Estos días estoy haciendo un pequeño proyecto con un Arduino UNO, y me he encontrado con que el puerto serie no funciona correctamente a velocidades mayores de 57 600 baudios: cada vez que intentaba utilizar 115 200 baudios, mi terminal recibía basura.
Tras mucho investigar, descubrí que el problema es debido a que la UART del Atmega 328P que lleva el Arduino UNO utiliza el mismo reloj externo de 16MHz, pero toma 16 muestras de cada bit, por lo que la velocidad efectiva es 1MHz. Esa frecuencia es la que se divide para obtener la velocidad de transmisión/recepción deseada, y aquí es donde viene el problema: la fórmula para obtener el divisor que hay que programar en el registro del Atmega es, en el caso de un reloj externo de 16MHz como en el Arduino Uno, (16 000 000 / 16·baudios) – 1, y si calculamos el valor para 115 200, el resultado es 7,68… que no es un número entero, con lo que el divisor real será 7. Eso significa que la velocidad real del puerto serie es de 125 000 baudios. Tenemos un error de casi un 9%, que es mucho para un puerto serie. Para velocidades inferiores el error es menor; por ejemplo, para 57 600 tenemos que el valor es 16,36, con lo que la velocidad real es 58 823, y el error es de aproximadamente un 2%, más que aceptable para un puerto serie.
Podríamos pensar «Bueno, pero si la UART a la que está conectada también utiliza un reloj de 1MHz, el error será el mismo y debería funcionar». Y así es… salvo por el detalle de que no es el caso. El Arduino original era una placa diseñada para conectarse directamente al puerto serie de un PC, pero con la desaparición de éstos a manos del puerto USB, el fabricante decidió añadir un conversor USB<->serie directamente en la placa, específicamente el FT232. Si nos fijamos en el esquema interno que viene en su datasheet, vemos que la UART utiliza el mismo reloj que el subsistema USB, que es de 48MHz. También en el datasheet vemos que el divisor de la UART ofrece un reloj con una frecuencia 16 veces superior a la deseada; pero dado que parte de una frecuencia tres veces superior, la precisión es mucho mayor. En concreto, para 115 200, la velocidad real es 115 385 baudios. Esto explica por qué no es capaz de comunicarse a esa velocidad con el microcontrolador: la diferencia es demasiada.
¿Y cómo solucionamos este problema? Simple: calculamos la velocidad real a la que está trabajando el sistema de menos precisión (Atmega), y utilizamos esa velocidad en el sistema de más precisión (FT232). Para ello, utilizamos la función:
Así, si ponemos el Atmega a 115 200 baudios, la velocidad real será 125 000 baudios. Poniendo 125 000 baudios en el FT232 la velocidad real será… ¡125 000 baudios también! Lo que tiene sentido, porque la frecuencia de reloj del FT232 es un múltiplo entero de la del Atmega.
Con este método he podido aumentar la velocidad del puerto serie hasta 500 000 baudios sin problemas.
Hace un par de años me compré un Slimbook ProX, ordenador con el que estoy muy contento. Sin embargo, de un tiempo a esta parte me he encontrado con que no se apaga: le doy la orden de «Apagar» en Gnome Shell, el sistema hace todo lo que tiene que hacer (detener procesos, sincronizar unidades… todo), y, finalmente, apaga los dispositivos y la pantalla. Peeeero… el LED de encendido y el ventilador se quedan encendidos. Literalmente hace todo el proceso, excepto «cortar la corriente».
Lo comenté en los foros, pero nadie encontraba una solución, así que me lié la manta a la cabeza y decidí intentar depurar el kernel enviando todos los mensajes a un puerto serie, para ver si había alguno que se mostraba después de haber desactivado el registro (y, por tanto, no quedaría grabado en disco para poder leerlo en el siguiente arranque), y después de que se hubiese desactivado el driver de la tarjeta gráfica y, por tanto, no se pudiese leer en pantalla.
