Como no todo el mundo tiene un emulador de Spectrum a mano, se me ha ocurrido poner una versión de JSSpeccy en mi web con el juego dentro. Para los que no lo conozcan, se trata de un emulador de Spectrum escrito por Matt Westcott en JavaScript y, por tanto, embebible en un navegador. Ahora basta con ir a la página de Escape from M.O.N.J.A.S. y escoger «Juega a la versión en español en tu navegador» (o en inglés, si prefieres), y aparecerá el emulador en tu ventana, al máximo tamaño, y cargará automáticamente MONJAS.
Si vais al repositorio de JSSpeccy que he puesto, veréis que es el mío, y no el oficial. Esto es porque el que subí es un fork que hice para añadirle algunas características extra. Una de ellas es redimensionamiento automático, de manera que ocupe toda la pantalla. Otro cambio fue añadir la emulación del bus flotante, imprescindible para que MONJAS funcione. Había enviado el parche al autor, pero parece que el proyecto está abandonado 🙁
Vamos ahora con el tema de los textos. Pintar letras no es algo demasiado complejo una vez que hemos pintado sprites, por lo que no voy a ahondar demasiado en ello. Sin embargo, sí hay un detalle que no es nada trivial, y es conseguir meter mucho texto en poco espacio. En mi juego Escape from M.O.N.J.A.S. tenía unos 10 kbytes de texto, y tenía el problema de que, sencillamente, no me cabía en la memoria. Sin embargo, el texto tiene la característica de que tiene mucha redundancia, por lo que es muy compresible. Así que decidí intentar ir por esa ruta.
Alguno pensará que comprimir datos en un Z80 a 3,5MHz es una quimera, algo totalmente imposible, por culpa de la poca potencia; sin embargo esto no tiene por qué ser así: hay algoritmos en los que lo complicado es comprimir, pero la descompresión es muy sencilla y rápida.
El algoritmo que utilicé fue el LZSS (cuando hice la primera implementación no sabía que se llamaba así, pero es tan sencillo en concepto que era obvio que tenía que estar ya inventado). La idea es sustituir cada bloque que sea idéntico a otro anterior por un par (offset, tamaño) que apunte a dicho bloque anterior. El ejemplo más típico que se pone es el del poema Green Eggs and Ham, y lo podemos ver explicado en la página de la wikipedia.
En mi caso me aprovecho además de que los caracteres ASCII tienen todos el bit 7 a cero, por lo que puedo utilizar un byte con el bit 7 a uno para indicar que ahí comienza un bloque comprimido. Cada bloque comprimido está formado por dos bytes, y como el bit 7 del primero tiene que estar a uno, eso me deja 15 bits en total para almacenar el offset y el tamaño del bloque. Tras hacer varias pruebas, encontré que para mi cantidad de texto el tamaño óptimo es de tres bits para el tamaño y 12 bits para el offset. Por supuesto, dado que no compensa comprimir bloques de tamaño cero, uno o dos, el valor almacenado será el tamaño menos tres (o sea, entre 3 y 10). Además, el offset será siempre a partir del principio del bloque completo de textos, y no «desplazamiento hacia atrás desde el punto actual». El motivo de esto es que al principio es donde hay más texto sin comprimir, y, por tanto, donde habrá más oportunidades de encontrar repetido texto de más adelante.
Esta implementación tiene varias cosas interesantes. Para empezar, es muy sencilla de implementar, y en segundo lugar, no necesita memoria intermedia para tablas (cosa que otros algoritmos, como el LZW, sí necesitan). Para simplificar aún más el algoritmo, habrá una condición extra: no habrá recursividad (esto es: dentro de un bloque comprimido no habrá otros bloques comprimidos, sino que siempre apuntarán a ristras de caracteres ASCII). Esto tiene el inconveniente de que la compresión es menor, pero simplifica sobremanera el algoritmo y reduce la memoria necesaria para la pila (y dado que trabajamos con threads, interesa que este valor sea lo menor posible).
Lo más interesante de este algoritmo así descrito es que se puede utilizar al vuelo; esto es: podemos ir imprimiendo los caracteres a medida que los vamos descomprimiendo. Y si le sumamos que una cadena ASCII normal es un bloque comprimido válido, tiene la ventaja extra de que podemos utilizar la misma función para imprimir textos «normales», sin comprimir.
Habrá una limitación extra, y es que un bloque comprimido no puede jamás cruzar la frontera entre dos «frases» o «bloques de texto». Esto es fundamental, pues si queremos poder descomprimir al vuelo una frase, necesitamos que empiece en un byte concreto, y no en mitad de un bloque comprimido. Así, si tenemos estas tres frases:
esta es la primera frase la primera frase empieza en esta es la primera que veo
tenemos que respetar las fronteras entre frases y no comprimir el final de la segunda junto con el principio de la tercera en un único bloque, pues entonces no podríamos descomprimir la tercera de manera independiente, sino que tendríamos que descomprimir la segunda antes, almacenando el resultado, y buscar el punto de unión.
Por desgracia, si la descompresión es muy sencilla y rápida, la compresión es endiabladamente fastidiada (con jota). De hecho, por lo que he visto, ni siquiera parece existir un algoritmo óptimo, sino sólo diferentes aproximaciones. Esto puede chocar, pues en apariencia basta con empezar por el principio e ir buscando si el bloque de caracteres que sigue ya está repetido anteriormente. Sin embargo, por sorprendente que parezca, el orden de las frases puede afectar (y mucho) al nivel de compresión obtenido. Veámoslo con este ejemplo:
12345678 12345 345678
Estas tres «frases» se pueden comprimir como
12345678 (0,5) (2,6)
Esto es: la segunda frase es un bloque con los 5 caracteres que hay a partir del offset 0, y la tercera frase es un bloque con los 6 caracteres a partir del offset 2. En total, 12 bytes. Sin embargo, si reordenamos estas frases así:
12345 12345678 345678
tenemos que la compresión será
12345 (0,5)678 (2,3)(7,3)
que consume 14 bytes.
La solución a esto ha sido ir probando a cambiar de sitio una frase de cada vez, recomprimir, y si le nivel de compresión es mejor, guardarlo y volver a probar, mientras que si el cambio es a peor, deshacerlo y probar de nuevo. Una pequeña mejora consiste en no deshacerlo con una probabilidad pequeña (el 0,1%), de manera que sea posible «volver atrás», y que el algoritmo pueda probar otros caminos lejos de un mínimo local, pero siempre conservando en memoria la mejor combinación hallada hasta el momento. Esto tiene el inconveniente de que para conseguir altos niveles de compresión se necesita mucho tiempo (para los textos actuales dejé mi PC trabajando unas 24 horas).
Además, existe otra optimización muy importante, que consiste en intentar comprimir antes los bloques de mayor tamaño, e ir probando luego con los de menor tamaño. Así, dado que el tamaño de un bloque puede ir de 3 a 10 bytes, primero busco todos los bloques de 10 bytes que puedo comprimir; una vez hallados, procedo a buscar en las cadenas sin comprimir que quedan los bloques de 9, luego los de 8, etc. Esto es importante porque puede ocurrir que por comprimir ahora un bloque de 3, más adelante no pueda comprimir un bloque mayor. Aquí tenemos un ejemplo:
12345678 ab456dfg b456df
En este caso, si comprimo en el orden que aparece, tendré
12345678 ab(3,3)dfg b(3,3)(12,3)
que son 20 bytes, mientras que si comprimo por tamaño, tendré:
12345678 ab456dfg (9,6)
que son 18 bytes.
La diferencia entre aplicar o no estas dos optimizaciones en brutal: sin ellas, conseguía una compresión del 68% aproximadamente, mientras que aplicándolas, los textos quedan reducidos a un valor en torno al 59,7%. Una diferencia abismal, que me permitió reducir los más de diez kilobytes originales en unos seis, y que entrase por fin todo en memoria.
El compresor que escribí, además, parte de un fichero en formato assembler normal y saca el mismo fichero también en assembler pero con los datos comprimidos. Eso significa que se conservan las etiquetas, por lo que para descomprimir una frase sólo hay que pasar la etiqueta correspondiente a la rutina de descompresión/impresión, y listo.
Queda, eso sí, un detallito especial, que es qué hacemos con los caracteres específicos del español (la eñe y las aperturas de interrogación y exclamación; las tildes decidí obviarlas). La solución que se me ocurrió fue mapearlas en caracteres por debajo de 127 que no se utilicen, como el asterisco, el porcentaje, etc, reemplazándolos en el juego de caracteres del Spectrum. Por supuesto, para simplificar el trabajo, el compresor también se encarga de esta tarea, por lo que en el código fuente original los textos irán en UTF-8, y el compresor se encargará de sustituir la eñe por el asterisco, etc.
