Hace un par de años me compré un Slimbook ProX, ordenador con el que estoy muy contento. Sin embargo, de un tiempo a esta parte me he encontrado con que no se apaga: le doy la orden de «Apagar» en Gnome Shell, el sistema hace todo lo que tiene que hacer (detener procesos, sincronizar unidades… todo), y, finalmente, apaga los dispositivos y la pantalla. Peeeero… el LED de encendido y el ventilador se quedan encendidos. Literalmente hace todo el proceso, excepto «cortar la corriente».
Lo comenté en los foros, pero nadie encontraba una solución, así que me lié la manta a la cabeza y decidí intentar depurar el kernel enviando todos los mensajes a un puerto serie, para ver si había alguno que se mostraba después de haber desactivado el registro (y, por tanto, no quedaría grabado en disco para poder leerlo en el siguiente arranque), y después de que se hubiese desactivado el driver de la tarjeta gráfica y, por tanto, no se pudiese leer en pantalla.
Tras muuuuuchas pruebas y errores, descubrí que para que funcionase el arranque cuando enviaba la salida del kernel a un puerto serie era necesario desactivar el splash, la pantalla que se muestra durante el arranque. Pero si lo hacía… ¡¡¡el apagado volvía a funcionar!!! Seguí haciendo pruebas y, finalmente, cuando vi que, efectivamente, era suficiente con quitar el splash o el quiet de los parámetros de GRUB, lo comenté en los foros. Pero resulta que el servicio técnico ya lo había descubierto también un par de días antes, y que todo apuntaba a un kernel panic producido por una condición de carrera en el driver gráfico de AMD. Eso significaba que la solución no era tal, sino que en cualquier momento podía fallar de nuevo.
Además, un usuario comentó que había unos cuantos comentarios en las listas de freedesktop sobre un parche que se había añadido en el kernel 6.14 (con el que empezaron mis problemas) que producía un kernel panic en algunos casos, lo que parecía apuntar a que ese commit, el 0a9906cc45d21e21ca8bb2b98b79fd7c05420fda, era el responsable.
Ante esto, decidí probar a compilar un kernel sin dicho parche, a ver qué pasaba, y parece que, efectivamente, resuelve el problema. Mi intención era crear un PPA con él, pero por circunstancias, no puedo, así que voy a poner aquí las instrucciones sobre cómo hacerlo uno mismo, junto con un script que simplificará el proceso para aquellos que no tengan demasiados conocimientos.
TLDR; En primer lugar pondré la manera sencilla de hacerlo, para aquellos que no necesiten detalles y simplemente quieran resolver el problema y ya.
Para ello, bajamos el siguiente script, que automatiza todo el proceso de descarga del kernel, parcheado, compilación y empaquetado. Si prefieres copiarlo y pegarlo en un fichero manualmente, éste es su contenido:
#!/bin/sh
set -e
sudo sed -i 's/deb$/deb deb-src/g' /etc/apt/sources.list.d/ubuntu.sources
sudo apt update
sudo apt build-dep linux linux-image-unsigned-$(uname -r)
sudo apt install libncurses-dev gawk flex bison openssl libssl-dev dkms libelf-dev libudev-dev libpci-dev libiberty-dev autoconf llvm
rm -rf kernel-patch
mkdir kernel-patch
cd kernel-patch
apt source linux-image-unsigned-6.17.0-5-generic
cat <<EOF >patch.diff
--- linux-6.17.0/drivers/gpu/drm/amd/display/dc/core/dc.c 2025-09-15 13:53:57.000000000 +0200
+++ ../kernel_shutdown_failure/linux-6.17.0/drivers/gpu/drm/amd/display/dc/core/dc.c 2025-10-18 23:29:10.918224279 +0200
@@ -5416,26 +5416,11 @@
return true;
}
-static void clear_update_flags(struct dc_surface_update *srf_updates,
- int surface_count, struct dc_stream_state *stream)
-{
- int i;
-
- if (stream)
- stream->update_flags.raw = 0;
-
- for (i = 0; i < surface_count; i++)
- if (srf_updates[i].surface)
- srf_updates[i].surface->update_flags.raw = 0;
-}
-
bool dc_update_planes_and_stream(struct dc *dc,
struct dc_surface_update *srf_updates, int surface_count,
struct dc_stream_state *stream,
struct dc_stream_update *stream_update)
{
- bool ret = false;
-
dc_exit_ips_for_hw_access(dc);
/*
* update planes and stream version 3 separates FULL and FAST updates
@@ -5452,16 +5437,10 @@
* features as they are now transparent to the new sequence.
*/
if (dc->ctx->dce_version >= DCN_VERSION_4_01)
- ret = update_planes_and_stream_v3(dc, srf_updates,
+ return update_planes_and_stream_v3(dc, srf_updates,
surface_count, stream, stream_update);
- else
- ret = update_planes_and_stream_v2(dc, srf_updates,
+ return update_planes_and_stream_v2(dc, srf_updates,
surface_count, stream, stream_update);
- if (ret && (dc->ctx->dce_version >= DCN_VERSION_3_2 ||
- dc->ctx->dce_version == DCN_VERSION_3_01))
- clear_update_flags(srf_updates, surface_count, stream);
-
- return ret;
}
void dc_commit_updates_for_stream(struct dc *dc,
@@ -5471,8 +5450,6 @@
struct dc_stream_update *stream_update,
struct dc_state *state)
{
- bool ret = false;
-
dc_exit_ips_for_hw_access(dc);
/* TODO: Since change commit sequence can have a huge impact,
* we decided to only enable it for DCN3x. However, as soon as
@@ -5480,17 +5457,17 @@
* the new sequence for all ASICs.
