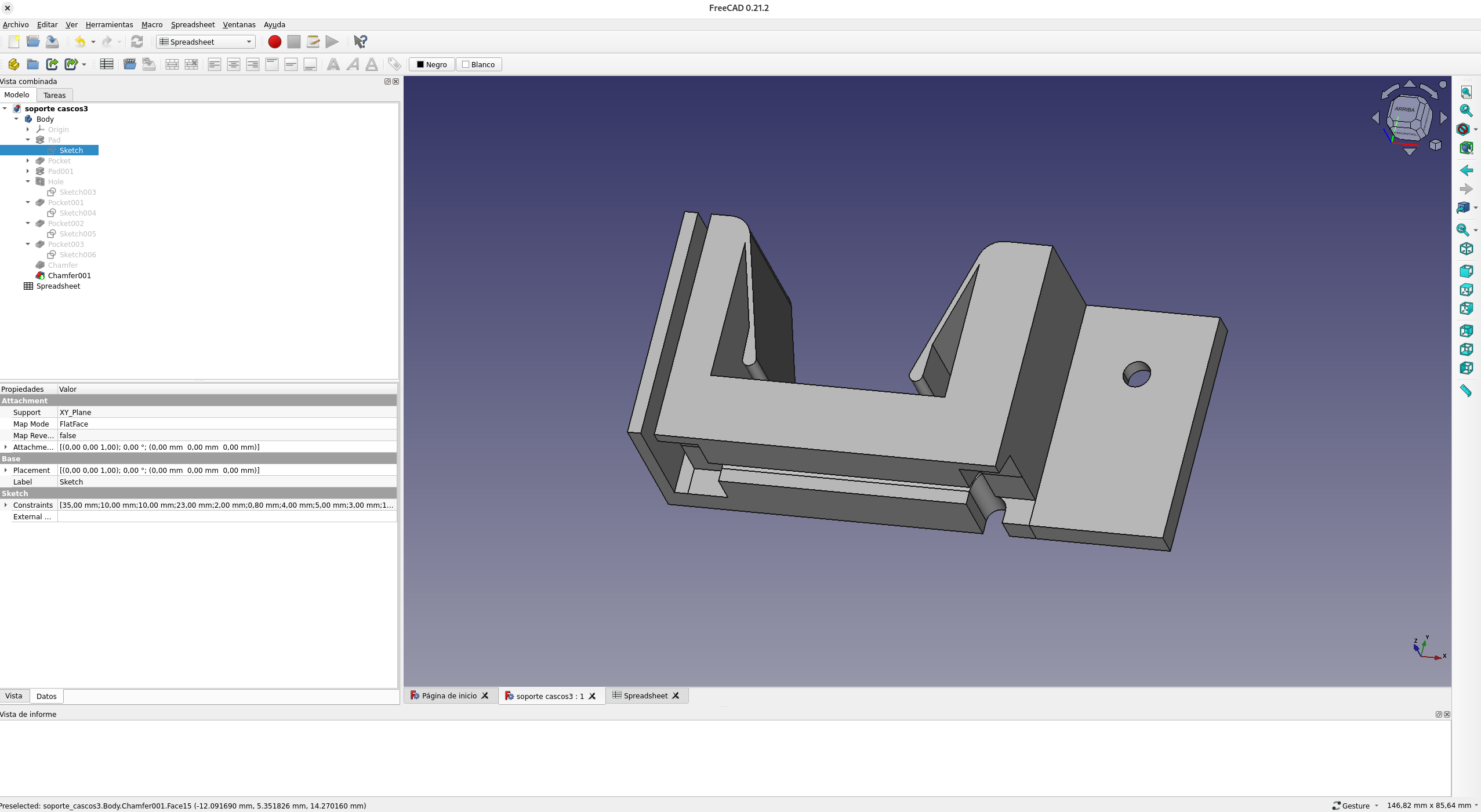
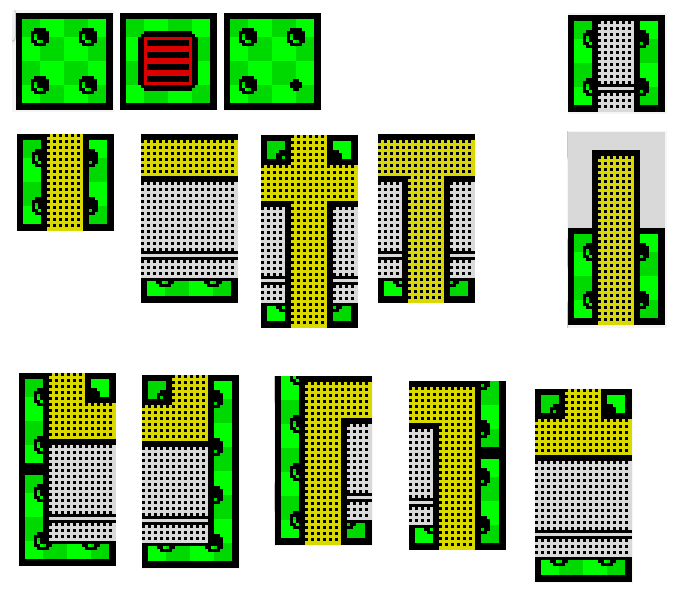
Hace tiempo escribí un artículo sobre cómo hice un cargador «inalámbrico» para mis cascos bluetooth, que me permitía cargarlos simplemente colgándolos del soporte. Tras todo este tiempo, esos viejos cascos (que eran un apaño que hice juntando unos cutres bluetooth con unos decentillos de cable) han llegado al final de su vida útil, así que me compré unos nuevos. Y, obviamente, los he adaptado para poder cargarlos igual. Así han quedado:
Lo primero que tuve que hacer fue modificar el soporte original, pues el ancho de la diadema era menor. Ya aproveché y lo hice paramétrico, de manera que poniendo el ancho de la diadema en la hoja de cálculo, automáticamente crea el bloque con el tamaño adecuado para que los contactos estén tres milímetros más cerca.
Una vez hecho el soporte, tocó cubrir las lengüetas con cinta de cobre y conectar el transformador.
Tras montarlo, me fijé que podía tener problemas de contacto, así que añadí más cinta de cobre de manera que ésta llegase hasta los bordes de las lengüetas.
Ahora tenía que hacer la conversión de mis cascos. Por motivos obvios, esta vez no quería desmontarlos ni manipularlos, así que decidí hacer un sistema «externo», que además fuese sencillo de transportar a otros cascos en el futuro.
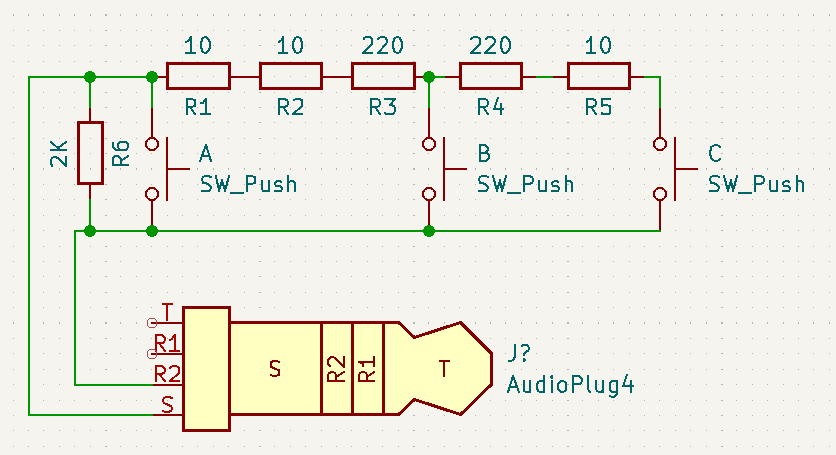
Empecemos por recordar el esquema del sistema:
Este es el esquema original: en el soporte tendremos entre 9 y 12 voltios en continua. Dicha tensión pasará por un puente rectificador para que no importe en qué sentido colgamos los cascos. La salida del puente tendrá, debido a la caída de tensión en los diodos, 1,4 voltios menos (o sea, entre 7,6 y 10,6 voltios), pero sigue siendo demasiada para nuestros cascos, así que añadimos un regulador de tensión conmutado para bajarla a los cinco voltios que necesitamos. Estos cinco voltios irán a un conector USB-C estándar, que se enchufará al conector de carga de mis cascos.
Lo primero que hice fue soldar el puente de diodos al regulador:
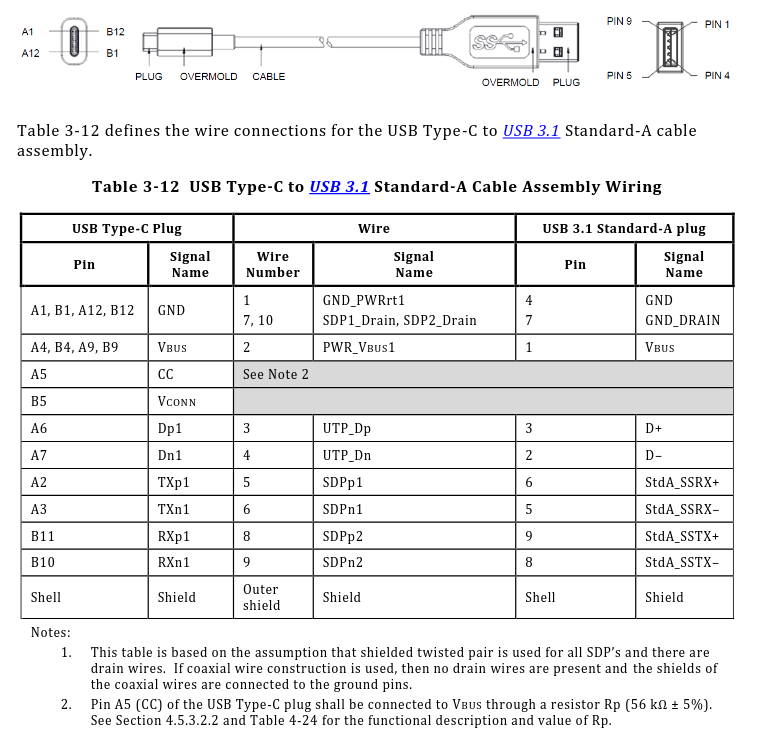
Una vez hecho esto, corté un cable USB-A a USB-C, quedándome con la parte del conector USB-C, y lo conecté a la salida del regulador. Esta era la opción más simple, pues, tal y como indica el estándar en la página 77, para que un conector USB-C pueda cargar algo, es imperativo que tenga, como mínimo, una resistencia de 56Kohm entre el pin A5 (CC) y alimentación, de manera que el dispositivo (en este caso nuestros cascos) sepa que puede alimentarse de él. Los cables USB-A a USB-C ya traen esta resistencia, por lo que eso que nos ahorramos. No recomiendo usar un cable USB-C a USB-C, pues tendríamos que añadir nosotros la resistencia, y, honestamente, no compensa.
También conecté dos cables a la entrada del puente rectificador, cables que, posteriormente, soldaré a las láminas de los cascos.
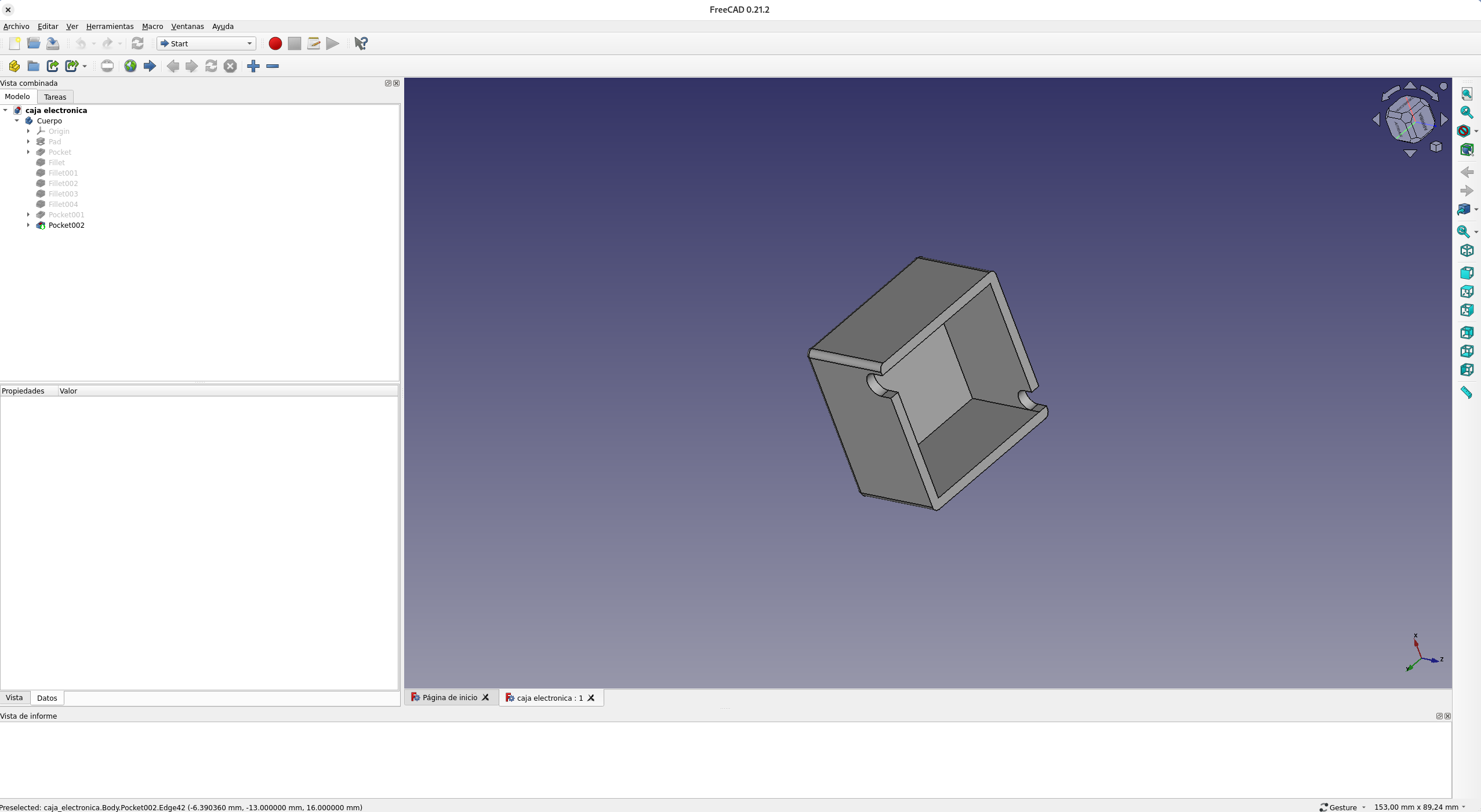
El siguiente paso fue hacer una cajita donde meter esto. ¡Bendita impresión 3D!