¡Pues por fin ha ocurrido! Tras tres meses de duro trabajo, por fin he terminado mi juego para Spectrum Escape from M.O.N.J.A.S. Ya podéis descargarlo desde la página oficial. Espero que lo disfrutéis.
En la última entrada hablé del gestor de tareas. Sin embargo, desde entonces la cosa ha evolucionado mucho y el código actualmente es algo diferente. En concreto, es este:
old_stack:
DEFW 0
task_pointer:
DEFW 0
task_run:
ld (old_stack), SP
ld iy, task_list
task_loop:
ld a, (iy+0)
and a
jr z, task_end
ld l, (iy+1)
ld h, (iy+2)
ld sp, hl
ld (task_pointer), iy
ret
task_end:
ld sp, (old_stack)
ret
task_yield:
ld iy, (task_pointer)
ld hl, 0
add hl, sp ; get the current stack
ld (iy+1), l
ld (iy+2), h
ld e, (iy+0)
ld d, 0
add iy, de ; jump to next entry
jp task_loop
task_list:
TASK_ENTRY 36, task1
TASK_ENTRY 10, task2
TASK_ENTRY 14, task3
DEFB 0 ; fin de la lista de tareas
El primer cambio es que ahora guardo el valor de IY, de manera que puede modificarse dentro de la tarea sin problemas. El segundo es que ahora, cada tarea puede tener un tamaño de pila diferente, lo que permite ahorrar mucha memoria, pues hay tareas que casi no hacen llamadas anidadas, mientras que otras sí.
El segundo cambio fue crear una macro que simplifica crear la tabla de tareas. Al final, en la etiqueta task_list, tengo una lista de tareas de ejemplo con un total de tres tasks, donde el código de la primera empieza en task1, el de la segunda en task2, y el de la tercera en task3, y sus stacks respectivos tienen un tamaño de 36, 10 y 14 bytes. TASK_ENTRY es una macro con el siguiente formato:
El primer byte indica el tamaño completo de la entrada, que será de tres bytes más que el tamaño de pila que queremos asignar a esta task. Los dos siguientes bytes contienen el valor del registro SP de esta tarea, o sea, el actual puntero de pila. Se inicializa de manera que apunte al final del bloque reservado para la pila. Luego vienen tantos bytes como tamaño de pila queramos menos 2, de manera que reservamos los dos últimos bytes para poner la dirección de inicio de la tarea. De esta manera, cuando se crea la entrada para una tarea, la pila sólo contiene la dirección de inicio de dicha tarea, y el puntero de pila apunta justo a ella.
Por último, añadí una función optativa para depurar las tareas. Es ésta:
ld hl, (task_pointer)
inc hl
inc hl
inc hl ; jump over the size and the stored SP pointer
ld d, 0
task_check_size:
ld a, (hl)
and a
jr nz, task_end_check_size
inc d
inc hl
jr task_check_size
task_end_check_size:
ld a, d
ld SP, (old_stack)
call do_debug
Este bloque se puede ejecutar justo después de que una tarea haya vuelto (llamando a task_yield), y lo que hace es comprobar cuanto espacio se ha llegado a ocupar en la pila. Para ello se basa en que el bloque de la pila se inicializó a cero, y que cuando se saca un valor de la pila sólo se incrementa SP, pero el valor sigue estando ahí. De esta manera, si vemos cuantos bytes seguidos cuyo valor sea cero hay desde el principio, sabremos hasta donde ha llegado a crecer la pila. Si este tamaño es cero significa que esa pila se ha llenado del todo en algún momento (y hasta es posible que haya sobreescrito alguna posición extra), por lo que en ese caso hay que aumentar el tamaño.
La llamada a CALL do_debug se supone que muestra, de alguna manera, el contenido del registro A.
Qué pinta tiene
Pues el juego ya lo he terminado y ahora mismo estoy puliendo los textos y la traducción al inglés, y los petatesters están buscando los bugs y pifias varias. Pero tiene esta pinta:
El siguiente paso es implementar la lógica del juego. Se trata de la parte del código que hace que funcionen las cosas como deben funcionar. Por ejemplo, se encarga de mover al personaje principal y a los secundarios, animar objetos, etc. Este código se ejecutará justo después de que hayamos pintado todos los gráficos en el buffer secundario y mientras esperamos a que comience el barrido de un nuevo frame.
Esta parte se divide, al menos de momento, en dos piezas de código: una que actualiza la posición de cualquier personaje, y otra que ejecuta las distintas tareas o tasks.
Movimiento de personajes
Dado que los personajes están animados, es necesario tener en cuenta en qué posición se encuentran en cada momento, si están ya donde deben estar o no, la fase de la animación, etc. Además, para ahorrar memoria, tenemos por un lado el cuerpo en sí y por otro las piernas, siendo estas últimas la única parte animada realmente. Eso significa que cada personaje está compuesto realmente por dos sprites, pero sólo uno es el que tiene secuencias de animación. Además, cada bloque está repetido en espejo, para cuando el personaje tiene que moverse hacia el lado opuesto.
Sprites que forman a un personaje. Arriba están los dos cuerpos, uno para cada lado, y debajo de cada uno están las secuencias de animación de las piernas que corresponden a cada uno de los dos cuerpos.
Cada personaje está definido en una estructura como la siguiente:
DEFB 0x01 ; bit 0: 1-> es el personaje principal
; bit 1: 1-> es un personaje secundario
; bit 2: 1-> está caminando; 0-> no camina
; bit 5: 1-> mira hacia la izquierda; 0-> a la derecha
; bit 6-7: etapa de animación
; si el byte vale cero, es FIN DE LA TABLA
DEFB NOWX ; coordenada X actual
DEFB NOWY ; coordenada Y actual
DEFB DESX ; coordenada X final
DEFB DESY ; coordenada Y final
DEFW sprites_table ; puntero al sprite para el cuerpo
DEFW (sprites_table + 6) ; puntero al sprite para los pies
Vemos que tenemos, por un lado, la etapa actual de la animación y a qué lado está mirando actualmente el personaje, por otro lado dos juegos de coordenadas, y por último dos punteros a dos entradas de la tabla de sprites, uno apuntando a la entrada que muestra el cuerpo del personaje y otra que apunta a la entrada de las piernas. Cuando queremos que un personaje camine desde donde está actualmente (cuyo valor está almacenado en NOWX, NOWY) hasta otro sitio, debemos simplemente escribir las coordenadas de destino en DESX, DESY, y la rutina de movimiento de personajes se encargará del resto. Esta rutina se ejecuta justo después de pintar todo el buffer secundario, y lo que hace es comparar la coordenada X actual con la X final, y lo mismo con la Y. Si son iguales, pondrá el bit 2 a 0 para indicar que el personaje está en su destino y pasará a la siguiente entrada. Sin embargo, si alguna de las dos coordenadas actuales no es igual a su homóloga final, la rutina le sumará o restará 1, en función de lo que sea necesario para acercar al personaje a su posición final. A continuación copiará las coordenadas actuales en cada una de las dos entradas de la tabla de sprites. Luego incrementará en uno la etapa de animación, y en base al valor de ésta decidirá qué sprite concreto se mostrará para los pies (modificando para ello la entrada correspondiente de la tabla de sprites), además de ajustar la coordenada Z (porque nuestros personajes se mueven a saltos). Tras hacer todo esto, saltará a la siguiente entrada de la tabla y repetirá estas operaciones hasta llegar al final.
Vemos, pues, que esta rutina nos simplifica mucho el mover un personaje desde una zona del mapa hasta otra, pues sólo tenemos que poner las coordenadas finales y esperar a que el bit 2 cambie de 1 a 0 para saber que ha llegado.
Gestor de tareas
La rutina anterior nos ayuda un poco, pero todavía nos queda por implementar absolutamente toda la lógica del juego en sí. La primera idea consiste en escribir una función que se llame justo después de terminar de actualizar las posiciones de los personajes (esto es, justo des pués de la rutina anterior), y que, en base al estado actual del juego (donde está el protagonista, el resto de personajes, los objetos, etc) decida cual debe ser el nuevo estado (donde estará el protagonista y el resto de personajes, si algún objeto aparece o desaparece…), tras lo cual se pintará de nuevo el mapa y se repetirá el proceso.
Por desgracia, hacer algo así complica sobremanera la tarea, y además hace que cualquier cambio que se quiera hacer pueda afectar a otras partes, por lo que el código probablemente quedaría muy complejo. Por eso decidí seguir la idea que Ron Gilbert y compañía utilizaron en Scumm, la máquina virtual que desarrolló para el juego Maniac Mansion: permitir crear múltiples tareas que se ejecuten en paralelo y de manera independiente.