Tras muuuuuchas pruebas y errores, descubrí que para que funcionase el arranque cuando enviaba la salida del kernel a un puerto serie era necesario desactivar el splash, la pantalla que se muestra durante el arranque. Pero si lo hacía… ¡¡¡el apagado volvía a funcionar!!! Seguí haciendo pruebas y, finalmente, cuando vi que, efectivamente, era suficiente con quitar el splash o el quiet de los parámetros de GRUB, lo comenté en los foros. Pero resulta que el servicio técnico ya lo había descubierto también un par de días antes, y que todo apuntaba a un kernel panic producido por una condición de carrera en el driver gráfico de AMD. Eso significaba que la solución no era tal, sino que en cualquier momento podía fallar de nuevo.
Ante esto, decidí probar a compilar un kernel sin dicho parche, a ver qué pasaba, y parece que, efectivamente, resuelve el problema. Mi intención era crear un PPA con él, pero por circunstancias, no puedo, así que voy a poner aquí las instrucciones sobre cómo hacerlo uno mismo, junto con un script que simplificará el proceso para aquellos que no tengan demasiados conocimientos.
TLDR; En primer lugar pondré la manera sencilla de hacerlo, para aquellos que no necesiten detalles y simplemente quieran resolver el problema y ya.
Para ello, bajamos el siguiente script, que automatiza todo el proceso de descarga del kernel, parcheado, compilación y empaquetado. Si prefieres copiarlo y pegarlo en un fichero manualmente, éste es su contenido:
#!/bin/sh
set -e
sudo sed -i 's/deb$/deb deb-src/g' /etc/apt/sources.list.d/ubuntu.sources
Ahora tenemos que darle permisos de ejecución y lanzarlo en un terminal. Si no sabes hacerlo, simplemente sigue estos pasos. Abre la carpeta donde has guardado el script y abre las propiedades del fichero:
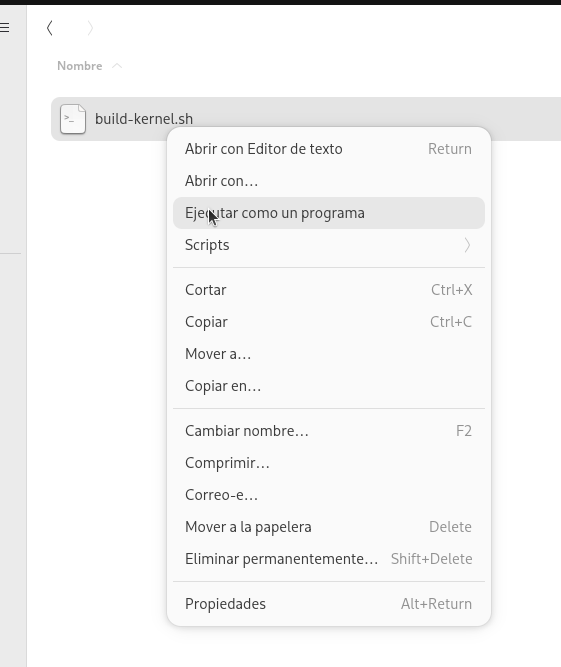
Ahí, activar la opción de «Ejecutable como un programa»
Y, finalmente, lánzalo:
Se abrirá un terminal y procederá a instalar los paquetes necesarios para compilar el kernel (nos pedirá la clave), aplicará el parche, y compilará todo. Eso sí, el proceso tarda más de una hora, así que podéis iros a tomar un café, ver un par de capítulos de vuestra serie favorita…
Cuando haya terminado, tendrás en la carpeta kernel una serie de paquetes .deb con el kernel, los módulos, etc. Instala la imagen del kernel en sí (esto es, linux-image-unsigned-6.17.0-5-generic_6.17.0-5.5_amd64.deb) y el paquete de módulos (linux-modules-6.17.0-5-generic_6.17.0-5.5_amd64.deb).