Llegó el momento de modificar los cascos. Lo primero fue pegar la cinta de cobre en la diadema, de manera que queden dos contactos para la carga. Para ello, primero la pegué en la parte superior, dejando un buen margen de cinta:
Tras ello, hice varios cortes transversales para poder doblar la cinta sobre el borde de la diadema, y que de esta forma quede una buena zona de contacto para el soporte.
Repetí el proceso en el lado opuesto, y así conseguí los dos contactos de la diadema. Una vez hecho esto, metí el circuito dentro de la caja y la pegué en el auricular derecho, donde está el conector.
Procedí a soldar los dos cables a las dos tiras de cobre de la diadema…
Y protegí el conjunto con un poco de cinta aislante del mismo color que los cascos, además de conectar el cable USB-C al conector de carga.
¡Y ya está! Mis nuevos cascos ya se cargan sólo con colgarlos del soporte.
Me gusta hacer proyectos de electrónica, pero documentarlos… ¡ay! Eso ya es otro cantar. A fin de cuentas, para ello tengo que decidir cuando sacar alguna foto, y eso me obliga a parar lo que estoy haciendo, sacar el móvil, encuadrar con una mano mientras con la otra sostengo lo que estoy haciendo… un cristo.
Pero a la vez tengo claro que quiero documentarlo, por un lado por mí, porque así tengo un registro de las cosas que he hecho y me puede servir en el futuro («¿Cómo había hecho aquello…?), y también porque puede ser útil para otras personas.
Tras darle varias vueltas, se me ocurrió una idea: dado que tengo un trípode con soporte para el móvil, podría montarlo y encuadrar una zona concreta de la mesa de trabajo, ya con luz adecuada y demás, y cada vez que quiera sacar una foto sólo tendría que pulsar un botón.
Por supuesto, queda la cuestión de cómo conectar ese botón, pero afortunadamente es algo que hace cualquier palo selfie que se precie, por lo que sólo tenía que conectarlo a la entrada de cascos. Rebusqué en internet y encontré las especificaciones oficiales 3.5 mm Headset: Accessory Specification y 3.5 mm Headset Jack: Device Specification. Estas dos especificaciones indican cómo se deben conectar los altavoces, micrófono y pulsadores en un móvil Android, y qué funcionalidad debe tener cada uno.
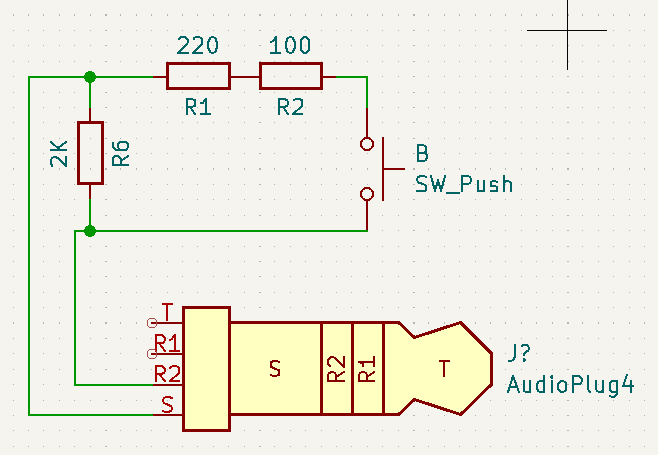
Una lectura rápida nos indica que los botones están conectados entre el terminal 3 y 4 del jack, en paralelo con el micrófono, y que las cuatro funcionalidades posibles se consiguen presentando un valor concreto de resistencia entre dichos terminales. Así, si aparecen 0 ohmios (o sea, si se cortocircuitan), la función es la A (play/pausa/descolgar si es una pulsación corta; asistente si es una pulsación larga, o siguiente canción si son dos pulsaciones cortas); con un valor de entre 210 y 290 ohmios la función será la B (subir volumen); un valor de entre 360 y 680 ohmios activará la función C (bajar volumen); por último, un valor entre 110 y 180 ohmios activará la función D, que es una funcionalidad «reservada». Dado que la cámara se puede activar con cualquiera de los botones de volumen, bastaba con poner una resistencia adecuada en serie con un pulsador entre los terminales 3 y 4 del jack y estaría listo.
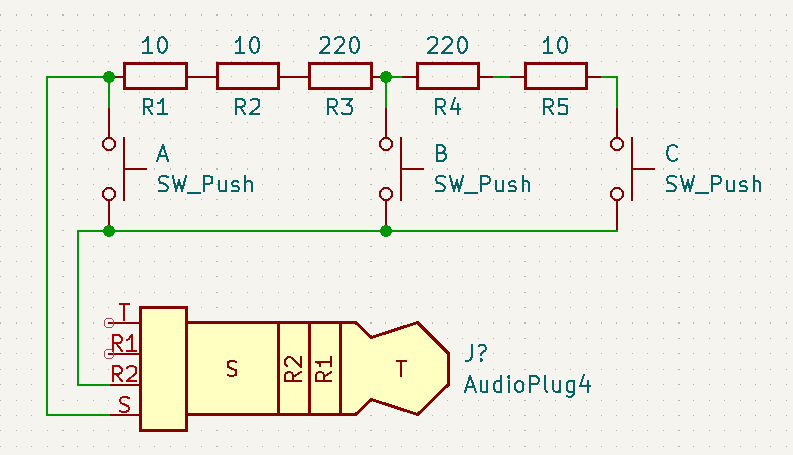
Decidí hacer una prueba rápida con un único botón, y para mi sorpresa… ¡¡¡no funcionó!!! Ante esto, decidí hacer un montaje un poco más completo con las funciones A, B y C:
Con los valores del esquema, el botón A cortocircuita los pines 3 y 4 del jack; el botón B muestra 240 ohmios, y el C 480 ohmios.
Y seguía sin funcionar: el móvil detectaba que había algo conectado, pero no hacía absolutamente nada: ni subir y bajar el volumen, ni responder a una llamada… ¡nada! Revisé los valores de resistencia con el polímetro, probé otros valores para activar otras funciones… pero nada, no quería funcionar. Era rarísimo.
Decidí buscar a gente que hubiese hecho un montaje similar y encontré un par de ejemplos documentados, pero ambos hacían exactamente lo mismo que yo.
Me releí una y otra vez la documentación, y entonces caí en un detalle: se indica que el micrófono tiene que tener una impedancia en continua superior a 1000 ohmios. Yo había dado por supuesto que podía dejarlo «desconectado», pues infinito es mayor que 1000 ohmios, pero, por si acaso, decidí poner en paralelo una resistencia de 2Kohmios, así:
¡Y ahora sí que funcionó! Está claro que al menos mi móvil espera que haya una cierta impedancia, y no un valor «infinito».
Con esto claro, hice algunos cálculos y el circuito definitivo es éste:
Cuando el pulsador está abierto, el móvil ve una resistencia de 2 Kohmios, y cuando se pulsa, al poner en paralelo un valor de 320 ohmios, el valor que ve es de 1 / (1/2000 + 1/320) = 275,8 ohmios, lo que activa la función B (subir volumen).
Ahora llegó el momento de decidir cómo activar la cámara. Aunque la primera opción sería tener un pulsador en algún lugar cómodo, eso seguiría implicando soltar lo que esté haciendo, así que decidí que tenía que ser algo que pudiese activar sin las manos. Y la opción obvia es un pedal. Aunque podía comprar uno, preferí aprovechar cosas que ya tenía por aquí y montarme uno yo mismo. Para ello utilicé unos pulsadores de circuito impreso que tenía en casa y unas protoboards.
Los cuatro pulsadores están conectados en paralelo, así que basta con que se active cualquiera para que el móvil detecte la función «subir volumen». Obviamente, la placa va al revés de como se ve, con los pulsadores hacia el suelo, y hago presión por el lado de las soldaduras… algo nada recomendable (ni para las soldaduras, ni para el pie si se hace descalzo), así que le pegué una segunda placa por el lado opuesto para taparlo todo.
Como ya comenté, decidí reemplazar el cargador original del Atmega32U4, llamado DFU y que se puede descargar desde la página de Atmega, por Ubaboot, un bootloader reducido que sólo ocupa 512 bytes y que es muy sencillo de utilizar. A mayores envié dos parches para simplificarlo aún más:
Para instalar Ubaboot, lo primero que hay que hacer es editar el fichero config.h y configurar los parámetros de nuestra placa. En el caso de mi teclado, hay que descomentar OSC_MHZ_16 (pues el reloj es de 16MHz), y USB_REGULATOR:
Una vez hecho esto, hay que programar los fuses del microcontrolador para un bootloader de 512bytes, además de asegurarnos de configurar bien el resto. En el caso de mi teclado, la configuración es la siguiente:
Fuse LOW: 0x5E
CKDIV8 0
CKOUT 1
SUT1/0 = 0x01
CKSEL3/0 = 0x0E
En este bloque básicamente no tocamos nada.
Fuse HIGH: 0xDE
OCDEN 1 (desactivado)
JTAGEN 1 (JTAG desactivado)
SPIEN 0 (programación por SPI activada)
WDTON 1 (watchdog desactivado)
EESAVE 1 (preservar EEPROM al borrar la memoria)
BOOTSZ1/0 0x11 (bootloader de 512 bytes)
BOOTRST 0 (vector de reset apunta al bootloader)
En este bloque básicamente desactivamos el JTAG, pues no lo necesitamos para nada, ponemos la dirección de inicio del cargador a 512 bytes antes del final de la memoria, y por último configuramos el vector de reset para que salte al cargador directamente. Esto último es muy importante, pues el propio cargador detecta si estamos arrancando «en frío» (en cuyo caso saltará a nuestro código directamente) o si hemos pulsado el botón de reset (en cuyo caso entrará en modo programación).
Fuse EXTRA: 0xFE
RESERVADO 7/4 tienen que estar todos a 1 (0xF)
HWBE 1
BODLEVEL2/0 0x1 (EDITADO)
El entorno de Arduino me había cambiado el BODLEVEL a 110 (1,8 a 2,2 voltios), en lugar del original 011 (2,4 a 2,8 voltios). Tras algunas pruebas, y en base a mi experiencia, he decidido que es más seguro ponerlo a 001 (3,3 a 3,7 voltios). Esto es algo que he cambiado en este artículo después de haberlo publicado.
El siguiente paso es conectar un programador SPI al teclado a través de los pines correspondientes. Yo uso un BusPirate que me prestaron, para lo cual tuve que editar el fichero Makefile y sustituir usbtiny -B10 por buspirate -P /dev/ttyUSB0 -b 115200, además de instalar AVRdude y el resto de utilidades de AVR. Con esto ya sólo me queda conectarlo al teclado y ya puedo leer el estado con
y hacer make y make program para grabar el Ubaboot. Con él grabado, sólo tengo que pulsar el boton de RESET del teclado y se pone automáticamente en modo programación por USB, con lo que ya no necesito más el BusPirate.
Y ya, por último, instalé Arduino y Teensyduino para disponer de las bibliotecas de USB. Sin embargo, hice un pequeño cambio para integrar la programación mejor. Los cambios concretos están descritos en el fichero README del segundo parche que envié a Ubaboot.
Y con esto escribí la primera versión del software de mi teclado, pero eso lo comentaré con calma en otra entrada.
Hace tiempo me compré una tableta de dibujo de estas para «pintar con lápiz», pero por desgracia nunca la pude usar porque no funcionaba correctamente en Linux: al mover el lápiz, el cursor del ratón se movía correctamente, pero no hacía nada cuando tocaba sobre la superficie ni cuando pulsaba los botones del lápiz. Sin embargo, como estos días tenía algo de tiempo libre, decidí ponerme con ella a ver qué podía descubrir, y si conseguía resolver el problema.
