquellos que prefieran la tecla de RETURN americana, pero quieran usar una distribución española, por ejemplo.
También aproveché para añadir dos NeoPixeles más en los dos huecos que había entre F4 y F5, y F8 y F9, lo que permite aumentar las posibilidades.
Por supuesto, llegó también el momento de diseñar la carcasa, para lo que decidí aprovechar los resultados de un cursillo de diseño e impresión 3D que hice hace tiempo (¡¡¡¡Gracias por convencerme para ir, Miguel!!!!). No tendría que ser demasiado difícil…
El primer problema que me encontré fue que el teclado mide 32cm de ancho, pero las impresoras 3D normales tienen una cama de entre 20 y 30cm, lo que significa que no podía imprimirlo todo de una sola vez sino que tendría que dividir la carcasa en dos mitades que se pudiesen pegar. Ante esto comencé con el primer diseño:
Como base no estaba mal, pero faltaban las patas y cubrir los huecos entre las teclas. Para ello se me ocurrió que podía utilizar una pieza que se añadiese por detrás.
Menos mal que se me ocurrió probar a imprimirla antes… ¡Menudo desastre! Se suponía que la parte delantera, que es la que queda hacia el fondo en la imagen, tenía unos huecos en donde la placa se introducía para quedar fijada; por desgracia, para imprimirlos hacía falta utilizar soportes, los cuales no había manera de quitar en una zona tan estrecha como una placa de circuito impreso. Ante esto, decidí probar un segundo diseño:
En este nuevo diseño, el bloque principal de la carcasa estaba compuesto por cuatro piezas en lugar de dos (a mayores hay dos piezas extra para hacer una pata que va de un extremo a otro). Las dos piezas traseras se imprimirían «planas», pero las delanteras, en donde estaba la ranura en donde encajaría la PCB, se imprimiría «hacia arriba», con el frontal apoyado en la cama. De esta manera se podían evitar los soportes.
Por desgracia, aún era demasiado complicado, pues la parte de la pata consumía muchísimo filamento y no era nada sencilla de montar. Además, la alineación de las cubiertas para las zonas entre las teclas era crítica, pues hay menos de un milímetro de margen: un error, por pequeño que sea, haría que las teclas rozasen o, peor aún, no pudiesen bajar… como de hecho me ocurrió.
Finalmente, tras darle muchas vueltas se me ocurrió que podía simplificarlo muchísimo si separaba las cubiertas de los huecos de la carcasa, de manera que fuesen piezas independientes. De aquí salió el diseño de arriba: las dos piezas traseras se imprimen rotadas 90 grados, mientras que las dos piezas delanteras se imprimen «tal cual», de manera que no hace falta ningún tipo de soporte. El diseño lo hice sin la base para ahorrar plástico, pues quería usar un trozo de lámina de polietileno recortada para abaratar costes y reducir el tiempo de impresión.
Las piezas para cubrir los huecos entre las teclas de función las imprimí aparte, con la intención de pegarlas directamente en la PCB. Esto no sólo simplificaba mucho el diseño, pues no había que hacer malabares para evitar tener que usar soportes, sino que, además, eliminaba completamente los problemas de falta de precisión:
El diseño tenía buena pinta, pero aún no me acababa de convencer, pues había que pegar cuatro piezas para construir la carcasa, lo que no era muy cómodo. Además, la idea de ahorrar costes utilizando una lámina de polietileno como base no resultó: para empezar, las ranuras que había en el diseño para que ésta encajase eran demasiado estrechas, algo que, además, dependería de la impresora en sí. Pero además, si quería que las piezas se imprimiesen bien, no me quedaba más remedio que imprimir una «balsa», con lo que el ahorro no era tal, pues al final estaba imprimiendo la base igual, sólo que la tiraba a la basura.
Finalmente, llegué al diseño actual, que es éste:
La carcasa en sí está compuesta por solo dos piezas, las cuales, además, son muy fáciles de pegar. La superficie principal de la base tiene un grosor de sólo 0,6 milímetros, lo que significa que se gasta la misma cantidad de filamento que si se utilizase una «balsa» con el diseño anterior; sin embargo, la resistencia es la misma, pues en los bordes el grosor aumenta para darle rigidez. Las patas se imprimen aparte y se pegan en el borde trasero. Esto tiene la ventaja de que es posible imprimir patas de distinta altura para ajustarlo a las preferencias de cada uno. Por último, las cubiertas se imprimen aparte, como se ve, y además hay tres piezas extra que también se pegan entre las teclas y que sirven como «tuercas» para atornillar la placa a la carcasa (aunque en los dos teclados que hice no fue necesario, pues quedaron perfectamente ajustadas).