Recientemente descubrí un bug en la versión de la biblioteca libsoup de Raspbian y, por extensión, de Debian Bookworm: si tenemos un servidor hecho con dicha biblioteca, cuando el cliente cierra una conexión, el servidor no cierra el socket. El resultado es que éste se queda en estado CLOSE_WAIT para siempre (o, al menos, hasta que se reinicie el servidor), con lo que poco a poco se van consumiendo los posibles File Descriptors hasta que llega un momento en el que ya no se pueden realizar ni aceptar más conexiones. Este bug está en la versión 3.2.2, que es la que lleva Debian Estable, pero fue corregido en la versión 3.3.0.
Lo primero que hice fue notificar el bug a Debian, indicando además el commit con el parche que lo soluciona. Pero dado que no sabía cuanto tiempo iban a tardar en aplicarlo, decidí buscar una solución.
Lo primero que pensé fue en utilizar pinning para instalar la versión 3.6.1 disponible en testing; por desgracia, la actualización me obligaba a actualizar un montón más de paquetes, y no me quería arriesgar a romper algo en mi Raspberry Pi.
La segunda opción, que fue la que utilicé, consistió en compilar desde las fuentes la última versión de libsoup e instalarla en /usr/local. Dado que este directorio tiene más prioridad que /usr, se cogería primero mi versión.
Lo que hice fue bajar el repositorio, cambiar a la versión, configurar el proyecto con meson, compilarlo e instalarlo con ninja, y reconstruir la caché de bibliotecas:
Hace tiempo escribí un artículo sobre cómo hice un cargador «inalámbrico» para mis cascos bluetooth, que me permitía cargarlos simplemente colgándolos del soporte. Tras todo este tiempo, esos viejos cascos (que eran un apaño que hice juntando unos cutres bluetooth con unos decentillos de cable) han llegado al final de su vida útil, así que me compré unos nuevos. Y, obviamente, los he adaptado para poder cargarlos igual. Así han quedado:
Lo primero que tuve que hacer fue modificar el soporte original, pues el ancho de la diadema era menor. Ya aproveché y lo hice paramétrico, de manera que poniendo el ancho de la diadema en la hoja de cálculo, automáticamente crea el bloque con el tamaño adecuado para que los contactos estén tres milímetros más cerca.
Una vez hecho el soporte, tocó cubrir las lengüetas con cinta de cobre y conectar el transformador.
Tras montarlo, me fijé que podía tener problemas de contacto, así que añadí más cinta de cobre de manera que ésta llegase hasta los bordes de las lengüetas.
Ahora tenía que hacer la conversión de mis cascos. Por motivos obvios, esta vez no quería desmontarlos ni manipularlos, así que decidí hacer un sistema «externo», que además fuese sencillo de transportar a otros cascos en el futuro.
Empecemos por recordar el esquema del sistema:
Este es el esquema original: en el soporte tendremos entre 9 y 12 voltios en continua. Dicha tensión pasará por un puente rectificador para que no importe en qué sentido colgamos los cascos. La salida del puente tendrá, debido a la caída de tensión en los diodos, 1,4 voltios menos (o sea, entre 7,6 y 10,6 voltios), pero sigue siendo demasiada para nuestros cascos, así que añadimos un regulador de tensión conmutado para bajarla a los cinco voltios que necesitamos. Estos cinco voltios irán a un conector USB-C estándar, que se enchufará al conector de carga de mis cascos.