La tableta de dibujo
Lo primero que hice fue echar un vistazo a la información de lsusb. Ahí puede ver el código del fabricante y el del dispositivo:
Bus 002 Device 006: ID 2179:0004 UGTABLET TABLET WP5540
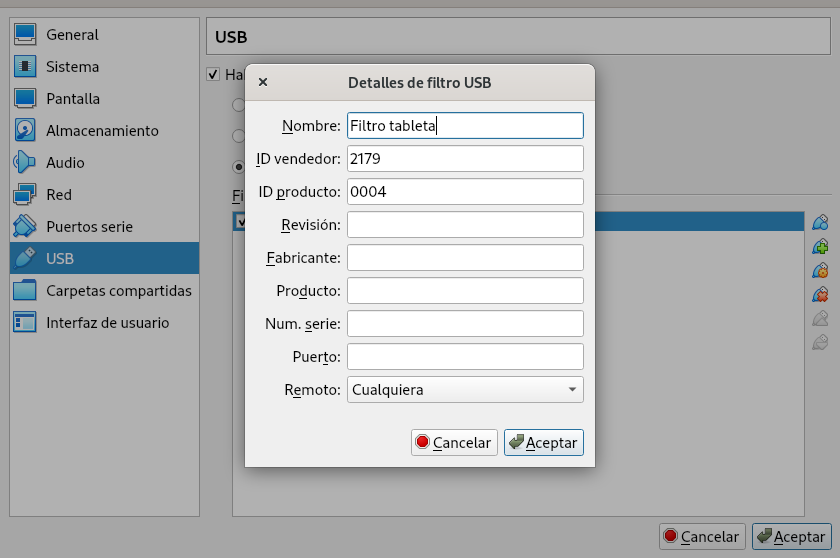
Decidí entonces que podría probarla en Windows, a ver si era un problema de la tableta en sí. Para ello instalé uno en una máquina virtual y configuré un filtro USB para que redirigiese la tableta a éste tan pronto se enchufase, y evitar así interferencias desde Linux.
Y funcionó perfectamente: si movía el lápiz a unos milímetros de la superficie, el cursor se movía igual que en Linux, pero si lo apoyaba, Windows identificaba una pulsación de botón de ratón y podía seleccionar iconos, cosa que en Linux no ocurría. Los dos botones del lápiz también funcionaban como el botón derecho y central del ratón.
Por supuesto, dado que la tablet medio funcionaba en Linux, yo supuse que debía seguir el estándar USB HID, pero que habría algo que se salía de él y Linux no era capaz de identificar correctamente. O bien podría ser que hubiese que configurar primero de alguna manera la tableta, y que Windows lo estuviese haciendo bien y Linux no.
Esnifando paquetes USB
Decidí comprobar primero la segunda posibilidad. Para ello desenchufé primero la tableta y cargué el módulo usbmon con:
sudo modprobe usbmon
Luego lancé Wireshark, empecé a capturar desde el puerto 2 de USB (pues, si vemos la salida de lsusb, es en él en donde está el puerto que usé), conecté la tableta, e hice algunos movimientos con el lápiz sin apoyar y apoyado en la superficie.
Hecho esto, detuve la captura, desconecté la tableta, apagué la máquina virtual, e hice una nueva captura, para ver qué hacía Linux. Luego abrí ambas capturas, cada una en una ventana diferente, y filtré los paquetes de la tableta con:
usb.bus_id == X&& usb.device_address == YY
Siendo X el bus en el que estaba conectada la tableta, e YY el identificador que se le asignó en cada momento.
El resultado no fue nada conclusivo, pues en ambas capturas salía más o menos lo mismo: primero se piden los datos básicos del dispositivo, luego la configuración completa (donde pone que es un dispositivo HID), algunas cosas más sin importancia, y finalmente lee el HID Report, donde vienen los datos HID para configurar el dispositivo. Tanto en Windows como en Linux eran exactamente iguales, por lo que no parecían ir por ahí los tiros. Una vez hecho todo esto, el resto de datos se enviaban sólo desde la tableta hacia el ordenador en forma de interrupciones USB, y parecían bastante similares entre ambos sistemas operativos.
Llegados a este punto no podía hacer mucho más, porque no sabía nada sobre el estándar HID ni sobre el significado de cada byte que se estaba enviando sobre el cable, así que decidí hacer un alto y leerme la documentación oficial de HID (una lectura amena y tremendamente divertida, como cualquier documentación oficial 😝 ).
El estándar HID
La idea detrás de HID es crear un protocolo que permita definir absolutamente cualquier dispositivo de interfaz humana, tanto actual como futuro, y hacerlo además de una manera que permita que cada fabricante lo implemente casi de la manera que quiera. Para ello, un dispositivo HID simplemente tiene que definir un HID Report, que no es más que una tabla donde se definen qué tipos de entrada tiene, y poco más. Dicha tabla puede estar definida directamente en ROM, lo que simplifica mucho el diseño.
¿Y qué contiene dicha tabla? Pues básicamente una serie de entradas en las que se define, para cada posible sensor o actuador del dispositivo:
Tipo (por ejemplo: Eje X relativo, Tecla Y, presión…)
Número de bits que ocupa el dato (el bit inicial se deduce de la propia lista)
Rango físico y lógico
Y algunas cosas más. Además, las entradas se pueden agrupar por tipo de dispositivo, de manera que no es lo mismo un botón de ratón que un botón de teclado, y asignarle un identificador a cada grupo.
En el caso de mi tableta, la tabla HID es así:
Uso digitizer (id: 0x07)
Punta de lápiz: 1 bit
Botón de lápiz: 1 bit
Goma de borrar de lápiz: 1 bit
No usados: 2 bits
Lápiz dentro de rango: 1 bit
No usados: 2 bits
Eje X: 16 bits
rango físico: 0, 5500
rango lógico: 0, 22000
Eje Y: 16 bits
rango físico: 0, 4000
rango lógico: 0, 16000
Uso mouse (id: 0x08)
Botón 1: 1 bit
Botón 2: 1 bit
Botón 3: 1 bit
No usados: 5 bits
Eje X relativo: 8 bits
rango lógico: -127, 127
Eje Y relativo: 8 bits
rango lógico: -127, 127
Rueda de ratón: 8 bits
rango lógico: -127, 127
No usados: 8 bits
Uso mouse (id: 0x09)
Botón 1: 1 bit
Botón 2: 1 bit
Botón 3: 1 bit
No usados: 5 bits
Eje X absoluto: 16 bits
rango lógico: 0, 32767
Eje Y absoluto: 16 bits
rango lógico: 0, 32767
Presión del lápiz: 16 bits
rango lógico: 0, 1023
Con esta tabla a mano, si nos llega un bloque de interrupción con los siguientes valores:
09 00 5d 49 05 56 00 00
Podemos deducir fácilmente su significado: el primer byte es el uso, por lo que, al ser 9, tenemos que fijarnos en el último de los tres bloque de la tabla. El primer byte contiene el estado de tres botones de tipo ratón, pero como los bits correspondientes son 0, significa que no están pulsados. Los dos siguientes bytes son la posición del lápiz en el eje X, los dos siguientes la posición en el eje Y, y los dos últimos la presión. Fácil.
La cuestión es que tanto en Windows como en Linux los datos que se enviaban eran exactamente iguales: si tocaba con el lápiz en la superficie se activaba el bit 0 del primer byte y aparecía un valor en los dos últimos bytes, que aumentaba con la presión que ejercía. Si pulsaba alguno de los dos botones en el lápiz se activaban los bits 1 o 2 del primer byte… todo era correcto, salvo por el detalle de que Linux no hacía caso. Incluso escribí un pequeño programa en python para leer e interpretar los datos en tiempo real desde la interfaz usbmon, y todo era correcto: los datos se enviaban correctamente, y siempre era con bloques de tipo 9.
De hecho, no podía evitar preguntarme por qué había dos entradas de tipo ratón, y sobre todo por qué una de ellas tenía ejes relativos. La respuesta se me ocurrió de casualidad: este chip sirve para tabletas híbridas, donde se puede usar un lápiz o un ratón:
Ejemplo de tableta con lápiz y ratón
Eso explicaba los dos tipos: si se usaba el ratón, se emitirían interrupciones con el tipo 0x08, y si se usa el lápiz entonces serían de tipo 0x09. Y el tipo 0x07 supongo que sería para algún tipo de lápiz diferente.
Vamos al kernel
Llegados a este punto comprendí que el problema tenía que estar, necesariamente, en el driver HID de Linux, así que descargué las fuentes del kernel, las compilé y las instalé en mi Debian con:
make localmodconfig # copia la configuración del kernel actual make -j5 make deb-pkg -j5 # crea paquetes .deb
Y con ello, me fui al fichero hid-input.c. En él encontré el punto en el que procesa la tabla HID y descubrí un detalle interesante hacia el final de la función:
¡Si un evento estaba duplicado, parecía ignorarlo a menos que se activase HID_QUIRK_INCREMENT_USAGE_ON_DUPLICATE! Esto tenía buena pinta, porque, efectivamente, los eventos de pulsación de ratón están duplicados en el bloque 8 y en el 9. Probé a añadir el Quirk para mi tableta en el fichero hid-quirks.c, compilé, desmonté los módulos de HID y volví a montarlos, y…
¡CASI! Me había asignado al lápiz las siguientes tres acciones del ratón: siguiente página, anterior página y no-se-cual-más. Claramente iba por buen camino.
Se me ocurrió entonces modificar el código para invertir el orden en el que se procesaban las entradas de la tabla HID, de manera que primero se añadiesen las del bloque 9 y luego las del 8, y el resultado fue que… ¡¡¡FUNCIONÓ!!! Parecía que lo había resuelto, así que creé un parche para poder configurarlo como un Quirk más, añadí mi tableta a la lista de dispositivos con Quirks, y envié un parche a la gente del kernel. En respuesta, amablemente me indicaron que mi solución se veía demasiado alambicada, y que quizás debería probar con HID_QUIRK_MULTI_INPUT, que crearía un dispositivo diferente para cada tipo de bloque. Lo probé, y efectivamente, esa era la solución, así que creé un nuevo parche, mucho más sencillo, lo envié, y fue aceptado. ¡¡Hurra!!
Añadiendo un QUIRK a un dispositivo en el driver HID
Vamos a ver este detalle con más calma porque es importante, y puede serle útil a más gente. Lo primero que tenemos que hacer es bajarnos las fuentes del kernel actual desde el repositorio GIT oficial:
Una vez que lo tenemos, nos hacemos un branch para nuestro parche y abrimos el fichero drivers/hid/hid-ids.h. En él buscamos si el fabricante de nuestro dispositivo ya está añadido o no (lo más probable es que sí), mediante el identificador que obtuvimos con lsusb. En mi caso, el identificador 0x2179 ya estaba añadido a nombre de UGTizer con:
#define USB_VENDOR_ID_UGTIZER 0x2179
pero dentro de él no estaba mi tableta, por lo que añadí una línea con su definición:
Una vez hecho esto sólo tuve que abrir el fichero drivers/hid/hid-quirks.c y añadir una entrada con mi vendor, mi device y los quirks que quería añadir para él:
¿Y mientras espero a que mi distro añada el parche?
Obviamente no quería estar con el kernel de desarrollo en mi sistema, sino que quería tener el oficial. ¿Significa eso que no podré usar mi tableta hasta que Debian haga un backport del parche? Pues afortunadamente no, porque el módulo HID permite pasarle manualmente un grupo de quirks a añadir a un grupo de dispositivos. Para ello basta con editar el fichero /etc/default/grub y, en la línea donde se definen los parámetros de arranque del kernel (que, en general, será la de GRUB_CMDLINE_LINUX_DEFAULT) añadir lo siguiente:
usbhid.quirks=0x2179:0x0004:0x0040
El primer número hexadecimal es el identificador USB del fabricante, el segundo es el identificador de dispositivo, y el tercero es un mapa de bits con los quirks a activar. La lista está definida en el fichero drivers/hid/hid.h, y en el momento de escribir este artículo es:
Algunos son obvios, pero otros, la verdad, es que no se para qué pueden servir, así que si algún día me encuentro con un dispositivo HID que no va, iré probando de uno en uno a ver.
Recientemente, Alva Majo, desarrollador de videojuegos indie y youtuber, publicó un vídeo donde explicaba cómo creó Alvabot, un sintetizador de habla que utilizaba muestras de su propia voz. Como, además, hizo público el código fuente y las muestras de voz, decidí que podía ser divertido intentar llevarlo un poco más allá y hacer que cantase. ¡Y lo he conseguido!
Sí, vale… el resultado no es exactamente profesional, pero para ser algo hecho en un par de días, creo que no está mal.
El proceso fue algo alambicado, pero al final no tiene mucha ciencia. Obviamente, si hubiese querido conseguir mejores resultados tendría que haber utilizado otras técnicas, pero la idea era hacer sólo un pequeño divertimento.
En primer lugar escribí una pequeña herramienta en Python (analizador.py, disponible en el repositorio) que me permite ver la forma de onda de un fichero WAV, escoger un trozo entre dos puntos concretos, calcular la frecuencia de dicha onda, y cortar entre los máximos de dicho trozo (todo esto lo explicaré mejor a continuación). Gracias a que Python tiene módulos para todo, no necesité programar casi nada, sino que ha sido más una operación «de pegar cosas».