La idea básica es que cada personaje u objeto se maneje desde una tarea independiente, y que como mucho se añadan puntos de sincronización entre ellas. Las tareas se ejecutan mediante multitarea cooperativa, y se ejecutan una vez por frame del juego. Cuando una tarea ha terminado de hacer lo que tenga que hacer, simplemente tiene que hacer una llamada a una subrutina concreta para avisar, cediendo el control a la siguiente. Cuando todas las tareas se han ejecutado, se pintará el siguiente frame, se actualizará la posición de los personajes, y volverán a ejecutarse las tareas una a una, pero con el detalle de que cada una continuará su ejecución justo donde se quedó en el frame anterior, y además la pila o stack conservará todos los valores que la tarea hubiese almacenado en su ejecución previa.
Veamos cómo es la implementación:
task_list:
DEFW $+TASK_DATA_SIZE+2
DEFS TASK_DATA_SIZE
DEFW tarea1
DEFW $+TASK_DATA_SIZE+2
DEFS TASK_DATA_SIZE
DEFW tarea2
DEFW 0 ; fin de la tabla de tareas
task_run:
ld (old_stack), SP ; preservamos la pila global
ld iy, task_list
task_loop:
ld l, (iy+0)
ld h, (iy+1)
ld a, h
or l
jr z, task_end
ld sp, hl ; asignamos a SP la pila de la tarea a ejecutar
ret ; y saltamos al código de la tarea
task_yield:
ld hl, 0
add hl, sp ; almacena en HL el stack actual
ld (iy+0), l
ld (iy+1), h ; y lo guarda en la entrada de la tabla de tareas
ld de, TASK_ENTRY_SIZE
add iy, de
jr task_loop ; siguiente entrada de la tabla de tareas
task_end:
ld SP, (old_stack) ; restauramos la pila global
ret
Vemos que la tabla está dimensionada para dos tareas, y cada entrada de la tabla de tareas está compuesta de dos partes:
Los dos primeros bytes contienen la dirección de la pila o stack de esta tarea (recordemos que $ es «la dirección de esta línea»)
El resto de bytes es donde se almacena la pila o stack de esta tarea, con un total de TASK_DATA_SIZE+2 bytes
Vemos que en el código que puse arriba, los dos primeros bytes apuntan a los dos últimos bytes del bloque de la pila de cada tarea, y éstos contienen la dirección de entrada del código de cada tarea. De esta manera, lo que hacemos es inicializar la pila de cada tarea de manera que contenga un único dato: la dirección inicial de entrada para esa tarea.
Si nos vamos al código que viene justo a continuación, vemos que el punto de entrada es task_run. Esta es la función que se llama cada vez que se ha terminado de pintar un frame. Vemos que lo primero que hace es guardar la dirección del stack. Esto es necesario porque vamos a modificarlo para cada tarea, por lo que cuando terminemos, necesitaremos restaurarlo al valor inicial, o no podremos retornar.
A continuación cargamos en IY la dirección inicial de la tabla de tareas, pues vamos a utilizar dicho registro índice para recorrerla. Las tareas no deben modificar este registro bajo ninguna circunstancia.
Entramos ahora en el bucle principal, en el que simplemente tomamos los dos primeros bytes, vemos si ambos valen cero (lo que significaría que hemos llegado al final de la tabla), y si no es así, cargamos su valor en SP.
Ahora el puntero de pila apunta a la pila de la primera tarea, y si recordamos cómo inicializamos la tabla de tareas, el valor que hay en ella será la dirección de inicio de dicha tarea, con lo que al hacer un RET, el procesador sacará ese valor de la pila y saltará a él.
Ahora la primera tarea empezará a ejecutarse. Hará todo lo que tenga que hacer, y cuando haya terminado, simplemente hará un CALL task_yield. Esto significa que ahora la pila de la tarea ya no contiene la dirección inicial, sino justo la dirección desde la que se hizo esa llamada, lo que significa que cuando volvamos a llamar a task_run tras el siguiente frame, al ejecutar el RET se saltará justo a la siguiente instrucción tras el CALL en lugar de al principio, por lo que la tarea continuará su ejecución justo en el punto en el que lo dejó.
En task_yield vemos que lo que hacemos es almacenar el valor de SP en los dos primeros bytes de la entrada de la tabla de tareas. Esto es necesario porque la tarea podría haber almacenado algún valor antes de llamar a task_yield, lo que significa que la dirección de retorno ya no está al final de la pila, sino antes.
Tras ello, sumamos a IY el tamaño de una entrada de la tabla de tareas para así saltar a la siguiente, y repetimos el proceso hasta llegar al final de la tabla.
Veamos un ejemplo de una tarea, en concreto la que gestiona el movimiento del personaje amarillo:
task2:
ld ix, entrada_en_tabla_de_personajes
task2b:
ld (ix+3), 40
ld (ix+4), 42 ; cargamos las nuevas coordenadas a donde debe ir
call task_wait_for_walk ; esperamos a que llegue
ld (ix+3), 28
ld (ix+4), 34 ; cargamos las nuevas coordenadas a donde debe ir
call task_wait_for_walk ; esperamos a que llegue a su destino
jr task2b
task_wait_for_walk:
push ix ; guardamos en la pila el personaje
call task_yield ; y cedemos el control
pop ix ; en el siguiente frame, recuperamos el personaje
bit 2, (ix+0) ; vemos si está caminando
ret z ; está parado? retornamos
jr task_wait_for_walk ; y si aún no llego al destino, repetimos
Vemos que lo primero que hacemos es cargar en IX la dirección de la tabla de personajes correspondiente al personaje amarillo, y justo a continuación entramos en el bucle principal.
El personaje, al arrancar el programa, está en las coordenadas 28,34 (pues así lo definimos en la tabla de personajes, no por otra cosa), así que lo que hacemos es poner 40,42 como coordenadas de destino, y llamamos a task_wait_for_walk. Esta función, como vemos, lo primero que hace es preservar IX y devolver el control para que se ejecuten el resto de tareas y se repinte la pantalla. Cuando, en el siguiente frame, se ejecute de nuevo esta tarea, la ejecución comenzará justo en el POP situado después de la llamada a task_yield. Ningún registro se ha preservado, pero la pila sí se conserva, así que retiramos el valor de IX y comprobamos su bit 2 (que es el que nos dice si aún está caminando para llegar a las nuevas coordenadas, o si ya ha llegado). En este caso todavía no habrá llegado, por lo que volvemos a guardar IX en la pila y cedemos de nuevo el control. Así hasta que, tras varios frames, por fin el bit vale cero, momento en el que directamente retornamos al código que llamó a task_wait_for_walk. Y como ahora ya estamos en 40,42, lo que hacemos es poner ahora como destino 28,34 de nuevo y esperar a que llegue a su destino. De esta manera el personaje lo que hará será caminar desde 28,34 hasta 40,42 y vuelta, una y otra vez.
Vemos que el hecho de que la pila y las direcciones de retorno se conserven simplifica muchísimo el trabajo, pues el código de la tarea puede ceder el control para esperar a que todo el sistema avance sabiendo que continuará ejecutándose en el mismo punto como si nada hubiese pasado. Bueno, o casi nada, pues es cierto que los registros no se conservan entre llamdas a task_yield. Pero para eso basta con que la rutina preserve en la pila todo lo que necesite.
Por supuesto, esto significa que hay que dejar espacio suficiente en la pila para todos los registros que se quieran preservar a la vez, además de todas las direcciones de retorno… ¡y una dirección extra! Pues nos interesa que las interrupciones estén habilitadas mientras ejecutamos las tareas, porque de esta manera podemos aprovechar para ejecutarlas un tiempo que, si no usásemos interrupciones, simplemente tiraríamos a la basura; pero eso significa que puede metersenos un dato extra en la pila con el que, a lo mejor, no contábamos al dimensionarla.
Adaptando la ISR
Por desgracia, esto nos supone un problema extra, pues la ISR tiene que guardar en la pila todos los registros que vaya a utilizar. Esto significa que si dejamos nuestro código tal cual, necesitaríamos reservar en la pila de cada tarea el espacio suficiente para guardar no sólo todos los datos de la tarea, sino también 22 bytes extra, los necesarios para guardar la dirección de retorno de la interrupción y los diez pares de registros del procesador que utilizamos en la ISR (AF, BC, DE, HL, AF’, BC’, DE’, HL’, IX e IY).
Hacer esto sería un verdadero desperdicio de memoria, así que la solución es tan sencilla como reservar una zona de 22 bytes extra en memoria, y nada más entrar en la ISR, guardar el valor de SP al principio de esa zona, cambiarlo para que apunte al final más uno (recordemos que PUSH primero decrementa y luego almacena) del bloque, y sólo entonces guardar los diez pares de registros. Al salir, por supuesto, tras restaurar los registros hay que restaurar también SP, y sólo entonces retornar.