Lo primero que hice fue soldar el puente de diodos al regulador:
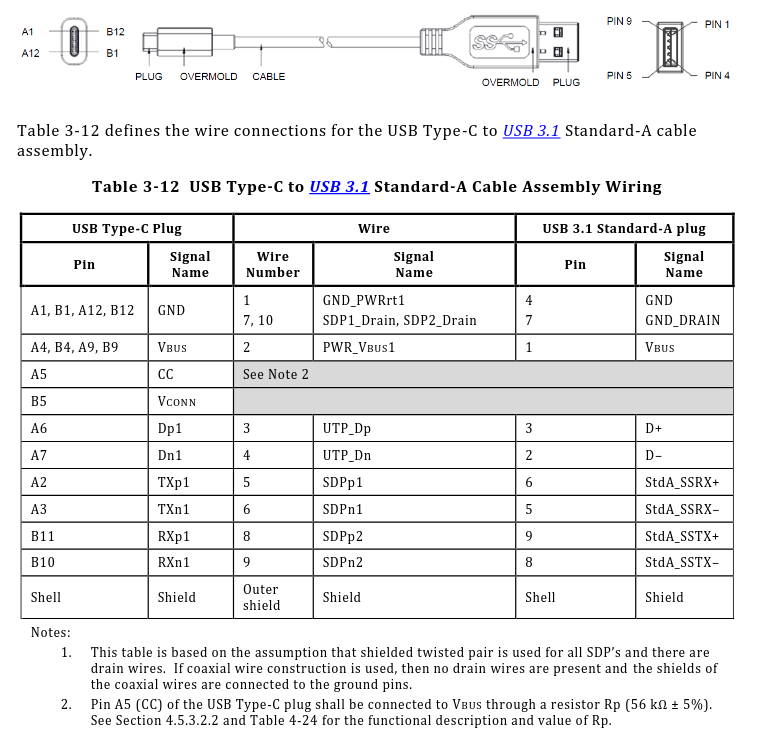
Una vez hecho esto, corté un cable USB-A a USB-C, quedándome con la parte del conector USB-C, y lo conecté a la salida del regulador. Esta era la opción más simple, pues, tal y como indica el estándar en la página 77, para que un conector USB-C pueda cargar algo, es imperativo que tenga, como mínimo, una resistencia de 56Kohm entre el pin A5 (CC) y alimentación, de manera que el dispositivo (en este caso nuestros cascos) sepa que puede alimentarse de él. Los cables USB-A a USB-C ya traen esta resistencia, por lo que eso que nos ahorramos. No recomiendo usar un cable USB-C a USB-C, pues tendríamos que añadir nosotros la resistencia, y, honestamente, no compensa.
También conecté dos cables a la entrada del puente rectificador, cables que, posteriormente, soldaré a las láminas de los cascos.
El siguiente paso fue hacer una cajita donde meter esto. ¡Bendita impresión 3D!
Llegó el momento de modificar los cascos. Lo primero fue pegar la cinta de cobre en la diadema, de manera que queden dos contactos para la carga. Para ello, primero la pegué en la parte superior, dejando un buen margen de cinta:
Tras ello, hice varios cortes transversales para poder doblar la cinta sobre el borde de la diadema, y que de esta forma quede una buena zona de contacto para el soporte.
Repetí el proceso en el lado opuesto, y así conseguí los dos contactos de la diadema. Una vez hecho esto, metí el circuito dentro de la caja y la pegué en el auricular derecho, donde está el conector.
Procedí a soldar los dos cables a las dos tiras de cobre de la diadema…
Y protegí el conjunto con un poco de cinta aislante del mismo color que los cascos, además de conectar el cable USB-C al conector de carga.
¡Y ya está! Mis nuevos cascos ya se cargan sólo con colgarlos del soporte.
Hace tiempo hice un programita para la Raspberry Pi 3 que utilizaba la biblioteca lg para realizar E/S desde C. Por desgracia, cuando intenté hacerla funcionar en una Raspberry Pi 5, no funcionó. Tras muchas pruebas y buscar documentación, descubrí que la clave estaba en la llamada de inicialización a lgGpioChipOpen(): en una RPi 1, 2, 3 o 4, el valor que hay que pasarle es 0, para que abra /dev/gpiochip0, pero en una RPi 5 hay que pasar el valor 4.