Así, tomé los samples de las vocales y utilicé la herramienta anterior para revisar la forma de onda de cada una (en este artículo denominaré sample a cada fichero de audio con el sonido de una vocal o una consonante; y utilizaré el término muestra para referirme a cada uno de los datos de sonido que hay dentro de cada fichero; esto es: cada «número» dentro del fichero .WAV será una muestra).
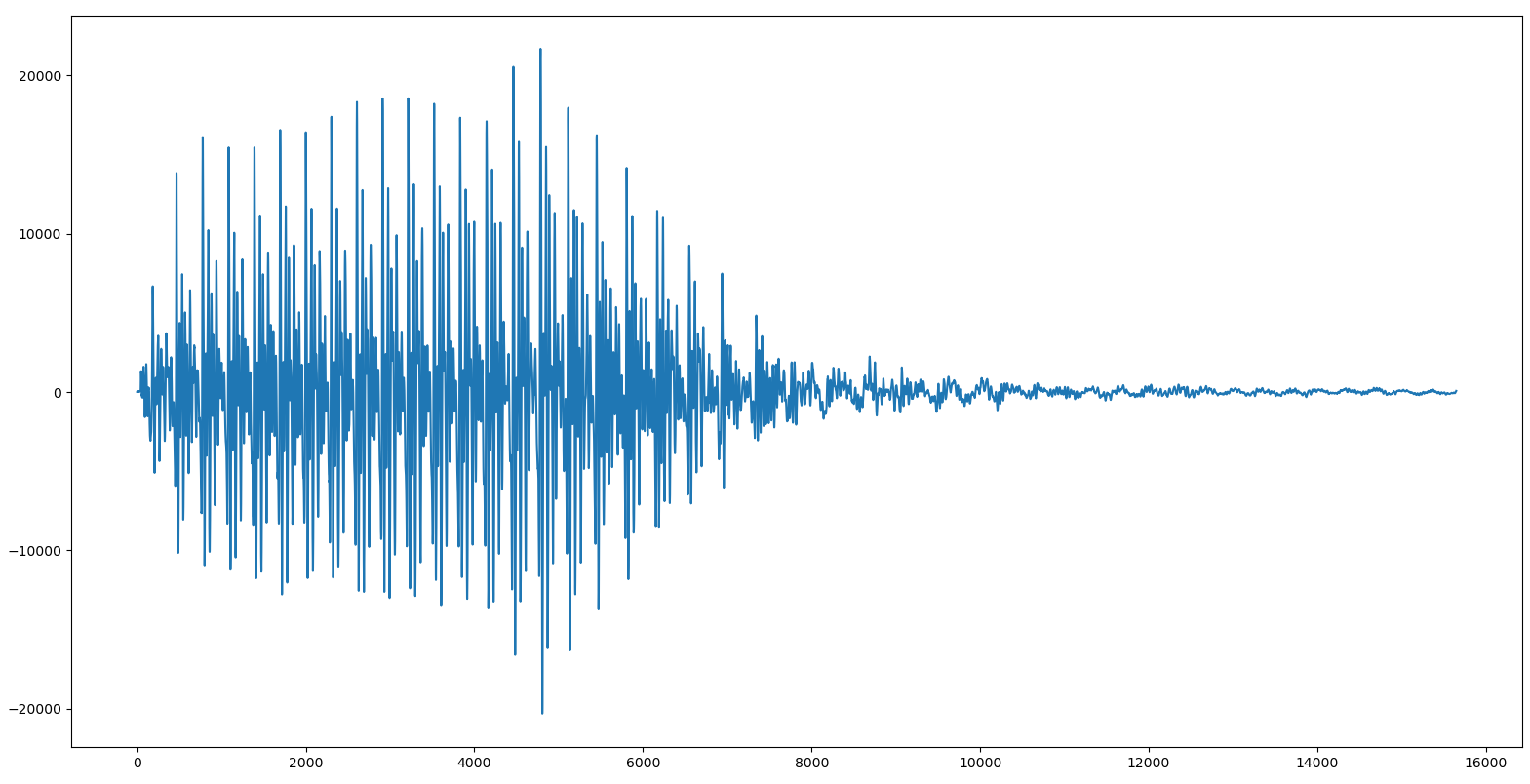
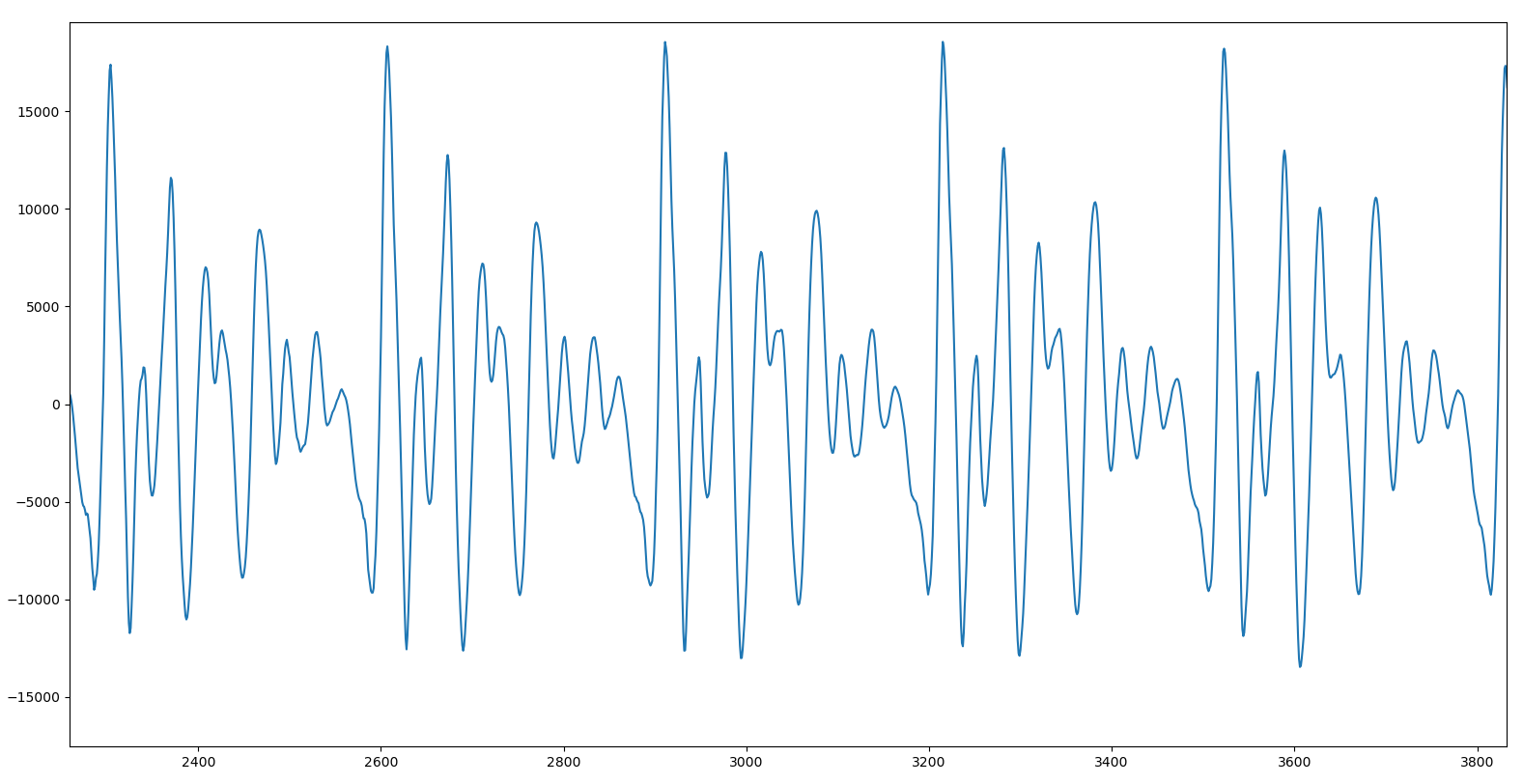
Aquí vemos una ampliación de la vocal A, tal y como se ve en la herramienta:
Si nos fijamos, vemos que parece que hay cierta «repetición». O sea: la onda no es «aleatoria», sino que parece que hay un bloque que se repite en el tiempo (como se puede apreciar por esos picos espaciados de manera regular). Es verdad que la amplitud (la altura) no es constante, pero eso es simplemente porque Alva es un ser humano, y por mucho empeño que ponga es imposible que mantenga exactamente la misma intensidad durante toda la vocal, sino que inevitablemente subirá y bajará un poco en el tiempo.
Para verlo mejor, ampliemos un trozo:
Aquí ya se ve mucho mejor cómo la vocal es, en realidad, un trocito de sonido que se repite una y otra vez. En esta imagen concreta lo vemos repetido cinco veces. Esto significa que si creamos un sample con sólo ese trozo, podremos repetirlo en bucle y conseguir que el ordenador pronuncie una vocal durante todo el tiempo que queramos, sin que se noten cortes, ligaduras ni nada por el estilo. Esto es fundamental a la hora de cantar porque cada nota puede tener una duración diferente a las demás, y son justo las vocales las que se «estiran» en el tiempo para cubrir todo el tiempo que dura una nota.
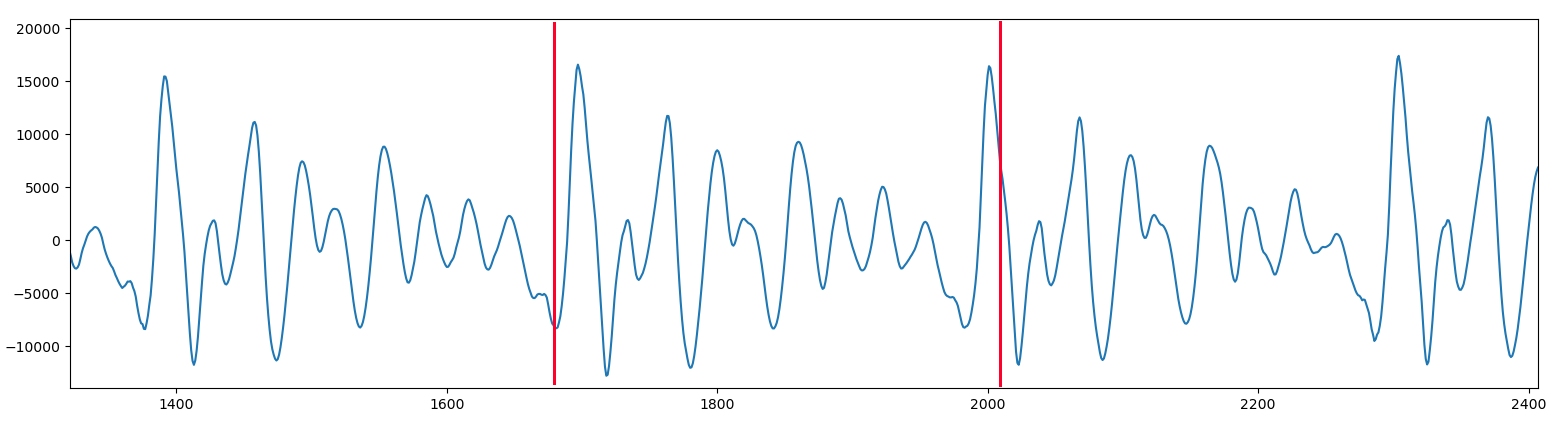
Aquí es donde mi herramienta analiza.py me pide dos puntos en la gráfica. El primero tiene que estar un poco ANTES de uno de los máximos, y el segundo un poco DESPUÉS del siguiente máximo. Entonces, la herramienta busca hacia adelante el valor máximo local desde el primer punto, y hacia atrás desde el segundo punto, para así recortar con precisión el trozo periódico. Para la vocal A utilicé 1668 y 2023, marcados en rojo en la imagen, y que como vemos caen justo cerca de dos máximos consecutivos. El propio programa busca los máximos, los cuales están en 1697 y 2001.
Lo segundo que hice fue calcular la frecuencia fundamental de cada vocal. Para los que no sepan a qué me refiero, la frecuencia fundamental determina la «nota» en la que está sonando la vocal. Cuando mayor sea la frecuencia, más alta en la escala será la nota. Al principio hice algunas pruebas con la transformada de Fourier, hasta que me di cuenta de que no necesitaba complicarlo tanto, pues simplemente con saber el número de muestras que hay en el «trozo» repetitivo y la frecuencia de muestreo, ya puedo obtener la frecuencia fundamental del sample.
Así, por ejemplo, si decidimos utilizar para la vocal A el bloque situado entre los picos de las muestras 1697 y 2001, vemos que hay un total de 304 muestras en él, lo que significa que si dividimos la frecuencia de muestreo de este fichero .WAV (que es de 44100 muestras/segundo) entre dicho valor, nos dará que la frecuencia a la que Alva pronunció la letra A es de 145 Hz.