En la próxima entrada hablaré de la impresión de textos.
En la entrada anterior se me olvidó comentar un detalle extra, que es la tabla de sprites. Esta tabla contiene la información de cualquier sprite que no sea «de fondo»; esto es: todo sprite que vaya a ser animado, o que pueda aparecer o desaparecer, o moverse de sitio, y que, por tanto, no esté definido en el mapa sino que deba pintarse aparte. Estos sprites, al no ser parte del decorado en sí, no pueden almacenarse en la tabla del mapa que vimos antes (la que define las paredes, suelo y objetos fijos), sino que deben definirse aparte.
El primer ejemplo de este tipo de objetos son los propios sprites de los personajes: desde el momento en que éstos se pueden mover de un lado para otro es necesario que no formen parte del mapa. Otro ejemplo son todos los objetos que el protagonista puede coger o dejar, pues éstos aparecerán o desaparecerán del mapa, y también pueden cambiar de lugar en función de donde los deje el jugador. Por último, cualquier objeto animado, como por ejemplo los personajes, o una olla al fuego que hace chup, chup…
La tabla de sprites tiene el siguiente formato:
DEFB 5 ; coordenada Z
; si 255-> esta entrada está vacía
; si 254-> fin de la tabla
DEFB 40 ; coordenada X en el mapa
DEFB 32 ; coordenada Y en el mapa
DEFB 0x58 ; color de sustitución
DEFW sprite_base_right ; puntero al sprite-en-sí
En primer lugar tenemos la coordenada Z o de altura. Este byte tiene dos valores especiales: si vale 254 nos indica que es el final de la tabla y, por tanto, que no hay más sprites. Si vale 255 significa que esta entrada nos la debemos saltar porque está vacía. Esto es útil para objetos que pueden aparecer y desaparecer del mapa: cuando no está visible ponemos esta entrada a 255, y no se pintará; cuando vuelva a ser visible, la ponemos al valor de Z correcto.
Justo después están las coordenadas X e Y. La coordenada Y es fundamental a la hora de pintar el mapa. En efecto, si recordamos, cuando pintábamos el mapa lo hacíamos desde las coordenadas Y más bajas (que quedan «arriba» de la pantalla) hacia las más altas. Pues bien: cada vez que se pinta una fila completa del mapa, se recorre la tabla de sprites en busca de todos aquellos cuya coordenada Y coincida con la fila que acabamos de pintar. Si encontramos un sprite que cumpla esta condición, calculamos la coordenada Y de pantalla restando de su coordenada Y la coordenada Z (de manera que cuanto más «alto» esté en Z, más arriba aparecerá en pantalla, pero tapando todos los elementos del mapa que se encuentran antes que la Y del sprite). Es justo esto lo que nos permite simular el efecto 3D, en el que los objetos pueden moverse en los tres ejes, y ocluyendo (o tapando) todo lo que se encuentra detras.
El siguiente byte es el color de sustitución: en mi juego quiero que haya varios personajes, pero todos van a estar hechos con el mismo sprite, así que para distinguirlos cada uno tendrá un color diferente. La manera más sencilla de implementar esto obligaría a tener un conjunto de atributos de color diferente para cada sprite, lo que supondría un consumo excesivo de memoria. Así que decidí que los sprites que tienen máscara de transparencia (lo que incluye al sprite de los personajes) pueden marcar bloques de atributos para que sean sustituidos por este color. Para ello sólo tienen que activar el bit de FLASH y el de BRIGHT a la vez en un atributo concreto, y ese será sustituido por este valor. En cambio, si sólo marca el bit de FLASH, entonces simplemente no se escribirá ese atributo de color concreto, con lo que el color que se utilizará será el que ya había debajo. Esto permite conseguir también «transparencia» con los colores.
Así, en el caso del sprite del personaje, todas las zonas del traje tienen los bits de FLASH y de BRIGHT activos, lo que significa que el color que definí en el editor no se utilizará para esas zonas, sino éste que he definido aquí. Eso es lo que permite tener varios personajes, cada uno de un color diferente, sin consumir memoria extra para meter cada uno.
Por último, tenemos un puntero a los datos del sprite en sí. Esto se hace así para poder cambiar el puntero y, de esta manera, poder animar el sprite si se desea. Por ejemplo, si tenemos dos sprites de una olla que forman una animación, lo que haremos será ir cambiando la dirección del puntero de datos en la entrada de la tabla de sprites de manera que vaya alternando a cual de los dos apunta.
Llega el momento de hacer el mapa. Para ello tenemos que recordar que el Spectrum no tiene la capacidad de memoria de los ordenadores actuales, lo que significa que no podemos crear pantallas a lo bruto y guardarlas tal cual, sino que tenemos que buscar la manera de guardarlas comprimidas, para que ocupen lo menos posible. Una técnica habitual es utilizar tiles o losetas para crear las pantallas. En ellas, lo que se hace es generar un número pequeño de gráficos, y combinándolos y repitiéndolos de distintas maneras podemos crear multitud de estancias de un mapa ocupando muy poca memoria. Veamos un ejemplo con un trozo de mapa:
Vemos que hay varios elementos repetitivos, como por ejemplo las losetas del suelo; pero en realidad todo está colocado en base a una cuadrícula de elementos de 4×4 caracteres. Las posibles losetas que, de momento, se utilizan en el mapa son las siguientes:
Así, por un lado tenemos las definiciones de las diferentes losetas, y por otro la definición del mapa en sí. En esta última estructura lo único que tenemos que almacenar es qué loseta va en cada posición. Dado que la pantalla mide 32×24 caracteres, y cada posición de loseta mide 4×4 caracteres, tenemos que cada pantalla del mapa ocupará 8×6 = 24 bytes (si sólo empleamos un byte por loseta, claro). Por supuesto, las losetas en sí ocupan más memoria: en este caso, cada loseta de 4×4 caracteres ocupa 128 bytes de píxeles más 16 bytes para atributos de color; en total 144 bytes. Pero la ventaja es que una misma loseta se puede reutilizar varias veces en múltiples pantallas, por lo que el ahorro es muy grande. En la pantalla de arriba vemos que el grueso lo ocupa la loseta superior izquierda, y que las paredes de la izquierda y de arriba están hechas fundamentalmente con dos losetas concretas.
Pintando el mapa
Ahora que expliqué la base, voy a comentar algunos detalles de mi implementación. En primer lugar, las losetas mostradas arriba no tienen máscara de transparencia (con la excepción de la puerta vertical… ya lo explicaré luego). El motivo es que las losetas se utilizan para pintar el fondo de la pantalla, por lo que, dado que no hay nada debajo, no hace falta que tengan transparencia. Esto significa que, a la hora de pintarlas, tengo que tenerlo en cuenta. La primera idea sería poner una comprobación dentro del bucle que copia cada byte de un sprite al buffer de vídeo, pero tiene el inconveniente de que estamos comprobando lo mismo una y otra vez en todos los bytes que copiamos. Como vimos en las primeras entradas, pintar gráficos en pantalla consume mucho tiempo porque hay que copiar una cantidad ingente de bytes, y cualquier pequeño ahorro dentro del bucle supone un aumento brutal del rendimiento, pues se multiplica por los más de seis kilobytes que hay que copiar en cada frame. Es por esto que sólo hago una comprobación justo antes de entrar en el bucle externo (el que pinta las filas), y en función de si el sprite tiene o no máscara, voy a una rutina u otra. La rutina que pinta con máscara ya la vimos en la entrada número 6, así que pondré a continuación únicamente la rutina que pinta sin máscara. Partimos de HL apuntando al sprite, de DE conteniendo la dirección de destino, calculada a partir de las coordenadas, y de BC conteniendo el alto en scanlines y el ancho en caracteres (esos datos los obtenemos con el código común con la rutina que pinta con máscara):
ld A, C ; guardamos el número de columnas en A
push DE
push BC
ld B, 0
exx
pop BC ; pasamos el número de filas al juego alternativo de registros
pop IX ; y la dirección de destino a IX
ld DE, 32 ; valor a sumar para saltar al siguiente scanline
loop1:
exx
ld D, IXh
ld E, IXl ; la pasamos al conjunto de registros principal
ld C, A ; B vale cero, así que LDIR copiará A bytes
ldir ; copiamos una fila
exx
add IX, DE ; saltamos al siguiente scanline
djnz loop1
Esta rutina tiene la ventaja de que es mucho más rápida que la que utiliza máscaras, gracias a que se basa en LDIR. Así, cada byte necesita sólo 23 Testados frente a los 61 que necesitábamos en la rutina con máscaras, lo que es un gran ahorro, y más si nos aseguramos de que el máximo número posible de tiles no usan máscara, la cual la reservaremos sólo para los personajes y objetos móviles, pues ellos sí queremos que se muevan «por encima» de lo que ya está pintado, y para algún tile muy concreto.