Un truco para saber programáticamente en qué modelo estamos consiste en leer /sys/firmware/devicetree/base/model. En mi Raspberry Pi 5 devuelve la cadena Raspberry Pi 5 Model B Rev 1.0. En una RPi 4 que tengo, devuelve Raspberry Pi 4 Model B Rev 1.1.
La Raspberry Pi lleva desde su primera versión un conector DSI que permite conectar una pantalla táctil directamente, alimentándose desde la misma placa y todo a través de un único cable.
Por desgracia, este conector cambió en la versión 5, y ahora tiene dos (que valen tanto para pantallas como para cámaras), pero más pequeños que el original, con lo que los viejos cables no sirven y hay que comprar uno específico.
Eso hice, pero todos los que encontré tienen un problema: las pistas de ambos conectores están hacia el mismo lado, pero los nuevos conectores están «al revés», así que me encontré con que la única manera de conectar la pantalla implica, o retorcer 180 grados el cable…
… o colocar la RPi5 boca abajo…
Y por desgracia, tampoco servía ponerla «de delante hacia atrás», porque el conector de la pantalla quedaba justo debajo:
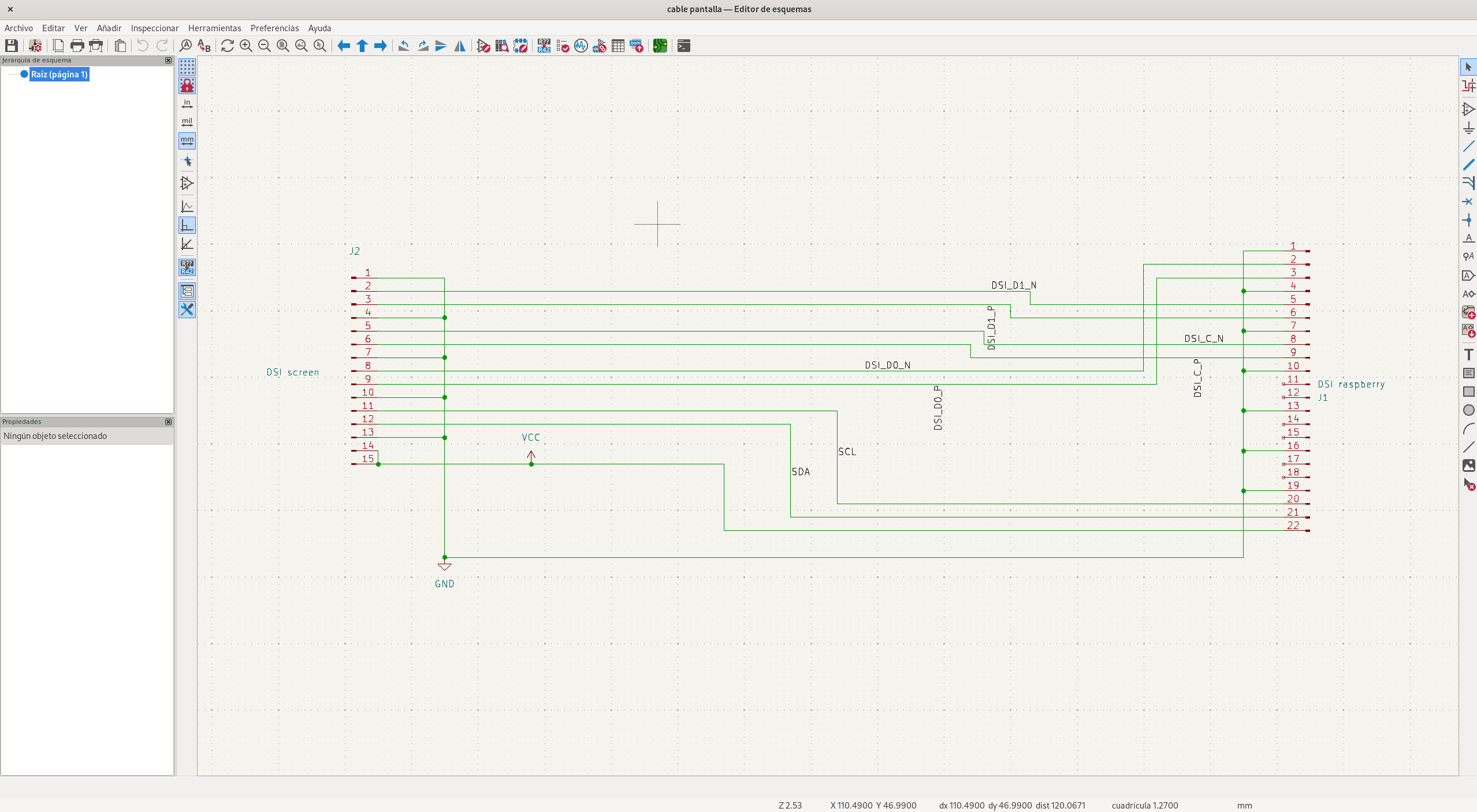