Repitiendo este proceso para las cinco vocales, sale que cada una fue pronunciada con estas frecuencias:
vocal A: muestras 1697 a 2001, 145 Hz vocal E: muestras 555 a 855, 147 Hz vocal I: muestras 2968 a 3242, 161 Hz vocal O: muestras 2246 a 2544, 148 Hz vocal U: muestras 3027 a 3317, 152 Hz
Esto demuestra que Alva Majo NO es un robot, pues no es capaz de afinar correctamente. Por eso cada vocal tiene una frecuencia diferente.
Pero claro, para nosotros esto es un problema porque si queremos que el ordenador cante, necesitamos que las muestras estén todas en la misma frecuencia. Si no, lo único que conseguiremos es un ordenador que desafina.
Afortunadamente, una vez que tenemos ya aislado el bloque periódico de cada vocal, ajustar su frecuencia es muy sencillo: sólo necesitamos hacer que todas midan lo mismo (pues la frecuencia fundamental depende del tamaño del bloque y de la frecuencia de muestreo; como la frecuencia de muestreo tiene que ser la misma para todos los samples, tenemos que conseguir que el número de muestras sea igual). Si calculamos la media de todas esas frecuencias, nos salen 150 Hz, así que ajustaremos todas a ese valor para evitar tener que desplazarlas demasiado. Y si ahora dividimos la tasa de muestreo entre esa cifra, nos sale que cada bloque debe tener 44100/150 = 294 muestras. Por supuesto, no se trata de añadir, por ejemplo, ceros al final, porque entonces estaríamos modificando la señal. Lo que necesitamos es «inventarnos» muestras en medio para estirarla si es demasiado corta, o «tirar a la basura» muestras si es demasiado larga. Por supuesto, si añadimos muestras éstas deben «encajar» con las que las rodean; y si quitamos muestras, debemos hacerlo de manera «repartida». Esto, como no, tiene un nombre: remuestreo o cambio de tasa de muestreo, y el módulo scipy incluye una función llamada resample() que lo hace. Así que en la parte final de la herramienta hago una llamada a dicha función para ajustar cada sample justo antes de grabarlo en disco.
Para poder evaluar los resultados, podemos comparar el antes:
con el después:
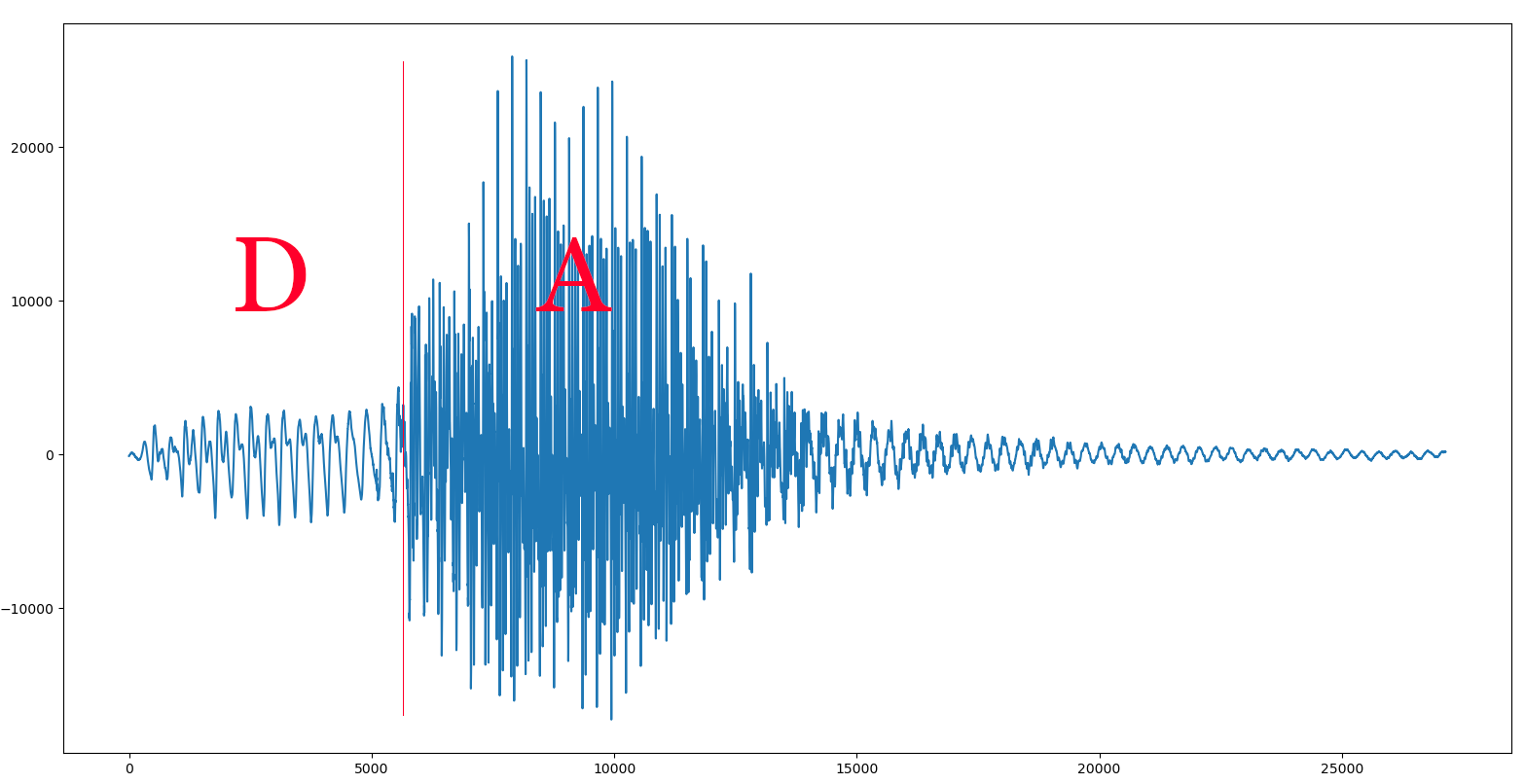
Ahora llega el momento de hacer lo mismo con las consonantes, pero esto es un poco más complicado, pues éstas no tienen por qué tener un patrón (aunque algunas sí), por lo que será difícil calcular su frecuencia… o no, porque, afortunadamente, Alva grabó todas las consonantes seguidas de todas las vocales. No tenemos sólo el fonema ‘P’, sino que también tenemos los sonidos de ‘PA’, ‘PE’, ‘PI’, ‘PO’ y ‘PU’, así que podemos medir la frecuencia a la que pronunció la vocal y asumir que es la misma que la del fonema de la consonante. Luego sólo tendremos que cortar justo en el punto donde termina la consonante y empieza la vocal, y tendremos el sonido puro de la consonante. Veamos un ejemplo con la sílaba «DA»:
Para hacer esto escribí otra pequeña herramienta, cortar_consonantes.py, la cual carga un fichero .WAV, muestra su forma de onda para que podamos buscar dos muestras que delimiten un periodo de la vocal, y nos pide que tecleemos su posición. Con ellas calcula la frecuencia a la que está pronunciada y también cuanto tiene que estirar o encoger todo el fichero WAV para ajustarlo a los 150 Hz que decidimos que sería nuestra frecuencia central.
Una vez que está ajustada, nos pide el número de muestra en la que realizar el corte para separar la consonante de la vocal. Como no es fácil acertar, lo que hice es que, tras dar un punto de corte, reproduzca la consonante seguida de la vocal «I» (para lo cual, utilizo los samples que generé antes). De esta manera, si se recorta demasiado poco y se cuela parte de la vocal original, sonará AIIIIIII en lugar de IIIIIII. Así podremos ir ajustando hasta encontrar el punto óptimo de cada consonante. Cuando hayamos encontrado el punto exacto, simplemente pulsamos RETURN en lugar de meter un nuevo número y el programa grabará el nuevo sample con sólo la consonante, ya ajustada a 150 Hz.
Algunas consonantes, pese a todo, son sonoras, lo que significa que SI están formadas por una zona repetitiva. En concreto, para la B, la M y la N utilicé el mismo sistema que para las vocales, pues se entendían mucho mejor que extrayéndolas «tal cual» de los samples.
Haciendo que hable
Ahora que ya tenemos los sonidos vocales y consonantes aislados y a la misma frecuencia, podemos hacer una primera prueba que se limite a hablar. Para ello escribí hablar.py, que generará un fichero habla.wav en el que pronunciará la frase que se le pase por la propia línea de comandos.
Lo primero que hace este programa es sustituir las letras por fonemas, de manera que no hace falta pensar en sonidos sino que podemos escribir directamente una frase. Además, si alguna vocal tiene tilde la pronunciará a una frecuencia ligeramente superior, lo que permite simular la entonación de las frases. En teoría se podría hacer que fuese completamente automático, y que si una palabra no tiene tilde, compruebe si acaba en n, s o vocal y, en base a ello, determine si es aguda o llana y ponga la tilde automáticamente, pero no me apeteció ponerme con ello, así que hay que hacerlo a mano.
Ejemplo: «Hóla, sóy cantabót hablándo.»
Y haciendo que cante
Y por último, está la herramienta final, cantar.py, que genera un fichero .WAV con una canción generada con las muestras.
El programa se compone de una clase con dos métodos fundamentales: interpreta() y pausa(). Estos dos métodos se deben ir llamando para introducir la partitura y la letra de la canción. Cada llamada renderiza los sonidos correspondientes, que se van añadiendo a un buffer interno. Cuando la canción está lista, se llama al método grabar(), que lo almacenará en disco en formato WAV con el nombre canta.wav.
El método pausa es el más sencillo, y simplemente recibe como parámetro un número decimal con el número de segundos de silencio que se deben añadir al buffer. Permite añadir silencios entre notas.
El método interpreta es el más complejo, y recibe tres parámetros:
Un entero con la octava de la nota a interpretar. Este valor estará entre 0 y 12 e indica el semitono concreto. La correspondencia exacta está en el código fuente
Un valor decimal con la duración en segundos de la nota.
Un string con los fonemas a cantar en dicha nota
Para simplificar la composición, se definen seis variables (redonda, redondadot, blanca, blancadot, negra y negradot) con las duraciones en segundos. Se establece la duración de la redonda en 1,5 segundos, y el valor de la blanca y la negra queda definido automáticamente como la mitad y la cuarta parte de la redonda. A mayores, las duraciones con «dot» son un 50% más que la correspondiente sin «dot». Además, se definen también las variables nota_XX, con el valor de semitono correspondiente a cada nota (por ejemplo, nota_sol vale 5).
Por otro lado, a la hora de decidir cuanto tiempo dura cada fonema de la nota se siguen las siguientes reglas:
Las consonantes durarán lo que dure su sample, salvo las consonantes «sonoras», que durarán 0,2 segundos
Las vocales que no sean la última durarán 0,15 segundos
La última vocal durará el tiempo necesario para completar la duración de la nota
Así, la última vocal durará realmente la duración de la nota menos la duración del resto de fonemas. Este valor se calcula automáticamente, lo que simplifica mucho meter una partitura.
Dado que ya nos preocupamos antes de ajustar todos los samples para que estuviesen a 150 Hz, ahora lo único que tenemos que hacer es ajustar la frecuencia de todos los fonemas a la necesaria para la nota. Y lo interesante es que para saber cuanto tenemos que ajustar la frecuencia, sólo necesitamos elevar la raíz doceava de 2 al valor del semitono que le pasamos a la función (por supuesto, tras restar 5, pues por convenio he decidido que los samples estarán en SOL).
¿Y por qué la raíz doceava de 2? En este vídeo de Minute Physics lo explican muy bien, pero para simplificar: como la frecuencia de una nota cualquiera tiene que ser la mitad de la frecuencia de la misma nota en la siguiente octava, y cada octava son doce semitonos, la única manera de que esto encaje es que la frecuencia de cada semitono sea la frecuencia del semitono anterior multiplicado por la raíz doceava de dos. Así que si quiero hacer sonar un LA (semitono 7 como vemos en la tabla de arriba), necesito subir la frecuencia de los fonemas en dos semitonos, o sea, multiplicar dos veces por la raíz doceava de dos. En cambio, si quiero interpretar un MI, tengo que bajar la frecuencia en tres semitonos; o sea, dividir tres veces entre la raíz doceava de dos.
¿Y cómo cambiamos la frecuencia de los fonemas? Pues exactamente como vimos antes: interpolando para estirarlos o encogerlos. Si los estiramos, la frecuencia baja; y si los encojemos, la frecuencia sube. Por tanto, una vez hemos calculado el factor entre la frecuencia inicial y la final, sólo tenemos que coger el número de muestras que tiene cada fonema y multiplicarlo por dicho factor, obteniendo así el nuevo número de muestras que tiene que tener. Con ese número llamamos a interpolate() para que haga su magia, y añadimos las muestras al buffer.
Vamos ahora con el tema de los textos. Pintar letras no es algo demasiado complejo una vez que hemos pintado sprites, por lo que no voy a ahondar demasiado en ello. Sin embargo, sí hay un detalle que no es nada trivial, y es conseguir meter mucho texto en poco espacio. En mi juego Escape from M.O.N.J.A.S. tenía unos 10 kbytes de texto, y tenía el problema de que, sencillamente, no me cabía en la memoria. Sin embargo, el texto tiene la característica de que tiene mucha redundancia, por lo que es muy compresible. Así que decidí intentar ir por esa ruta.