Una vez que tenemos ya esta rutina, toca almacenar el mapa. La idea consiste en almacenar un array de bytes. En mi juego no voy a utilizar una distribución clásica de pantallas en la que el personaje se mueve por dentro de la pantalla, y cada vez que sale, la pantalla se borra y se pinta una nueva. En mi caso el personaje estará quieto en el medio de la pantalla, y todo el mapa se moverá a derecha, izquierda, arriba o abajo. Esto significa que, al no haber fronteras definidas, todo el mapa será un solo bloque. Este es el mapa de demostración que hice:
El mapa mide 32 tiles (256 caracteres) de ancho. Esto lo hice porque es el máximo valor que se puede almacenar en un byte para las coordenadas, y porque para multiplicar por el ancho sólo hay que rotar cinco veces el valor, lo que es una operación fácil y rápida. Por otro lado, he decidido que si un valor tiene el bit 7 a uno, significa que el personaje no puede pisar esa loseta. Así, las paredes, mesas, camas, etc. tendrán dicho bit a 1 para evitar que el personaje las atraviese, y sólo las losetas normales tendrán dicho bit a 0.
La correspondencia de cada número es como sigue:
; 0 -> no pintar
; 1 -> suelo normal
; 2 -> suelo roto
; 3 -> suelo con rejilla
; 4 -> minisuelo (suelo con una única línea, para muros horizontales)
; 5 -> muro vertical
; 6 -> muro horizontal
; 7 -> cruce de muros
; 8 -> parte superior de puerta vertical
; 9 -> parte inferior de puerta vertical
; A -> suelo exterior
; B -> minisuelo exterior (single-line)
; C -> muro en T superior
; D -> muro en T inferior
; E -> esquina inferior izquierda
; F -> esquina inferior derecha
;10 -> esquina superior izquierda
;11 -> esquina superior derecha
Los elementos 0, 4 y B pueden parecer extraños, pero tienen sentido para aquellas losetas que estarán tapadas por otras losetas que midan más de 4×4 caracteres. De hecho, comparemos la loseta 1 con la 4 y la B:
Vemos que son básicamente iguales, salvo porque la 4 y la B son más pequeñas verticalmente. El motivo de que existan estas losetas es que pintar un sprite supone una carga de procesador muy elevada, pues hay que copiar muchos bytes de un lado para otro, por lo que si podemos ahorrar pintar algunos bytes, mejor. Para entenderlo mejor, veamos cómo compongo el mapa para dar, además, apariencia 3D.
Pintando en pseudo3D
La vista del mapa pretende ofrecer un pseudo3D. Al contrario que otros sistemas, como por ejemplo las vistas isométricas, donde la coordenada X e Y de la pantalla sale de una combinación lineal de las coordenadas X, Y y Z de cada objeto, en este sistema la coordenada X de la pantalla es simplemente la misma que la del objeto, y la coordenada Y es la Y del objeto menos la Z. Sin embargo, esto es sólo parte del problema del pintado. La otra parte es decidir el orden en que hay que pintar los objetos para asegurarse de que el efecto pseudo3D es consistente: por ejemplo, que si un personaje pasa por detrás de una mesa o de una pared, quede parcialmente oculto. Para ello es necesario pintar todos los elementos en un orden concreto: de atrás hacia adelante, de manera que los objetos que están más cercanos vayan tapando lo que hay detrás. En el sistema que he escogido esto es muy sencillo: cuanto mayor sea la Y del objeto, más «abajo» en la pantalla estará y, por tanto, habrá que pintarlo más tarde.
Sabiendo esto, el proceso es muy sencillo: si queremos pintar el mapa desde las coordenadas X0,Y0, lo que haremos será pintar primero los tiles cuya coordenada Y sea igual a Y0. Luego pintaremos los personajes cuya coordenada Y sea igual a Y0. A continuación pintaremos los tiles cuya coordenada Y sea igual a Y0+1, y seguiremos con los personajes cuya coordenada Y sea igual a Y0+1. Y así sucesivamente.
Veámoslo de manera gráfica:
En el GIF anterior muestra el orden en el que se van pintando los tiles. Vemos que algunos objetos, como las camas, ocupan más de un tile en vertical. Esto es porque tienen altura, y, por tanto, taparán a un personaje que pase por detrás. La única precaución es que deben pintarse algo más arriba. En mi caso, como todos los tiles del suelo tienen 4 caracteres de altura, si al pintar un elemento éste tiene más, lo que hago es pintarlo tantos caracteres hacia arriba como caracteres extra tenga. Así, al pintar la segunda fila de tiles se ve que un elemento es una cama, que tiene una altura de seis caracteres. Por tanto, debe pintarse en la coordenada Y=2 en lugar de la coordenada Y=4, que sería la que le correspondería a un tile de suelo, por ejemplo. Lo mismo ocurre con la esquina de la pared, en la tercera fila de tiles: dado que mide ocho caracteres de alto, se pinta a partir de Y=4 en lugar de Y=8. Vemos que el resultado es que el personaje, efectivamente, resulta tapado parcialmente por la cama que tiene delante, lo que potencia el efecto 3D.
Se puede ver también que en las zonas de una fila que quedarán cubiertas por un tile de la fila siguiente, he utilizado tiles incompletos, justo de los que hablaba antes. Así, en la fila anterior a una cama, he utilizado suelo que es la mitad de alto, y en la fila anterior de la esquina de la pared directamente no he pintado el tile de la baldosa en la zona que irá ocupada por la parte superior.
¿Por qué hago esto? Simplemente para ahorrar procesador. Podría haber pintado la baldosa completa, de 4×4 caracteres y el resultado habría sido exactamente el mismo. Sin embargo, dado que la siguiente fila sobreescribirá partes de la anterior, realmente estaría pintando dos veces una zona de la pantalla, lo que supone tirar a la basura tiempo de procesador (algo de lo que andamos muy justos), y además haciendo justo lo que más tiempo consume: pintando cosas. Por eso creé esas tiles extra de baldosas con dos y una fila sólo, y por eso existe el tile cero, que directamente no pinta nada en esa posición: para ahorrarnos el pintar algo que sabemos que será borrado al pintar la siguiente fila.
Por supuesto, esto puedo hacerlo con las baldosas porque se desde el principio cuales serán cubiertas por el elemento de la siguiente fila y cuanto. En cambio, vemos que el personaje lo pintamos completo porque de él no podemos saber a priori qué partes serán tapadas por otros objetos. En este caso no hay atajos.
Ah, y si notáis diferencias entre los tiles del principio del artículo y los que se ven en la animación de aquí abajo, es porque cambié los colores para darle un poco más de vidilla a los decorados.
En la siguiente entrada veremos el gestor de tareas y la gestión del movimiento de los personajes.
Estaba buscando una buena fuente tipográfica para mi juego, y encontré esta página con más de trescientas… ¡Una maravilla! Y están disponibles en formato ASM, para integrar en el código.
Por otro lado, aunque al principio comenté que estaba utilizando Z80ASM, encontré algunos bugs, así que he cambiado al ensamblador PASMO, que funciona mejor y tiene algunas opciones extra muy interesantes, como generar un .TAP.
Llevo varios días implementando el moverme por el mapa del juego con libertad, y cada vez me daba más rabia ver las cuatro filas inferiores desaprovechadas. No podía evitar preguntarme si realmente no era posible conseguir hacer scroll a todo color a pantalla completa. El problema es que para ello, es imprescindible poder copiar todo el buffer intermedio (donde vamos pintando «con calma» las cosas) en la pantalla antes de que nos alcance el haz. Si recordamos los cálculos de los primeros capítulos, la cosa estaba bastante justa, así que al final decidí utilizar la rutina con la tabla de 192 entradas, la que me permite usar hasta 23 filas sin tearing, pero pintando las 24. Por que se viese un poco abajo de todo, tampoco sería un desastre.
Sin embargo el efecto era bastante exagerado, lo que no me gustaba. Pero a la vez yo se que mi emulador FBZX, el que uso para las pruebas, no es completamente preciso, a pesar de todos mis intentos, así que decidí pedir a algunos compañeros de Zona de pruebas que me hiciesen el favor de probar el código en un Spectrum real. Y lo sorprendente es que la última línea se veía perfecta.
Demasiado perfecta.
Era muy raro… TENÍA que notarse algo en la última fila, pero no… era perfecta. ¿Qué estaba pasando?
Me recomendaron entonces que probase con Es.pectrum, un emulador muy preciso que, además, tiene un depurador y es capaz de mostrar por donde va el barrido, paso a paso. Aunque es para Windows, funciona en wine, así que le di un tiento… y me quedé alucinado de la maravilla de depurador.