En la entrada anterior expliqué cómo construí un pedal para tomar fotografías desde el móvil y así simplificar el documentar proyectos hardware. Por desgracia, cuando llegó el momento de usarlo por primera vez me encontré con un problema: resulta que la aplicación de cámara de Android se cierra automáticamente al cabo de dos minutos de no hacer nada con ella. Esto es un problema porque entre foto y foto bien puede pasar mucho más tiempo, lo que me obligaría a acercarme al móvil y lanzar la aplicación de nuevo. Esto no tiene nada que ver con el apagado automático de la pantalla: aunque le ponga media hora para que apague la pantalla, la aplicación de la cámara vuelve a la pantalla principal a los dos minutos de estar «sin hacer nada».
Obviamente esto es completamente inaceptable, así que decidí agarrar el toro por los cuernos y escribir una pequeña aplicación de cámara para Android que no tuviese este problema. Para ello partí de un ejemplo de cómo utilizar la cámara en Android, escrito en Kotlin. Reconozco que no es un mal lenguaje, pero no le acabo de pillar el punto (todo lo contrario que Go… pero esa es otra historia).
Tras una primera prueba, conseguí que funcionase de manera constante. Sin embargo, me encontré con la desagradable sorpresa de que el tener la cámara funcionando constantemente hace que el móvil se caliente un montón, cosa que no me hacía nada de gracia (de hecho, al buscar por qué la aplicación oficial de cámara se cerraba a los dos minutos, uno de los motivos que decía era ese; me parecía muy extraño, teniendo en cuenta que sí puedes grabar vídeo durante más tiempo, pero visto lo visto, podría ser una de las razones).
Ante esto, tuve que complicar un poco la aplicación, haciendo que la cámara se desactive al cabo de un tiempo sin hacer nada, pero dejando la aplicación en primer plano y activando de nuevo la cámara tan pronto se pulsa uno de los botones de volumen para tomar una foto. De esta manera el móvil no se recalienta.
Como comienzo no estuvo mal, pero claramente tenía un problema: ¿cómo puedo saber si una foto es buena, o tengo que repetirla? La solución fue relativamente sencilla: añadir la posibilidad de enviar cada foto tomada a mi portátil, que estaría en un sitio donde podría ver fácilmente el resultado. Así, añadí dos campos de texto en la app en los que teclear la dirección IP del portátil y un puerto (por defecto usa el 9000), y en éste correr una pequeña aplicación en python que se limite a escuchar por dicho puerto, y cuando se abra, recibir los datos de la imagen en formato JPEG, descomprimirlos, y mostrarlos en la pantalla.
El resultado era bastante bueno, pero tenía un problema aún: la cámara de mi móvil es de 4160×3120 pixels, un tamaño exageradamente grande que resulta en ficheros muy grandes. El resultado es que entre que pulso el pedal y aparece la foto en el portátil pasan unos nueve segundos (tres de los cuales son debidos a tener que encender la cámara). Para resolverlo añadí un campo de «resolución», que permite poner un tamaño deseado (yo le pongo 2048), de manera que el móvil escogerá la resolución más cercana a ese valor entre los que permita la cámara. Con esto, el tiempo baja a cuatro segundos si la cámara estaba apagada, y un segundo si la cámara estaba encendida (por ejemplo si no nos gusta la foto y decidimos sacar otra, la cámara estará ya encendida y será muchísimo más rápido).
El código fuente (compilable con Android Studio) está disponible en mi repositorio GIT: https://gitlab.com/rastersoft/footcam. Hay un paquete APK para Android ya compilado que se puede descargar desde la sección Tags, simplemente pinchando en el número de versión. En el repositorio principal se puede descargar el programa de visualización remota, llamado «receiver.py«. Para utilizarlo, además de Python3 es necesario WxPython.
Utilizamos cookies para garantizar que tenga la mejor experiencia en nuestro sitio web.