Alguno pensará que comprimir datos en un Z80 a 3,5MHz es una quimera, algo totalmente imposible, por culpa de la poca potencia; sin embargo esto no tiene por qué ser así: hay algoritmos en los que lo complicado es comprimir, pero la descompresión es muy sencilla y rápida.
El algoritmo que utilicé fue el LZSS (cuando hice la primera implementación no sabía que se llamaba así, pero es tan sencillo en concepto que era obvio que tenía que estar ya inventado). La idea es sustituir cada bloque que sea idéntico a otro anterior por un par (offset, tamaño) que apunte a dicho bloque anterior. El ejemplo más típico que se pone es el del poema Green Eggs and Ham, y lo podemos ver explicado en la página de la wikipedia.
En mi caso me aprovecho además de que los caracteres ASCII tienen todos el bit 7 a cero, por lo que puedo utilizar un byte con el bit 7 a uno para indicar que ahí comienza un bloque comprimido. Cada bloque comprimido está formado por dos bytes, y como el bit 7 del primero tiene que estar a uno, eso me deja 15 bits en total para almacenar el offset y el tamaño del bloque. Tras hacer varias pruebas, encontré que para mi cantidad de texto el tamaño óptimo es de tres bits para el tamaño y 12 bits para el offset. Por supuesto, dado que no compensa comprimir bloques de tamaño cero, uno o dos, el valor almacenado será el tamaño menos tres (o sea, entre 3 y 10). Además, el offset será siempre a partir del principio del bloque completo de textos, y no «desplazamiento hacia atrás desde el punto actual». El motivo de esto es que al principio es donde hay más texto sin comprimir, y, por tanto, donde habrá más oportunidades de encontrar repetido texto de más adelante.
Esta implementación tiene varias cosas interesantes. Para empezar, es muy sencilla de implementar, y en segundo lugar, no necesita memoria intermedia para tablas (cosa que otros algoritmos, como el LZW, sí necesitan). Para simplificar aún más el algoritmo, habrá una condición extra: no habrá recursividad (esto es: dentro de un bloque comprimido no habrá otros bloques comprimidos, sino que siempre apuntarán a ristras de caracteres ASCII). Esto tiene el inconveniente de que la compresión es menor, pero simplifica sobremanera el algoritmo y reduce la memoria necesaria para la pila (y dado que trabajamos con threads, interesa que este valor sea lo menor posible).
Lo más interesante de este algoritmo así descrito es que se puede utilizar al vuelo; esto es: podemos ir imprimiendo los caracteres a medida que los vamos descomprimiendo. Y si le sumamos que una cadena ASCII normal es un bloque comprimido válido, tiene la ventaja extra de que podemos utilizar la misma función para imprimir textos «normales», sin comprimir.
Habrá una limitación extra, y es que un bloque comprimido no puede jamás cruzar la frontera entre dos «frases» o «bloques de texto». Esto es fundamental, pues si queremos poder descomprimir al vuelo una frase, necesitamos que empiece en un byte concreto, y no en mitad de un bloque comprimido. Así, si tenemos estas tres frases:
esta es la primera frase la primera frase empieza en esta es la primera que veo
tenemos que respetar las fronteras entre frases y no comprimir el final de la segunda junto con el principio de la tercera en un único bloque, pues entonces no podríamos descomprimir la tercera de manera independiente, sino que tendríamos que descomprimir la segunda antes, almacenando el resultado, y buscar el punto de unión.
Por desgracia, si la descompresión es muy sencilla y rápida, la compresión es endiabladamente fastidiada (con jota). De hecho, por lo que he visto, ni siquiera parece existir un algoritmo óptimo, sino sólo diferentes aproximaciones. Esto puede chocar, pues en apariencia basta con empezar por el principio e ir buscando si el bloque de caracteres que sigue ya está repetido anteriormente. Sin embargo, por sorprendente que parezca, el orden de las frases puede afectar (y mucho) al nivel de compresión obtenido. Veámoslo con este ejemplo:
12345678 12345 345678
Estas tres «frases» se pueden comprimir como
12345678 (0,5) (2,6)
Esto es: la segunda frase es un bloque con los 5 caracteres que hay a partir del offset 0, y la tercera frase es un bloque con los 6 caracteres a partir del offset 2. En total, 12 bytes. Sin embargo, si reordenamos estas frases así:
12345 12345678 345678
tenemos que la compresión será
12345 (0,5)678 (2,3)(7,3)
que consume 14 bytes.
La solución a esto ha sido ir probando a cambiar de sitio una frase de cada vez, recomprimir, y si le nivel de compresión es mejor, guardarlo y volver a probar, mientras que si el cambio es a peor, deshacerlo y probar de nuevo. Una pequeña mejora consiste en no deshacerlo con una probabilidad pequeña (el 0,1%), de manera que sea posible «volver atrás», y que el algoritmo pueda probar otros caminos lejos de un mínimo local, pero siempre conservando en memoria la mejor combinación hallada hasta el momento. Esto tiene el inconveniente de que para conseguir altos niveles de compresión se necesita mucho tiempo (para los textos actuales dejé mi PC trabajando unas 24 horas).
Además, existe otra optimización muy importante, que consiste en intentar comprimir antes los bloques de mayor tamaño, e ir probando luego con los de menor tamaño. Así, dado que el tamaño de un bloque puede ir de 3 a 10 bytes, primero busco todos los bloques de 10 bytes que puedo comprimir; una vez hallados, procedo a buscar en las cadenas sin comprimir que quedan los bloques de 9, luego los de 8, etc. Esto es importante porque puede ocurrir que por comprimir ahora un bloque de 3, más adelante no pueda comprimir un bloque mayor. Aquí tenemos un ejemplo:
12345678 ab456dfg b456df
En este caso, si comprimo en el orden que aparece, tendré
12345678 ab(3,3)dfg b(3,3)(12,3)
que son 20 bytes, mientras que si comprimo por tamaño, tendré:
12345678 ab456dfg (9,6)
que son 18 bytes.
La diferencia entre aplicar o no estas dos optimizaciones en brutal: sin ellas, conseguía una compresión del 68% aproximadamente, mientras que aplicándolas, los textos quedan reducidos a un valor en torno al 59,7%. Una diferencia abismal, que me permitió reducir los más de diez kilobytes originales en unos seis, y que entrase por fin todo en memoria.
El compresor que escribí, además, parte de un fichero en formato assembler normal y saca el mismo fichero también en assembler pero con los datos comprimidos. Eso significa que se conservan las etiquetas, por lo que para descomprimir una frase sólo hay que pasar la etiqueta correspondiente a la rutina de descompresión/impresión, y listo.
Queda, eso sí, un detallito especial, que es qué hacemos con los caracteres específicos del español (la eñe y las aperturas de interrogación y exclamación; las tildes decidí obviarlas). La solución que se me ocurrió fue mapearlas en caracteres por debajo de 127 que no se utilicen, como el asterisco, el porcentaje, etc, reemplazándolos en el juego de caracteres del Spectrum. Por supuesto, para simplificar el trabajo, el compresor también se encarga de esta tarea, por lo que en el código fuente original los textos irán en UTF-8, y el compresor se encargará de sustituir la eñe por el asterisco, etc.
El siguiente paso es implementar la lógica del juego. Se trata de la parte del código que hace que funcionen las cosas como deben funcionar. Por ejemplo, se encarga de mover al personaje principal y a los secundarios, animar objetos, etc. Este código se ejecutará justo después de que hayamos pintado todos los gráficos en el buffer secundario y mientras esperamos a que comience el barrido de un nuevo frame.
Esta parte se divide, al menos de momento, en dos piezas de código: una que actualiza la posición de cualquier personaje, y otra que ejecuta las distintas tareas o tasks.
Movimiento de personajes
Dado que los personajes están animados, es necesario tener en cuenta en qué posición se encuentran en cada momento, si están ya donde deben estar o no, la fase de la animación, etc. Además, para ahorrar memoria, tenemos por un lado el cuerpo en sí y por otro las piernas, siendo estas últimas la única parte animada realmente. Eso significa que cada personaje está compuesto realmente por dos sprites, pero sólo uno es el que tiene secuencias de animación. Además, cada bloque está repetido en espejo, para cuando el personaje tiene que moverse hacia el lado opuesto.
Sprites que forman a un personaje. Arriba están los dos cuerpos, uno para cada lado, y debajo de cada uno están las secuencias de animación de las piernas que corresponden a cada uno de los dos cuerpos.
Cada personaje está definido en una estructura como la siguiente:
DEFB 0x01 ; bit 0: 1-> es el personaje principal
; bit 1: 1-> es un personaje secundario
; bit 2: 1-> está caminando; 0-> no camina
; bit 5: 1-> mira hacia la izquierda; 0-> a la derecha
; bit 6-7: etapa de animación
; si el byte vale cero, es FIN DE LA TABLA
DEFB NOWX ; coordenada X actual
DEFB NOWY ; coordenada Y actual
DEFB DESX ; coordenada X final
DEFB DESY ; coordenada Y final
DEFW sprites_table ; puntero al sprite para el cuerpo
DEFW (sprites_table + 6) ; puntero al sprite para los pies
Vemos que tenemos, por un lado, la etapa actual de la animación y a qué lado está mirando actualmente el personaje, por otro lado dos juegos de coordenadas, y por último dos punteros a dos entradas de la tabla de sprites, uno apuntando a la entrada que muestra el cuerpo del personaje y otra que apunta a la entrada de las piernas. Cuando queremos que un personaje camine desde donde está actualmente (cuyo valor está almacenado en NOWX, NOWY) hasta otro sitio, debemos simplemente escribir las coordenadas de destino en DESX, DESY, y la rutina de movimiento de personajes se encargará del resto. Esta rutina se ejecuta justo después de pintar todo el buffer secundario, y lo que hace es comparar la coordenada X actual con la X final, y lo mismo con la Y. Si son iguales, pondrá el bit 2 a 0 para indicar que el personaje está en su destino y pasará a la siguiente entrada. Sin embargo, si alguna de las dos coordenadas actuales no es igual a su homóloga final, la rutina le sumará o restará 1, en función de lo que sea necesario para acercar al personaje a su posición final. A continuación copiará las coordenadas actuales en cada una de las dos entradas de la tabla de sprites. Luego incrementará en uno la etapa de animación, y en base al valor de ésta decidirá qué sprite concreto se mostrará para los pies (modificando para ello la entrada correspondiente de la tabla de sprites), además de ajustar la coordenada Z (porque nuestros personajes se mueven a saltos). Tras hacer todo esto, saltará a la siguiente entrada de la tabla y repetirá estas operaciones hasta llegar al final.
Vemos, pues, que esta rutina nos simplifica mucho el mover un personaje desde una zona del mapa hasta otra, pues sólo tenemos que poner las coordenadas finales y esperar a que el bit 2 cambie de 1 a 0 para saber que ha llegado.
Gestor de tareas
La rutina anterior nos ayuda un poco, pero todavía nos queda por implementar absolutamente toda la lógica del juego en sí. La primera idea consiste en escribir una función que se llame justo después de terminar de actualizar las posiciones de los personajes (esto es, justo des pués de la rutina anterior), y que, en base al estado actual del juego (donde está el protagonista, el resto de personajes, los objetos, etc) decida cual debe ser el nuevo estado (donde estará el protagonista y el resto de personajes, si algún objeto aparece o desaparece…), tras lo cual se pintará de nuevo el mapa y se repetirá el proceso.
Por desgracia, hacer algo así complica sobremanera la tarea, y además hace que cualquier cambio que se quiera hacer pueda afectar a otras partes, por lo que el código probablemente quedaría muy complejo. Por eso decidí seguir la idea que Ron Gilbert y compañía utilizaron en Scumm, la máquina virtual que desarrolló para el juego Maniac Mansion: permitir crear múltiples tareas que se ejecuten en paralelo y de manera independiente.
La idea básica es que cada personaje u objeto se maneje desde una tarea independiente, y que como mucho se añadan puntos de sincronización entre ellas. Las tareas se ejecutan mediante multitarea cooperativa, y se ejecutan una vez por frame del juego. Cuando una tarea ha terminado de hacer lo que tenga que hacer, simplemente tiene que hacer una llamada a una subrutina concreta para avisar, cediendo el control a la siguiente. Cuando todas las tareas se han ejecutado, se pintará el siguiente frame, se actualizará la posición de los personajes, y volverán a ejecutarse las tareas una a una, pero con el detalle de que cada una continuará su ejecución justo donde se quedó en el frame anterior, y además la pila o stack conservará todos los valores que la tarea hubiese almacenado en su ejecución previa.