*/
if (dc->ctx->dce_version >= DCN_VERSION_4_01) {
- ret = update_planes_and_stream_v3(dc, srf_updates, surface_count,
+ update_planes_and_stream_v3(dc, srf_updates, surface_count,
stream, stream_update);
- } else if (dc->ctx->dce_version >= DCN_VERSION_3_2) {
- ret = update_planes_and_stream_v2(dc, srf_updates, surface_count,
+ return;
+ }
+ if (dc->ctx->dce_version >= DCN_VERSION_3_2) {
+ update_planes_and_stream_v2(dc, srf_updates, surface_count,
stream, stream_update);
- } else
- ret = update_planes_and_stream_v1(dc, srf_updates, surface_count, stream,
+ return;
+ }
+ update_planes_and_stream_v1(dc, srf_updates, surface_count, stream,
stream_update, state);
-
- if (ret && dc->ctx->dce_version >= DCN_VERSION_3_2)
- clear_update_flags(srf_updates, surface_count, stream);
}
uint8_t dc_get_current_stream_count(struct dc *dc)
EOF
cd linux-6.17.0
patch -p1 < ../patch.diff
fakeroot debian/rules clean
fakeroot debian/rules binary-headers binary-generic binary-perarch
Ahora tenemos que darle permisos de ejecución y lanzarlo en un terminal. Si no sabes hacerlo, simplemente sigue estos pasos. Abre la carpeta donde has guardado el script y abre las propiedades del fichero:
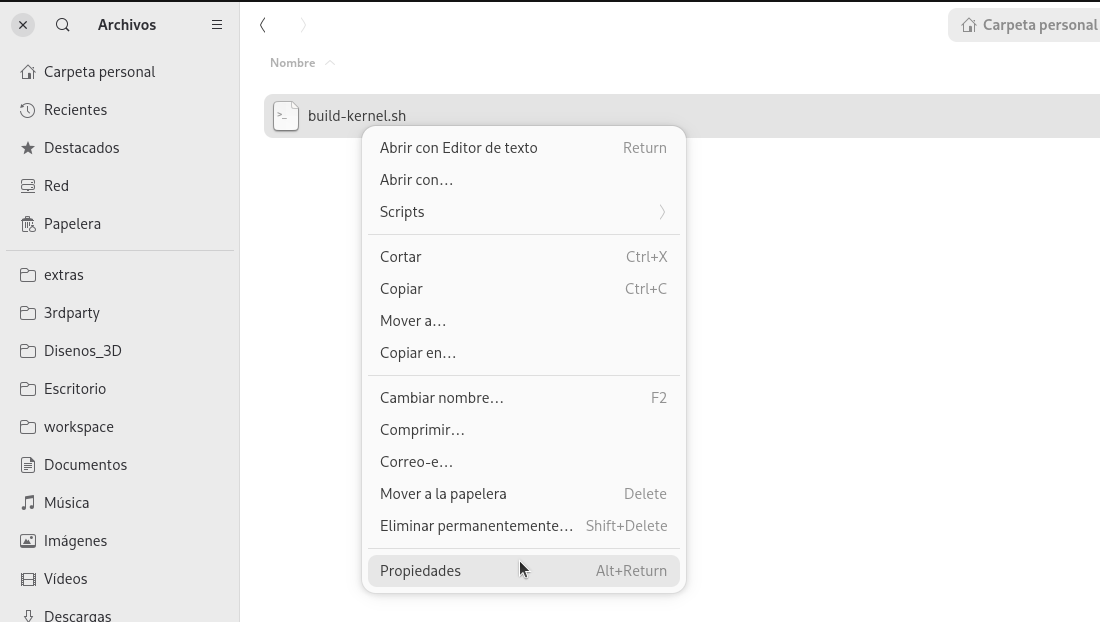
Ahí, activar la opción de «Ejecutable como un programa»
Y, finalmente, lánzalo:
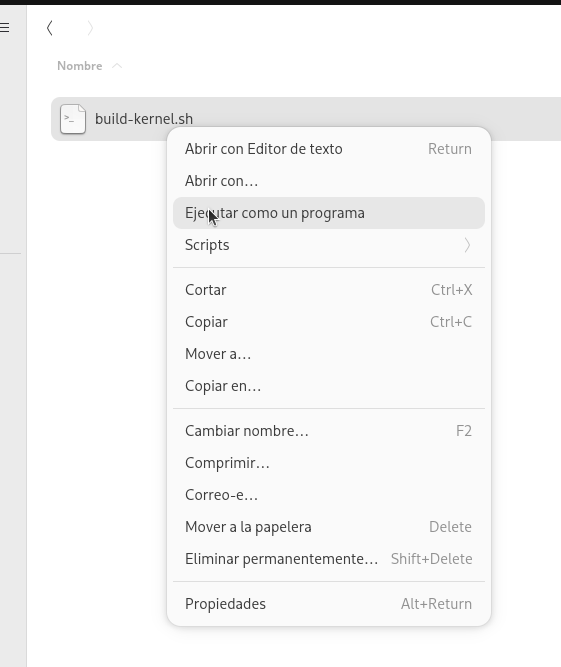
Se abrirá un terminal y procederá a instalar los paquetes necesarios para compilar el kernel (nos pedirá la clave), aplicará el parche, y compilará todo. Eso sí, el proceso tarda más de una hora, así que podéis iros a tomar un café, ver un par de capítulos de vuestra serie favorita…
Cuando haya terminado, tendrás en la carpeta kernel una serie de paquetes .deb con el kernel, los módulos, etc. Instala la imagen del kernel en sí (esto es, linux-image-unsigned-6.17.0-5-generic_6.17.0-5.5_amd64.deb) y el paquete de módulos (linux-modules-6.17.0-5-generic_6.17.0-5.5_amd64.deb).
Una vez hecho, reinicia y todo debería funcionar.