Ante esto, decidí liarme la manta a la cabeza y diseñar mi propio cable de conexión para la RPi5, así que cogí Kicad y empecé por diseñar el esquemático que necesitaba:
Básicamente hay que conectar alimentación y las distintas masas, las dos señales (SCL y SDA) del bus I2C para la pantalla táctil, y los tres pares diferenciales de la señal DSI (uno de reloj, DSI_C_x, y dos de datos, DSI_Dy_x). Las señales para el conector DSI de la pantalla las saqué a partir del conector de la Raspberry Pi 4. El pinout del conector de la RPi5 fue un poco más complicado de encontrar, pero al final apareció.
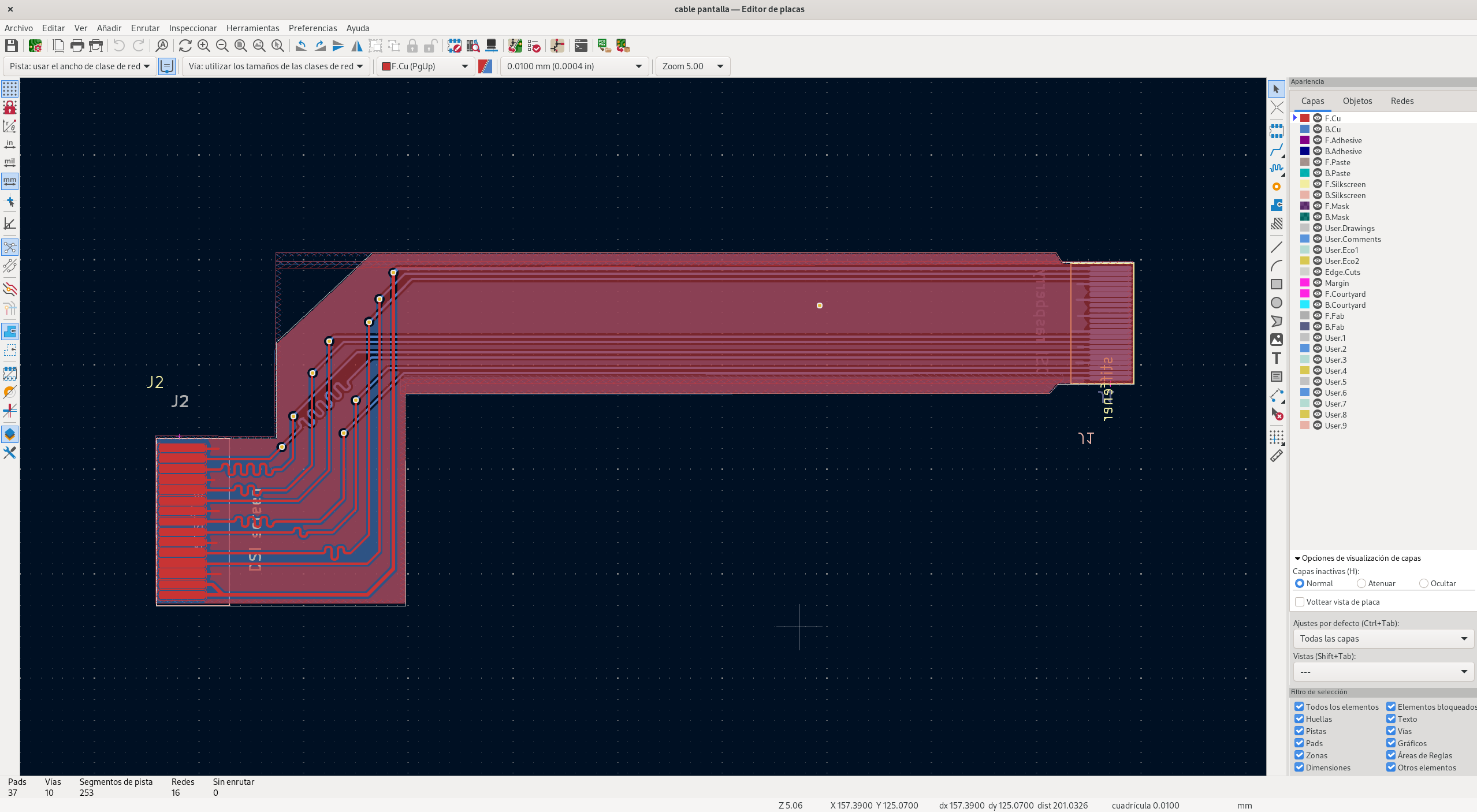
Tras ello, me fui al editor de placas y diseñé esto:
Un detalle importante fue asegurarse de que la longitud de los tres pares fuese la misma, para garantizar que las señales lleguen sincronizadas (no hay que olvidar que la señal de reloj utiliza un par propio). Para ello, seleccionando una pista, Kicad no sólo nos dice la longitud del segmento seleccionado, sino también la longitud total. Una vez encontrada la pista más larga, vamos al resto y utilizamos la herramienta de afinado de longitud, que tiene este icono:
para ir ajustando la longitud de cada una, de manera que midan lo mismo. Cabe recordar que una vez trazado el «gusanito», es posible ajustar el ancho, de manera que si no conseguimos a la primera la longitud correcta, debemos dejarlo más largo y luego reducir el ancho.
Si nos fijamos, también lo hice con el I2C, aunque en este caso no era realmente necesario, pues la velocidad es muy baja.
Idealmente, además, debería haber ajustado la separación de los pares de pistas para mantener la impedancia correcta; por desgracia, DSI es una especificación cerrada, por lo que no tenía acceso a esa información. Afortunadamente, todo funcionó a la primera.
A la hora de mandarlo fabricar, tuve que especificar que lo quería como una placa flexible, y además indicar que quiero que incluya stiffeners (las «pegatinas» que se ponen en la cara opuesta de cada conector para darle rigidez y que no se rompan).
Y este es el resultado: un cable que se adapta perfectamente a la RPi5 y la pantalla, sin dobleces ni cosas raras, y dejando completamente libre la zona superior del procesador y memoria para poder poner un disipador y ventilador.
Los esquemáticos están disponibles bajo una licencia MIT (vamos, que puedes usarlo con libertad) en mi repositorio de Gitlab.