Rápidamente cargué mi código y lo probé, y efectivamente, se veía maravillosamente bien, así que fui al depurador, puse un punto de ruptura al comienzo de los LDIs de copia del buffer, lo lancé, fui viendo cómo se pintaba la pantalla y… ¡¡¡El volcado necesitó dos barridos y medio de pantalla, cuando debería haber sido bastante menos de dos!!!
Aquello no tenía ningún sentido: ni aún suponiendo que todas las filas sufriesen contienda podía ocurrir aquello, era demasiado tiempo de más.
Decidí poner un punto de ruptura en cada uno de los LDIs de una fila, a ver qué sacaba en claro, y comencé a ejecutar. Y entonces me encontré con algo rarísimo: cada LDI tardaba 24 Testados en ejecutarse. ¿Por qué, si se supone que dura 16? Podría tener sentido que el primer LDI de los 32 tardase más porque sufriese contienda, pero el resto tenían que encajar exactamente en cada hueco que dejaba la ULA, pues 16 es múltiplo de 8.
No entendía qué significaba, así que le di vueltas y vueltas hasta que, de pronto, caí: LDI es una instrucción de dos bytes (prefijo + código de instrucción). Los prefijos, al igual que los códigos de instrucción, necesitan 4 ciclos de reloj para leerse desde la memoria, de ahí pc:4, pc+1:4: el bus de direcciones contiene la dirección del contador de programa, PC, durante cuatro ciclos de reloj (para leer el prefijo), y luego, durante otros cuatro ciclos, el valor PC+1, cuando lee la instrucción en sí. Luego se lee el byte a copiar, y como es una lectura de un dato, sólo necesita tres ciclos, de ahí hl:3: el valor de HL aparece en el bus de direcciones durante tres ciclos de reloj. A continuación se escribe el byte en el destino en la dirección contenida en el par de registros DE, lo que también consume tres ciclos de reloj, de:3. Y ahora viene la clave: 4+4+3+3=14 ciclos de reloj. Pero la instrucción consume 16. ¿Qué pasa con esos dos ciclos extra? Pues son los necesarios para incrementar HL y DE y decrementar BC. La cuestión, y esta es la clave, es que durante ese tiempo el bus de direcciones conserva el valor de DE, y si recordamos, DE apunta a una dirección de memoria de pantalla, por lo que se verá afectado por la contienda.
El motivo de que DE continúe en el bus de direcciones es que, dado que este bus es sólo de salida, no es necesario ponerlo en tercer estado, por lo que cada vez que se pone un valor, éste permanece, y solo cambia cuando es sobreescrito por un nuevo valor.
¿Y por qué el mero hecho de que haya una dirección de pantalla en el bus es suficiente para disparar el mecanismo de contienda? Para saberlo, vamos a explicar cómo funciona dicho mecanismo.
Recordemos que el objetivo original del Spectrum es que fuese barato. Ese era EL factor clave que condicionaba absolutamente todo el diseño, por lo que la ULA no podía contener circuitos muy complejos sino que tenía que ser lo más simple posible (y así poder utilizar el modelo más barato posible de los que ofertaba Ferranti).
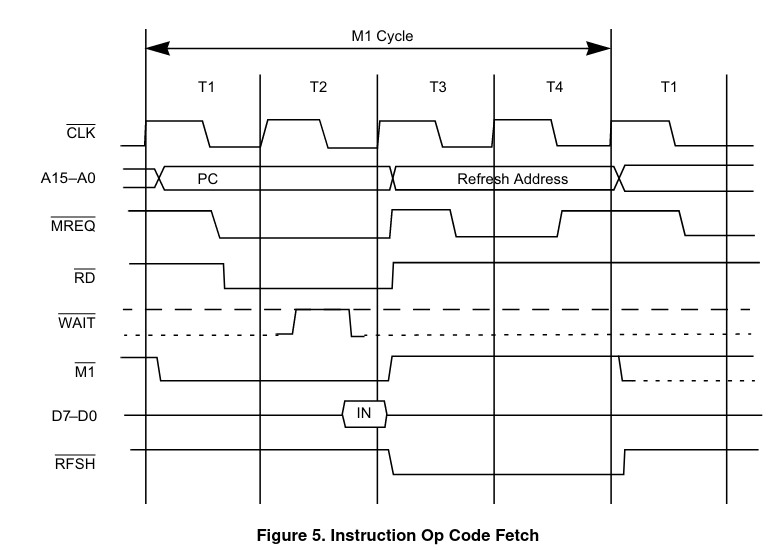
Fijémonos primero en cómo es un acceso a memoria del Z80 si queremos leer una instrucción:
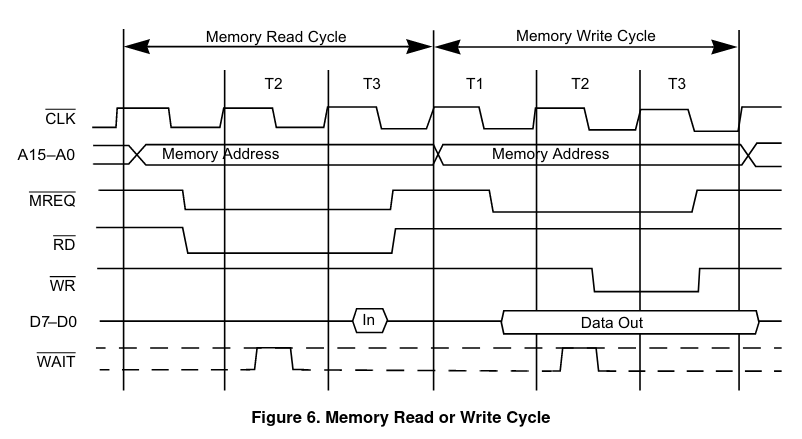
Comparémoslo ahora con el acceso a RAM para leer o escribir un byte «en general» (por ejemplo cuando leemos un dato inmediato, o un dato de la RAM… cualquier cosa que no sea el bytecode de una instrucción):
Vemos que en ambos casos, el Z80 comienza poniendo en el bus de direcciones la dirección de memoria a la que quiere acceder, muy poquito después del flanco de subida del primer ciclo de reloj, y no es hasta inmediatamente después del flanco de bajada de ese mismo ciclo que el procesador pone a cero la línea MREQ para indicar que va a realizar un acceso a memoria, para así dar tiempo a que las tensiones en el bus de direcciones se estabilicen y evitar transitorios. Además, vemos que la única diferencia práctica entre un acceso a memoria «normal» o uno para «instrucción» es que en el primer caso el dato se lee durante el flanco de bajada situado a la mitad del tercer ciclo, mientras que el segundo se lee durante el flanco de subida situado entre el segundo y tercer ciclo.
¿Y cómo aprovecha esto la ULA para realizar la contención? Pues básicamente lo que hace es vigilar constantemente el bus de direcciones, de manera que si durante la parte alta de un ciclo de reloj el bit A15 es cero y el bit A14 es uno, considera que se va a realizar un acceso a memoria de vídeo y activa el mecanismo de contención. Si estamos en alguno de los dos ciclos de reloj en los que el acceso está permitido, entonces no pasa nada y el procesador accede normalmente, accediendo al dato entre un ciclo y medio y dos ciclos más tarde; pero si estamos en alguno de los seis ciclos en los que la ULA está accediendo a memoria, entonces ésta bloquea el reloj del Z80, manteniéndolo a nivel alto hasta alcanzar el punto en el que el acceso está permitido. Entonces liberará el reloj y el Z80 continuará como si no hubiese pasado nada, bajando entonces la señal MREQ (Memory REQest) para indicar que es un acceso a memoria. Con esto ya tenemos resuelto el problema de detectar cuando el procesador va a intentar leer de, o escribir en, la memoria de vídeo.
Sin embargo, queda un segundo problema: la dirección de memoria permanece en el bus durante los tres ciclos completos de acceso a la RAM si estamos leyendo un dato, o durante los dos ciclos completos de acceso para leer una instrucción. ¿Por qué entonces no se activa el bloqueo durante el tercer ciclo, cuando ya han pasado los dos huecos libres y la ULA va a acceder para leer los datos de vídeo? Pues porque el mecanismo de contienda se desactiva cuando la línea MREQ está baja. De esta manera, cualquier acceso que comience en los dos ciclos libres que deja la ULA tendrán la línea MREQ baja durante el resto del tiempo, garantizando que la ULA no bloqueará al procesador hasta que termine el acceso y la línea MREQ vuelva a estado alto (obviamente esto significa también que los dos ciclos «libres» están situados dos ciclos de reloj ANTES de que la ULA termine de leer datos, para que cuando el procesador vaya a leer o escribir realmente el dato, lo haga en el momento en el que la memoria está realmente libre).