Veamos cómo es la implementación:
task_list:
DEFW $+TASK_DATA_SIZE+2
DEFS TASK_DATA_SIZE
DEFW tarea1
DEFW $+TASK_DATA_SIZE+2
DEFS TASK_DATA_SIZE
DEFW tarea2
DEFW 0 ; fin de la tabla de tareas
task_run:
ld (old_stack), SP ; preservamos la pila global
ld iy, task_list
task_loop:
ld l, (iy+0)
ld h, (iy+1)
ld a, h
or l
jr z, task_end
ld sp, hl ; asignamos a SP la pila de la tarea a ejecutar
ret ; y saltamos al código de la tarea
task_yield:
ld hl, 0
add hl, sp ; almacena en HL el stack actual
ld (iy+0), l
ld (iy+1), h ; y lo guarda en la entrada de la tabla de tareas
ld de, TASK_ENTRY_SIZE
add iy, de
jr task_loop ; siguiente entrada de la tabla de tareas
task_end:
ld SP, (old_stack) ; restauramos la pila global
ret
Vemos que la tabla está dimensionada para dos tareas, y cada entrada de la tabla de tareas está compuesta de dos partes:
Los dos primeros bytes contienen la dirección de la pila o stack de esta tarea (recordemos que $ es «la dirección de esta línea»)
El resto de bytes es donde se almacena la pila o stack de esta tarea, con un total de TASK_DATA_SIZE+2 bytes
Vemos que en el código que puse arriba, los dos primeros bytes apuntan a los dos últimos bytes del bloque de la pila de cada tarea, y éstos contienen la dirección de entrada del código de cada tarea. De esta manera, lo que hacemos es inicializar la pila de cada tarea de manera que contenga un único dato: la dirección inicial de entrada para esa tarea.
Si nos vamos al código que viene justo a continuación, vemos que el punto de entrada es task_run. Esta es la función que se llama cada vez que se ha terminado de pintar un frame. Vemos que lo primero que hace es guardar la dirección del stack. Esto es necesario porque vamos a modificarlo para cada tarea, por lo que cuando terminemos, necesitaremos restaurarlo al valor inicial, o no podremos retornar.
A continuación cargamos en IY la dirección inicial de la tabla de tareas, pues vamos a utilizar dicho registro índice para recorrerla. Las tareas no deben modificar este registro bajo ninguna circunstancia.
Entramos ahora en el bucle principal, en el que simplemente tomamos los dos primeros bytes, vemos si ambos valen cero (lo que significaría que hemos llegado al final de la tabla), y si no es así, cargamos su valor en SP.
Ahora el puntero de pila apunta a la pila de la primera tarea, y si recordamos cómo inicializamos la tabla de tareas, el valor que hay en ella será la dirección de inicio de dicha tarea, con lo que al hacer un RET, el procesador sacará ese valor de la pila y saltará a él.
Ahora la primera tarea empezará a ejecutarse. Hará todo lo que tenga que hacer, y cuando haya terminado, simplemente hará un CALL task_yield. Esto significa que ahora la pila de la tarea ya no contiene la dirección inicial, sino justo la dirección desde la que se hizo esa llamada, lo que significa que cuando volvamos a llamar a task_run tras el siguiente frame, al ejecutar el RET se saltará justo a la siguiente instrucción tras el CALL en lugar de al principio, por lo que la tarea continuará su ejecución justo en el punto en el que lo dejó.
En task_yield vemos que lo que hacemos es almacenar el valor de SP en los dos primeros bytes de la entrada de la tabla de tareas. Esto es necesario porque la tarea podría haber almacenado algún valor antes de llamar a task_yield, lo que significa que la dirección de retorno ya no está al final de la pila, sino antes.
Tras ello, sumamos a IY el tamaño de una entrada de la tabla de tareas para así saltar a la siguiente, y repetimos el proceso hasta llegar al final de la tabla.
Veamos un ejemplo de una tarea, en concreto la que gestiona el movimiento del personaje amarillo:
task2:
ld ix, entrada_en_tabla_de_personajes
task2b:
ld (ix+3), 40
ld (ix+4), 42 ; cargamos las nuevas coordenadas a donde debe ir
call task_wait_for_walk ; esperamos a que llegue
ld (ix+3), 28
ld (ix+4), 34 ; cargamos las nuevas coordenadas a donde debe ir
call task_wait_for_walk ; esperamos a que llegue a su destino
jr task2b
task_wait_for_walk:
push ix ; guardamos en la pila el personaje
call task_yield ; y cedemos el control
pop ix ; en el siguiente frame, recuperamos el personaje
bit 2, (ix+0) ; vemos si está caminando
ret z ; está parado? retornamos
jr task_wait_for_walk ; y si aún no llego al destino, repetimos
Vemos que lo primero que hacemos es cargar en IX la dirección de la tabla de personajes correspondiente al personaje amarillo, y justo a continuación entramos en el bucle principal.
El personaje, al arrancar el programa, está en las coordenadas 28,34 (pues así lo definimos en la tabla de personajes, no por otra cosa), así que lo que hacemos es poner 40,42 como coordenadas de destino, y llamamos a task_wait_for_walk. Esta función, como vemos, lo primero que hace es preservar IX y devolver el control para que se ejecuten el resto de tareas y se repinte la pantalla. Cuando, en el siguiente frame, se ejecute de nuevo esta tarea, la ejecución comenzará justo en el POP situado después de la llamada a task_yield. Ningún registro se ha preservado, pero la pila sí se conserva, así que retiramos el valor de IX y comprobamos su bit 2 (que es el que nos dice si aún está caminando para llegar a las nuevas coordenadas, o si ya ha llegado). En este caso todavía no habrá llegado, por lo que volvemos a guardar IX en la pila y cedemos de nuevo el control. Así hasta que, tras varios frames, por fin el bit vale cero, momento en el que directamente retornamos al código que llamó a task_wait_for_walk. Y como ahora ya estamos en 40,42, lo que hacemos es poner ahora como destino 28,34 de nuevo y esperar a que llegue a su destino. De esta manera el personaje lo que hará será caminar desde 28,34 hasta 40,42 y vuelta, una y otra vez.
Vemos que el hecho de que la pila y las direcciones de retorno se conserven simplifica muchísimo el trabajo, pues el código de la tarea puede ceder el control para esperar a que todo el sistema avance sabiendo que continuará ejecutándose en el mismo punto como si nada hubiese pasado. Bueno, o casi nada, pues es cierto que los registros no se conservan entre llamdas a task_yield. Pero para eso basta con que la rutina preserve en la pila todo lo que necesite.
Por supuesto, esto significa que hay que dejar espacio suficiente en la pila para todos los registros que se quieran preservar a la vez, además de todas las direcciones de retorno… ¡y una dirección extra! Pues nos interesa que las interrupciones estén habilitadas mientras ejecutamos las tareas, porque de esta manera podemos aprovechar para ejecutarlas un tiempo que, si no usásemos interrupciones, simplemente tiraríamos a la basura; pero eso significa que puede metersenos un dato extra en la pila con el que, a lo mejor, no contábamos al dimensionarla.
Adaptando la ISR
Por desgracia, esto nos supone un problema extra, pues la ISR tiene que guardar en la pila todos los registros que vaya a utilizar. Esto significa que si dejamos nuestro código tal cual, necesitaríamos reservar en la pila de cada tarea el espacio suficiente para guardar no sólo todos los datos de la tarea, sino también 22 bytes extra, los necesarios para guardar la dirección de retorno de la interrupción y los diez pares de registros del procesador que utilizamos en la ISR (AF, BC, DE, HL, AF’, BC’, DE’, HL’, IX e IY).
Hacer esto sería un verdadero desperdicio de memoria, así que la solución es tan sencilla como reservar una zona de 22 bytes extra en memoria, y nada más entrar en la ISR, guardar el valor de SP al principio de esa zona, cambiarlo para que apunte al final más uno (recordemos que PUSH primero decrementa y luego almacena) del bloque, y sólo entonces guardar los diez pares de registros. Al salir, por supuesto, tras restaurar los registros hay que restaurar también SP, y sólo entonces retornar.
En la próxima entrada hablaré de la impresión de textos.
En la entrada anterior se me olvidó comentar un detalle extra, que es la tabla de sprites. Esta tabla contiene la información de cualquier sprite que no sea «de fondo»; esto es: todo sprite que vaya a ser animado, o que pueda aparecer o desaparecer, o moverse de sitio, y que, por tanto, no esté definido en el mapa sino que deba pintarse aparte. Estos sprites, al no ser parte del decorado en sí, no pueden almacenarse en la tabla del mapa que vimos antes (la que define las paredes, suelo y objetos fijos), sino que deben definirse aparte.
El primer ejemplo de este tipo de objetos son los propios sprites de los personajes: desde el momento en que éstos se pueden mover de un lado para otro es necesario que no formen parte del mapa. Otro ejemplo son todos los objetos que el protagonista puede coger o dejar, pues éstos aparecerán o desaparecerán del mapa, y también pueden cambiar de lugar en función de donde los deje el jugador. Por último, cualquier objeto animado, como por ejemplo los personajes, o una olla al fuego que hace chup, chup…
La tabla de sprites tiene el siguiente formato:
DEFB 5 ; coordenada Z
; si 255-> esta entrada está vacía
; si 254-> fin de la tabla
DEFB 40 ; coordenada X en el mapa
DEFB 32 ; coordenada Y en el mapa
DEFB 0x58 ; color de sustitución
DEFW sprite_base_right ; puntero al sprite-en-sí
En primer lugar tenemos la coordenada Z o de altura. Este byte tiene dos valores especiales: si vale 254 nos indica que es el final de la tabla y, por tanto, que no hay más sprites. Si vale 255 significa que esta entrada nos la debemos saltar porque está vacía. Esto es útil para objetos que pueden aparecer y desaparecer del mapa: cuando no está visible ponemos esta entrada a 255, y no se pintará; cuando vuelva a ser visible, la ponemos al valor de Z correcto.
Justo después están las coordenadas X e Y. La coordenada Y es fundamental a la hora de pintar el mapa. En efecto, si recordamos, cuando pintábamos el mapa lo hacíamos desde las coordenadas Y más bajas (que quedan «arriba» de la pantalla) hacia las más altas. Pues bien: cada vez que se pinta una fila completa del mapa, se recorre la tabla de sprites en busca de todos aquellos cuya coordenada Y coincida con la fila que acabamos de pintar. Si encontramos un sprite que cumpla esta condición, calculamos la coordenada Y de pantalla restando de su coordenada Y la coordenada Z (de manera que cuanto más «alto» esté en Z, más arriba aparecerá en pantalla, pero tapando todos los elementos del mapa que se encuentran antes que la Y del sprite). Es justo esto lo que nos permite simular el efecto 3D, en el que los objetos pueden moverse en los tres ejes, y ocluyendo (o tapando) todo lo que se encuentra detras.
El siguiente byte es el color de sustitución: en mi juego quiero que haya varios personajes, pero todos van a estar hechos con el mismo sprite, así que para distinguirlos cada uno tendrá un color diferente. La manera más sencilla de implementar esto obligaría a tener un conjunto de atributos de color diferente para cada sprite, lo que supondría un consumo excesivo de memoria. Así que decidí que los sprites que tienen máscara de transparencia (lo que incluye al sprite de los personajes) pueden marcar bloques de atributos para que sean sustituidos por este color. Para ello sólo tienen que activar el bit de FLASH y el de BRIGHT a la vez en un atributo concreto, y ese será sustituido por este valor. En cambio, si sólo marca el bit de FLASH, entonces simplemente no se escribirá ese atributo de color concreto, con lo que el color que se utilizará será el que ya había debajo. Esto permite conseguir también «transparencia» con los colores.
Así, en el caso del sprite del personaje, todas las zonas del traje tienen los bits de FLASH y de BRIGHT activos, lo que significa que el color que definí en el editor no se utilizará para esas zonas, sino éste que he definido aquí. Eso es lo que permite tener varios personajes, cada uno de un color diferente, sin consumir memoria extra para meter cada uno.
Por último, tenemos un puntero a los datos del sprite en sí. Esto se hace así para poder cambiar el puntero y, de esta manera, poder animar el sprite si se desea. Por ejemplo, si tenemos dos sprites de una olla que forman una animación, lo que haremos será ir cambiando la dirección del puntero de datos en la entrada de la tabla de sprites de manera que vaya alternando a cual de los dos apunta.
Desde que tengo mi robot aspirador, tengo que tener cuidado de dejar la puerta de la cocina cerrada cuando la uso, porque obviamente no es buena idea que se te cuele en un sitio donde siempre puede haber algo de grasa que se te haya caído, o así. Pero es un rollo tener que estar pendiente, así que decidí buscar una solución.
Lo primero que se me ocurrió fue comprar cinta adhesiva magnética, pues se supone que este modelo tiene un sensor, y cuando detecta un campo magnético asume que no tiene que entrar por ahí. Por desgracia, no funcionaba: la aspiradora pasaba por encima como si no estuviese.
Ante esto decidí buscar una alternativa, así que se me ocurrió que podía meter un relé reed conectado al sensor del parachoques, de manera que cuando pasase por encima de la cinta, el robot pensase que ha chocado. Así que aprovechando que se le acabó la garantía, decidí abrirla y echar un vistazo a ver si podía hacerlo.
Lo primero que me encontré es que mi suposición de que llevaba dos micros, el principal por un lado, y un ESP8266 (o ESP32, no fui capaz de verlo bien) conectado por un puerto serie, era acertada.
Claro, esto era muy raro, porque se supone que estos sensores son, entre otras muchas cosas, para detectar cintas magnéticas en el suelo. La conclusión que saqué es que está capado por software, y está ahí porque al fabricante le sale más barato fabricar todas iguales y luego afinarlo mediante código.
También vi que los sensores del parachoques no eran microswitches, sino optointerruptores. El motivo supongo que será fiabilidad.