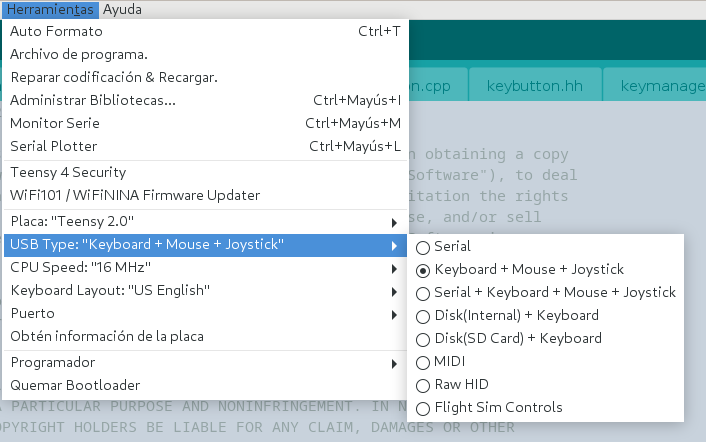
He empezado a añadir funcionalidades extra a mi teclado. En concreto, controles multimedia (volumen, etc). Y ya he encontrado un bug raro: sólo funcionan si la placa está en modo «keyboard+mouse+joystick», pero no en modo «serial+keyboard+mouse+joystick».
Las placas Teensy se pueden poner en varios modos desde el entorno de Arduino. Aquí los podemos ver:
Lo normal es utilizar el modo «Keyboard + Mouse + Joystick» para productos finales, y el modo «Serial + Keyboard + Mouse + Joystick» para depuración, pues podemos enviar texto a la consola. Sin embargo, por algún motivo, si la placa está en este último modo, los códigos de las teclas multimedia (KEY_MEDIA_VOLUME_INC, KEY_MEDIA_VOLUME_DEC, etc) no funcionan: no se recibe absolutamente nada (y lo he comprobado leyendo directamente de /dev/input/eventXX).
Después de muchos años, Terminus acaba de llegar a la versión 2.0. Y no ha sido «porque sí», sino porque ahora incorpora una nueva funcionalidad que creo que lo convierte en aún más útil: Drag’n’Drop.
Ahora es posible arrastrar un terminal agarrándolo por la barra superior (la que se pone roja cuando el terminal tiene el foco), y cambiarlo de sitio, bien dentro de la misma pestaña, en otra pestaña de la misma ventana o de otra ventana, en una nueva pestaña de la misma ventana o de otra ventana, o incluso en una nueva ventana. Esta característica permitirá evitar el «arrepentirse» de estar ejecutando algo en otra pestaña cuando ahora vendría mejor tenerlo junto a ese otro terminal; o si tenemos algo en la ventana tipo «Guake» y nos interesaría tenerlo en una ventana independiente, etc.
A mayores incorpora alguna que otra característica nueva, como permitir configurar el auto-ocultamiento del cursor. Así, si está activo, al teclear cualquier cosa, el cursor del ratón desaparecerá (y así no molesta), apareciendo de nuevo tan pronto se mueva el ratón.
Como de costumbre, se puede descargar en mi página web.
¡¡Hace unos días me han llegado las placas de PCBWay!! Pero como estuve fuera, hasta hoy no he podido poner nada.
Se trata de la versión 1.17 del teclado, que frente al diseño 1.0 de los teclados que construí hasta ahora, tiene tres NeoPixels, huella para el protector ESD, correcciones de compatibilidad con Teensy, serigrafía en los pines de programación, y algunos otros detallitos menores (como el maravilloso recuadro blanco para escribir anotaciones). Y el acabado es, sencillamente, perfecto. ¡Un 10 para PCBWay!
Después de la experiencia que he tenido, creo que estos teclados los voy a construir con pulsadores Cherry «de verdad». Iré contando.
Una nueva entrada para comentar que PCBWay ha tenido la gentileza de patrocinar este proyecto, con lo que podré actualizar mis actuales teclados a la versión 1.13 de la placa, con sus tres NeoPixels y demás.
En cuanto lleguen, pondré algunas fotos de ellas.
Utilizamos cookies para garantizar que tenga la mejor experiencia en nuestro sitio web.