Y ya con todo esto podemos entender qué ocurre con LDI: cuando va a realizar la escritura del dato que leyó antes, el Z80 pone la dirección de destino (contenida en el registro DE) en el bus de datos. En ese momento la ULA congelará, si procede, el reloj del Z80 hasta llegar al primer ciclo libre en el que pueda acceder, momento en el cual el Z80 continuará su ejecución y pondrá a cero la línea MREQ, activándola, y durante los dos ciclos siguientes leerá el dato. Ahora estamos dos ciclos y medio más tarde que antes (recordad que ya se consumió medio ciclo al comprobar si la dirección es del bloque de pantalla), por lo que ya volvemos a estar en zona de contienda, pero no importa porque MREQ aún está a nivel bajo, por lo que la ULA no va a bloquear el reloj.
Ah, pero en cuanto termina ese acceso, el Z80 desactiva MREQ poniéndolo a nivel alto, pero el bus de direcciones conserva la última dirección puesta en él, con lo que, de pronto, la ULA se encuentra de nuevo con que en el bus está una dirección pertenece al bloque de pantalla (pues estamos escribiendo en pantalla) y con MREQ desactivado, por lo que asume que la CPU va a realizar un nuevo acceso a memoria de pantalla y bloqueará el reloj hasta el siguiente ciclo libre, cinco ciclos más adelante, cuando en realidad no son más que dos ciclos extra de la instrucción actual y la siguiente lectura o escritura no comenzará realmente hasta dos ciclos más tarde. Cuando llega el primer ciclo libre, el Z80 puede ejecutar dos ciclos, justo los dos ciclos que faltaban por terminar. ¿Resultado? La CPU estuvo bloqueada cinco ciclos de más. Ahora el procesador leerá el siguiente LDI (8 ciclos, con lo que volvemos a estar justo al principio de un grupo de seis ciclos de contienda), pero no se bloqueará el reloj porque la instrucción está en la memoria alta; lee el dato a copiar, también desde la memoria alta (tres ciclos más, quedan tres para terminar el bloque de ciclos de contienda actual) e intentará escribir el dato en la memoria de vídeo… con lo que la ULA bloqueará el Z80 durante esos tres ciclos que faltan. Conclusión: cinco ciclos de retardo de la instrucción anterior, más estos tres, suman justo los ocho ciclos extra. Caso cerrado.
El problema, claro, es que por culpa de esto la copia tarda demasiado, y ya sí que no nos da tiempo a volcar toda la pantalla sin que nos pille el haz. Así que la pregunta es ¿qué podemos hacer?
La solución está en utilizar PUSH y POP, las instrucciones de acceso a la pila. Estas instrucciones son muy rápidas, 11 y 10 ciclos de reloj respectivamente; pero además, transfieren DOS bytes en una sola instrucción, lo que es muy interesante. Y además, si revisamos en la tabla de ciclos, vemos que PUSH tiene:
pc:4,ir:1,sp-1:3,sp-2:3
y POP tiene:
pc:4,sp:3,sp+1:3
En otras palabras: POP no tiene ningún ciclo extra, y PUSH tiene uno, pero al estar situado justo después de la lectura del código de la instrucción, lo que hay en el bus es el contenido de los registros I y R, por lo que tampoco nos afecta (ese es el dato que pone el Z80 en el bus durante el refresco de memoria). Bueno, en realidad sí nos afectará un poco: tras la primera escritura, quedarán cinco ciclos hasta que acabe la contienda y se pueda escribir el segundo dato. Tras grabarlo nos quedarán de nuevo cinco ciclos hasta el siguiente, pero… eso son justo los cinco ciclos que necesitamos para leer el código del siguiente PUSH más el ciclo extra, por lo que no tendremos contienda en el primer byte del siguiente PUSH, pero sí en el segundo. Por tanto, necesitaremos 16 ciclos para grabar dos bytes, y ya contando con la contienda, lo que hace que esta instrucción parezca más del doble de rápida que LDI. ¿Mola o no mola?
Claro, ahora viene el problema: cada PUSH necesita un POP para leer antes la memoria, lo que significa que, en realidad, serán 26 ciclos para grabar dos bytes, o sea, trece ciclos por byte (no olvidemos que leeremos de un buffer que estará fuera de la memoria de pantalla, por lo que POP no sufrirá contienda). Que sigue estando muy bien, eso sí.
O no… porque mientras que POP lee en el sentido que nos gusta («hacia arriba»), PUSH escribe al revés («hacia abajo»), lo que significa que tenemos que poner el puntero de escritura «por delante» y escribir «hacia atrás». Esto ya empieza a complicarse.
Encima, PUSH y POP comparten el puntero de escritura (el registro de 16 bits SP), lo que significa que tras cada POP tenemos que cambiar su valor antes de hacer el PUSH, lo que lleva mucho tiempo (la instrucción más rápida es LD SP, HL, que son 6 ciclos de reloj… pero sólo nos serviría para una de las dos, pues la otra tendría que almacenar el valor actual en IX o IY, con lo que serían ya 10 ciclos de reloj).
Parece que la cosa no tiene buena pinta, pero en realidad aún no estamos acabados: en lugar de hacer un único POP seguido de un único PUSH, podemos hacer varios POPs seguidos, cambiar SP, hacer el mismo número de PUSH, volver a cambiar SP, hacer más POPs seguidos… y así sucesivamente.
Este es el bloque en el que he basado la solución, el cual utiliza HL para contener la dirección de origen de un bloque de 32 bytes (una scanline), y HL’ para la dirección de destino (en realidad HL’ debe contener la dirección de destino + 16, debido a que PUSH escribe en sentido inverso):
; Copia 32 bytes desde HL hasta HL'-16
ld sp, hl ; SP apunta al origen de los datos
ld a, 16 ; lo incrementamos para que ya apunte a los
add a, l ; siguientes 16 bytes
ld l, a
pop af ; leemos todos los datos que podamos en los
pop bc ; pares de registros de que disponemos
pop de
pop ix
exx ; también en el set alternativo, y los
ex af, af' ; registros índice
pop af
pop bc
pop de
pop iy
ld sp, hl ; cargamos la dirección de destino (HL', pues estamos
push iy ; en el juego alternativo)
push de ; escribimos los datos en orden inverso
push bc
push af
ld de, 16
add hl, de ; aprovechamos que DE ya está libre para incrementar
exx ; el puntero de destino hasta los siguientes 16 bytes
ex af, af' ; y copiamos el resto de los registros que quedaban
push ix
push de
push bc
push af ; ya hemos copiado 16 bytes, media scanline
ld sp, hl ; repetimos el proceso para copiar los otros 16 bytes
ld a, 16 ; Será casi igual, sólo hay una única diferencia...
add a, l
ld l, a
pop af
pop bc
pop de
pop ix
exx
ex af, af'
pop af
pop bc
pop de
pop iy
ld sp, hl
push iy
push de
push bc
push af
ld de, 240 ; al incrementar el puntero de destino, lo hacemos
add hl, de ; sumando 240, para que junto con los 16 que ya
exx ; copiamos en el bloque anterior, sume 256, que es
ex af, af' ; justo lo que hay que saltar para pasar al siguiente
push ix ; scanline de un caracter
push de
push bc
push af
Este bloque consume en total 490 Testados en el caso mejor (sin contienda) y 565 Testados en el peor (con contienda), pero copia 32 bytes, lo que nos da un tiempo entre 15,3125 y 17,65625 Testados por byte, lo que no está nada mal. Obviamente, una vez que añadimos código para leer la dirección de destino y el bucle, la cosa empeora un poco, pero no demasiado.
Vemos que el puntero de destino siempre lo incremento con una suma de 16 bits, pero el de origen lo hago con una de 8 bits, incrementando sólo la parte baja de cada vez. Esto lo hago así porque esa operación completa de ocho bits (cargar A, sumarle L y copiar A en L) consume seis ciclos de reloj menos que la operación de suma completa de 16 bits (cargar DE y sumar a HL), pero también significa que cada ocho bloques, tenemos que incrementar manualmente en uno el registro H para que el valor sea correcto, aunque esto lo podemos hacer con un simple INC HL.
También significa que, sin más cambios, sólo nos sirve para copiar las ocho scanlines de una fila de caracteres, pero no puede saltar de un carácter al siguiente, sino que cada ocho repeticiones tendremos que recargar «a mano» (en mi caso, desde una tabla) la dirección de la scanline siguiente.
Al principio, para no consumir demasiada memoria, decidí meter el bloque en un bucle de ocho repeticiones, pero por desgracia tardaba demasiado, así que probé a repetir tres veces el código dentro del bucle, ejecutarlo dos veces, y poner sendas copias extra fuera, de manera que sumasen las ocho copias para un carácter, tras lo cual se leería la siguiente dirección de destino desde una tabla. El resultado era bueno: casi podía pintar 22 caracteres en pantalla sin que hubiese tearing. Lo malo es que, realmente, sí había tiempo de sobra para las 22 filas con sus atributos de color, pero por desgracia, cuando terminaba de copiar los atributos de la última fila, el haz ya había empezado a pintar las primeras scanlines de dicha fila, y obviamente había cogido los atributos incorrectos.