El siguiente paso fue comprar unos cuantos relés reed y hacer varias pruebas a ver qué tal tiraban, pues temía que tuviesen que estar demasiado cerca de la cinta para funcionar. La primera sorpresa fue que funcionan mucho mejor en perpendicular a la cinta magnética que en paralelo, hasta el punto de que en paralelo hay que pegar prácticamente el relé a la cinta para que funcione, pero en perpendicular se activa ya a unos dos/tres centímetros.
Pero claro, no puedo garantizar que el relé siempre esté perpendicular, pues si la aspiradora va de frente hacia la cinta magnética, estará en una posición, mientras que si va siguiendo el borde de la pared, estará girado 90 grados…
Al final, lo resolví poniendo dos relés reed en cada lado, conectados en paralelo y a 90 grados uno del otro. De esa manera siempre funcionará de manera óptima.
La conexión sería bastante sencilla: bastaría con conectarlos en paralelo con el sensor óptico del parachoques:
De esta manera, cada vez que la aspiradora se acerque a la cinta magnética del suelo, creerá que ha chocado contra la pared.
La siguiente cuestión era… ¿donde los monto? La primera idea fue pegarlos directamente por debajo, pero luego me di cuenta de que los relés reed son de vidrio y muy frágiles, por lo que no era muy recomendable. Por otro lado, el interior del aspirador está muy lleno, y no queda casi sitio. Al final, después de darle varias vueltas y de considerar incluso ponerlos debajo de las trampillas de los motores de las ruedas, decidí que la tapa de la batería era el mejor lugar, sobre todo porque la batería deja suficiente hueco a cada lado. Así que procedí a pegar los dos grupos de relés por dentro de la tapa con pegamento térmico:
Una vez montados ambos pares de relés, procedí a pasar los cables por el mismo agujero por el que pasan los de la batería:
Por último, procedí a soldar los cables a los sensores. MUY IMPORTANTE NO EQUIVOCARSE, y conectar cada par de relés al sensor óptico del mismo lado, pues si no, la aspiradora girará hacia el lado opuesto y acabará quedándose atrapada sobre la línea.
Y con esto se acabó, y ahora mi aspiradora ya no se cuela en la cocina.
Llega el momento de hacer el mapa. Para ello tenemos que recordar que el Spectrum no tiene la capacidad de memoria de los ordenadores actuales, lo que significa que no podemos crear pantallas a lo bruto y guardarlas tal cual, sino que tenemos que buscar la manera de guardarlas comprimidas, para que ocupen lo menos posible. Una técnica habitual es utilizar tiles o losetas para crear las pantallas. En ellas, lo que se hace es generar un número pequeño de gráficos, y combinándolos y repitiéndolos de distintas maneras podemos crear multitud de estancias de un mapa ocupando muy poca memoria. Veamos un ejemplo con un trozo de mapa:
Vemos que hay varios elementos repetitivos, como por ejemplo las losetas del suelo; pero en realidad todo está colocado en base a una cuadrícula de elementos de 4×4 caracteres. Las posibles losetas que, de momento, se utilizan en el mapa son las siguientes:
Así, por un lado tenemos las definiciones de las diferentes losetas, y por otro la definición del mapa en sí. En esta última estructura lo único que tenemos que almacenar es qué loseta va en cada posición. Dado que la pantalla mide 32×24 caracteres, y cada posición de loseta mide 4×4 caracteres, tenemos que cada pantalla del mapa ocupará 8×6 = 24 bytes (si sólo empleamos un byte por loseta, claro). Por supuesto, las losetas en sí ocupan más memoria: en este caso, cada loseta de 4×4 caracteres ocupa 128 bytes de píxeles más 16 bytes para atributos de color; en total 144 bytes. Pero la ventaja es que una misma loseta se puede reutilizar varias veces en múltiples pantallas, por lo que el ahorro es muy grande. En la pantalla de arriba vemos que el grueso lo ocupa la loseta superior izquierda, y que las paredes de la izquierda y de arriba están hechas fundamentalmente con dos losetas concretas.
Pintando el mapa
Ahora que expliqué la base, voy a comentar algunos detalles de mi implementación. En primer lugar, las losetas mostradas arriba no tienen máscara de transparencia (con la excepción de la puerta vertical… ya lo explicaré luego). El motivo es que las losetas se utilizan para pintar el fondo de la pantalla, por lo que, dado que no hay nada debajo, no hace falta que tengan transparencia. Esto significa que, a la hora de pintarlas, tengo que tenerlo en cuenta. La primera idea sería poner una comprobación dentro del bucle que copia cada byte de un sprite al buffer de vídeo, pero tiene el inconveniente de que estamos comprobando lo mismo una y otra vez en todos los bytes que copiamos. Como vimos en las primeras entradas, pintar gráficos en pantalla consume mucho tiempo porque hay que copiar una cantidad ingente de bytes, y cualquier pequeño ahorro dentro del bucle supone un aumento brutal del rendimiento, pues se multiplica por los más de seis kilobytes que hay que copiar en cada frame. Es por esto que sólo hago una comprobación justo antes de entrar en el bucle externo (el que pinta las filas), y en función de si el sprite tiene o no máscara, voy a una rutina u otra. La rutina que pinta con máscara ya la vimos en la entrada número 6, así que pondré a continuación únicamente la rutina que pinta sin máscara. Partimos de HL apuntando al sprite, de DE conteniendo la dirección de destino, calculada a partir de las coordenadas, y de BC conteniendo el alto en scanlines y el ancho en caracteres (esos datos los obtenemos con el código común con la rutina que pinta con máscara):
ld A, C ; guardamos el número de columnas en A
push DE
push BC
ld B, 0
exx
pop BC ; pasamos el número de filas al juego alternativo de registros
pop IX ; y la dirección de destino a IX
ld DE, 32 ; valor a sumar para saltar al siguiente scanline
loop1:
exx
ld D, IXh
ld E, IXl ; la pasamos al conjunto de registros principal
ld C, A ; B vale cero, así que LDIR copiará A bytes
ldir ; copiamos una fila
exx
add IX, DE ; saltamos al siguiente scanline
djnz loop1
Esta rutina tiene la ventaja de que es mucho más rápida que la que utiliza máscaras, gracias a que se basa en LDIR. Así, cada byte necesita sólo 23 Testados frente a los 61 que necesitábamos en la rutina con máscaras, lo que es un gran ahorro, y más si nos aseguramos de que el máximo número posible de tiles no usan máscara, la cual la reservaremos sólo para los personajes y objetos móviles, pues ellos sí queremos que se muevan «por encima» de lo que ya está pintado, y para algún tile muy concreto.
Una vez que tenemos ya esta rutina, toca almacenar el mapa. La idea consiste en almacenar un array de bytes. En mi juego no voy a utilizar una distribución clásica de pantallas en la que el personaje se mueve por dentro de la pantalla, y cada vez que sale, la pantalla se borra y se pinta una nueva. En mi caso el personaje estará quieto en el medio de la pantalla, y todo el mapa se moverá a derecha, izquierda, arriba o abajo. Esto significa que, al no haber fronteras definidas, todo el mapa será un solo bloque. Este es el mapa de demostración que hice:
El mapa mide 32 tiles (256 caracteres) de ancho. Esto lo hice porque es el máximo valor que se puede almacenar en un byte para las coordenadas, y porque para multiplicar por el ancho sólo hay que rotar cinco veces el valor, lo que es una operación fácil y rápida. Por otro lado, he decidido que si un valor tiene el bit 7 a uno, significa que el personaje no puede pisar esa loseta. Así, las paredes, mesas, camas, etc. tendrán dicho bit a 1 para evitar que el personaje las atraviese, y sólo las losetas normales tendrán dicho bit a 0.
La correspondencia de cada número es como sigue:
; 0 -> no pintar
; 1 -> suelo normal
; 2 -> suelo roto
; 3 -> suelo con rejilla
; 4 -> minisuelo (suelo con una única línea, para muros horizontales)
; 5 -> muro vertical
; 6 -> muro horizontal
; 7 -> cruce de muros
; 8 -> parte superior de puerta vertical
; 9 -> parte inferior de puerta vertical
; A -> suelo exterior
; B -> minisuelo exterior (single-line)
; C -> muro en T superior
; D -> muro en T inferior
; E -> esquina inferior izquierda
; F -> esquina inferior derecha
;10 -> esquina superior izquierda
;11 -> esquina superior derecha
Los elementos 0, 4 y B pueden parecer extraños, pero tienen sentido para aquellas losetas que estarán tapadas por otras losetas que midan más de 4×4 caracteres. De hecho, comparemos la loseta 1 con la 4 y la B:
Vemos que son básicamente iguales, salvo porque la 4 y la B son más pequeñas verticalmente. El motivo de que existan estas losetas es que pintar un sprite supone una carga de procesador muy elevada, pues hay que copiar muchos bytes de un lado para otro, por lo que si podemos ahorrar pintar algunos bytes, mejor. Para entenderlo mejor, veamos cómo compongo el mapa para dar, además, apariencia 3D.
Pintando en pseudo3D
La vista del mapa pretende ofrecer un pseudo3D. Al contrario que otros sistemas, como por ejemplo las vistas isométricas, donde la coordenada X e Y de la pantalla sale de una combinación lineal de las coordenadas X, Y y Z de cada objeto, en este sistema la coordenada X de la pantalla es simplemente la misma que la del objeto, y la coordenada Y es la Y del objeto menos la Z. Sin embargo, esto es sólo parte del problema del pintado. La otra parte es decidir el orden en que hay que pintar los objetos para asegurarse de que el efecto pseudo3D es consistente: por ejemplo, que si un personaje pasa por detrás de una mesa o de una pared, quede parcialmente oculto. Para ello es necesario pintar todos los elementos en un orden concreto: de atrás hacia adelante, de manera que los objetos que están más cercanos vayan tapando lo que hay detrás. En el sistema que he escogido esto es muy sencillo: cuanto mayor sea la Y del objeto, más «abajo» en la pantalla estará y, por tanto, habrá que pintarlo más tarde.
Sabiendo esto, el proceso es muy sencillo: si queremos pintar el mapa desde las coordenadas X0,Y0, lo que haremos será pintar primero los tiles cuya coordenada Y sea igual a Y0. Luego pintaremos los personajes cuya coordenada Y sea igual a Y0. A continuación pintaremos los tiles cuya coordenada Y sea igual a Y0+1, y seguiremos con los personajes cuya coordenada Y sea igual a Y0+1. Y así sucesivamente.
Veámoslo de manera gráfica:
En el GIF anterior muestra el orden en el que se van pintando los tiles. Vemos que algunos objetos, como las camas, ocupan más de un tile en vertical. Esto es porque tienen altura, y, por tanto, taparán a un personaje que pase por detrás. La única precaución es que deben pintarse algo más arriba. En mi caso, como todos los tiles del suelo tienen 4 caracteres de altura, si al pintar un elemento éste tiene más, lo que hago es pintarlo tantos caracteres hacia arriba como caracteres extra tenga. Así, al pintar la segunda fila de tiles se ve que un elemento es una cama, que tiene una altura de seis caracteres. Por tanto, debe pintarse en la coordenada Y=2 en lugar de la coordenada Y=4, que sería la que le correspondería a un tile de suelo, por ejemplo. Lo mismo ocurre con la esquina de la pared, en la tercera fila de tiles: dado que mide ocho caracteres de alto, se pinta a partir de Y=4 en lugar de Y=8. Vemos que el resultado es que el personaje, efectivamente, resulta tapado parcialmente por la cama que tiene delante, lo que potencia el efecto 3D.
Se puede ver también que en las zonas de una fila que quedarán cubiertas por un tile de la fila siguiente, he utilizado tiles incompletos, justo de los que hablaba antes. Así, en la fila anterior a una cama, he utilizado suelo que es la mitad de alto, y en la fila anterior de la esquina de la pared directamente no he pintado el tile de la baldosa en la zona que irá ocupada por la parte superior.
¿Por qué hago esto? Simplemente para ahorrar procesador. Podría haber pintado la baldosa completa, de 4×4 caracteres y el resultado habría sido exactamente el mismo. Sin embargo, dado que la siguiente fila sobreescribirá partes de la anterior, realmente estaría pintando dos veces una zona de la pantalla, lo que supone tirar a la basura tiempo de procesador (algo de lo que andamos muy justos), y además haciendo justo lo que más tiempo consume: pintando cosas. Por eso creé esas tiles extra de baldosas con dos y una fila sólo, y por eso existe el tile cero, que directamente no pinta nada en esa posición: para ahorrarnos el pintar algo que sabemos que será borrado al pintar la siguiente fila.
Por supuesto, esto puedo hacerlo con las baldosas porque se desde el principio cuales serán cubiertas por el elemento de la siguiente fila y cuanto. En cambio, vemos que el personaje lo pintamos completo porque de él no podemos saber a priori qué partes serán tapadas por otros objetos. En este caso no hay atajos.
Ah, y si notáis diferencias entre los tiles del principio del artículo y los que se ven en la animación de aquí abajo, es porque cambié los colores para darle un poco más de vidilla a los decorados.
En la siguiente entrada veremos el gestor de tareas y la gestión del movimiento de los personajes.
Utilizamos cookies para garantizar que tenga la mejor experiencia en nuestro sitio web.