Probé a cambiar el orden, copiando primero los atributos y luego los píxeles, de manera que cuando el haz llegase a la primera scanline de la fila 22 los atributos y los píxeles ya estuviesen allí, aunque los píxeles de la última fila aún no. Y funcionó… en parte, porque entonces ahora el problema era el inverso: las primeras ocho filas veían sus atributos de color cambiados antes de que el haz ya hubiese pasado, con lo que aparecían con el color futuro.
Ante esto se me ocurrió la solución: copiar primero la mitad de los scanlines de píxeles, de manera que nunca me pueda adelantar al rato catódico, copiar entonces los atributos de color, aprovechando que el haz estará pintando en borde inferior, y finalmente seguir copiando las scanlines restantes desde el buffer. Es más: haciendo pruebas, la solución óptima es copiar siete filas, luego los atributos, y terminar de nuevo con el resto de las filas. Sin embargo, como la pila no está disponible, no puedo hacer una llamada con call y luego volver con ret, así que tuve que hacer un truco con código automodificable, y almacenar las direcciones de retorno en mitad de la lista de direcciones de cada fila.
El resultado era casi perfecto, porque por desgracia las 22 líneas me sabían a poco: sobraba espacio en blanco y no me gustaba nada, así que decidí intentar llegar hasta las 23 líneas de caracteres. Para ello desenrrollé completamente el bucle anterior, poniendo ocho copias de él seguidas, una detrás de la otra, con lo que me ahorraba el tiempo de ejecutar el bucle. Con eso conseguí algo más de 22 filas y media. Eso significa que habrá un poco de tearing en las dos/tres últimas líneas del último carácter, algo que puedo decir que no se nota nada.
El bus flotante en el +2A y +3
Para finalizar, añado un detalle importante: en la entrada 7 comenté cómo sincronizarnos con el haz fácilmente aprovechando el bus flotante del Spectrum y saber cuando está la ULA leyendo la zona del PAPER. Comenté también que en los modelos +2A y +3 esto no funcionaba si no se hacía una pequeña modificación a nivel hardware. Sin embargo resulta que sí hay una manera de conseguir que funcione sin cambio alguno, lo que pasa es que está ligeramente escondida. Resulta que el bus flotante del +2A/+3 sí funciona si el puerto es de la forma 0000 xxxx xxxx xx01, tal y como descubrió Chernandezba (aunque sólo si estamos en modo 128K; en modo 48K no funciona). He incluido este cambio en mi código, usando el puerto 0x0FFD, y ahora ya funciona en cualquier Spectrum (con la excepción del Inves, claro).
Para un juego, es necesario leer el teclado. Normalmente el Spectrum utiliza la interrupción de la ULA para llamar a la rutina de lectura del teclado situada en la dirección 0x38. Sin embargo, en la última entrada vimos cómo utilizar el modo 2 de interrupciones para llamar a nuestra propia función de respuesta. Eso significa que ya no se llama a la vieja función.
La primera solución consiste en llamar nosotros al final de nuestra ISR a la rutina de lectura de teclado en la dirección 0x38 (página 6), pero el código de la ROM es bastante complejo pues realiza muchas funciones extra, tales como decodificar la tecla concreta y gestionar la autorrepetición. Además, asume que puede escribir en las variables del sistema del Spectrum, las cuales no tienen por qué existir si hemos arrancado un emulador desde un fichero .Z80.
Otra solución consiste en llamar a la rutina KEY-SCAN de la ROM, en la dirección 0x028E, que se llama desde la anterior y es la misma que se utiliza para la funcion INKEY$. Sin embargo, sigue siendo demasiado complicada para lo que necesitamos, pues realmente para un juego no necesitas detectar SHIFT + tecla, por ejemplo. Por eso decidí hacer mi propia rutina de escaneo de teclado. Esto me ha permitido reducir al mínimo su complejidad y, sobre todo, el tiempo que necesita para ejecutarse. Para entenderla, empecemos por ver cómo es el teclado en el Spectrum:
Vemos que las cuarenta teclas forman una matriz de 5×8 teclas. Las columnas están conectadas por un lado a 5 voltios a través de unas resistencias de 10Kohms, las cuales mantienen a las líneas a uno lógico por defecto. Por el otro lado, las cinco columnas están conectadas a la ULA, que es quien se encarga de enviar al procesador el dato cuando se lee del puerto 254. En cuanto a las filas, vemos que están conectadas a las ocho líneas superiores del bus de direcciones (y para evitar cortocircuitos, mediante un diodo 1N4148).
Si todas las líneas A8-A15 están a 1, da igual que pulsemos una tecla o no, pues la línea correspondiente del bus de datos (D0-D4) recibiría cinco voltios. Sin embargo, si colocamos una de estas líneas del bus de direcciones a 0 y pulsamos una tecla cualquiera de dicha fila, el pulsador de la tecla conectará dicha fila a la columna correspondiente, con lo que el procesador leerá un 0 en esa línea.
Así, si queremos saber si la tecla B, por ejemplo, está pulsada o no, tenemos que poner A15 a cero y el resto (A14-A8) a uno, leer el puerto 254, y comprobar si D4 está a cero (en cuyo caso la tecla estará pulsada) o a uno (en cuyo caso la tecla no estará pulsada).
Veamos ahora mi rutina de lectura de teclado:
ld BC, 0xFEFE
ld DE, 0x001F
IM2_LOOP:
in A, (C)
cpl
and E
jr NZ, IM2_LOOP2
rlc B
ld A, 0x20
add A, D
ld D, A
jr NC,IM2_LOOP
IM2_LOOP2:
or D
ld (CURRENT_KEY), A
Dado que vamos a usar IN A, (C), empezamos cargando 0xFE en el registro C para direccionar el puerto 254 (el de la ULA) y leer el teclado. Además, cargamos también 0xFE en B pues su valor será el que aparezca en la parte superior del bus de direcciones. Por otro lado, ponemos D a cero, pues lo usaremos para contar las semifilas en sus tres bits superiores.
Ahora leemos el puerto 254 y así tendremos el valor en el registro A. Invertimos los bits de manera que la tecla pulsada esté a uno en lugar de a cero, y eliminamos los tres bits superiores, que no se necesitan para nada (recordemos que el bit D6 es el del puerto del casete, y su valor, en ausencia de señal, suele ser aleatorio). Si el valor es cero significa que no hay ninguna tecla pulsada en esta semifila, así que rotamos B a la izquierda de manera que el bit que está a cero pase a la siguiente posición, y así escanear la siguiente semifila. Le sumamos también 32 al valor actual de D para contar la siguiente semifila. Hecho esto, si detectamos acarreo tras la suma significa que ya hemos hecho las ocho semifilas y podemos salir del bucle.
Sin embargo ¿qué pasa si el valor leído no es cero? Eso significa que alguna tecla está pulsada. En ese caso lo que hacemos es mezclar con una operación OR el valor leído y el del registro D, de manera que los cinco bits inferiores tendrán un bit a 1 por cada tecla pulsada en la semifila, y los tres bits superiores tendrán el número de semifila en la que se ha detectado la pulsación.
Obviamente esta función es muy sencilla, pero es suficiente para asignar un valor de ocho bits único a cada tecla pulsada, aunque no es capaz de identificar bien si hay varias pulsaciones simultáneas (sólo si son de la misma semifila), pero para lo que necesitaremos es más que suficiente.
Sin embargo, lo interesante de esta rutina es que es MUY rápida. En concreto, en el peor de los casos tardará 528 Testados en ejecutarse. Eso es menos de lo que duran tres scanlines, lo que significa que podemos ejecutarlo antes del bucle que detecta cuando empieza la ULA a pintar en la zona del PAPER de la pantalla, pues la zona del BORDER que está antes son 64 scanlines, por lo que tenemos tiempo más que de sobra. El resultado es que podemos aprovechar parte de ese tiempo que nos quedábamos esperando.
La tecla pulsada se almacena al final en la posición de memoria CURRENT_KEY, y será cero si no hay ninguna pulsada, o un valor único para cada tecla si sí está pulsada. Para asociar cada valor a una tecla basta con saber que los tres bits superiores contienen la semifila (000 -> A8, 001 -> A9, … , 110 -> A14, 111 -> A15), y los cinco bits inferiores qué teclas están pulsadas en esa semifila.
Y con esto ya tenemos todo listo para empezar a pintar el MAPA.
Utilizamos cookies para garantizar que tenga la mejor experiencia en nuestro sitio web.