Llevo varios días implementando el moverme por el mapa del juego con libertad, y cada vez me daba más rabia ver las cuatro filas inferiores desaprovechadas. No podía evitar preguntarme si realmente no era posible conseguir hacer scroll a todo color a pantalla completa. El problema es que para ello, es imprescindible poder copiar todo el buffer intermedio (donde vamos pintando «con calma» las cosas) en la pantalla antes de que nos alcance el haz. Si recordamos los cálculos de los primeros capítulos, la cosa estaba bastante justa, así que al final decidí utilizar la rutina con la tabla de 192 entradas, la que me permite usar hasta 23 filas sin tearing, pero pintando las 24. Por que se viese un poco abajo de todo, tampoco sería un desastre.
Sin embargo el efecto era bastante exagerado, lo que no me gustaba. Pero a la vez yo se que mi emulador FBZX, el que uso para las pruebas, no es completamente preciso, a pesar de todos mis intentos, así que decidí pedir a algunos compañeros de Zona de pruebas que me hiciesen el favor de probar el código en un Spectrum real. Y lo sorprendente es que la última línea se veía perfecta.
Demasiado perfecta.
Era muy raro… TENÍA que notarse algo en la última fila, pero no… era perfecta. ¿Qué estaba pasando?
Me recomendaron entonces que probase con Es.pectrum, un emulador muy preciso que, además, tiene un depurador y es capaz de mostrar por donde va el barrido, paso a paso. Aunque es para Windows, funciona en wine, así que le di un tiento… y me quedé alucinado de la maravilla de depurador.
Rápidamente cargué mi código y lo probé, y efectivamente, se veía maravillosamente bien, así que fui al depurador, puse un punto de ruptura al comienzo de los LDIs de copia del buffer, lo lancé, fui viendo cómo se pintaba la pantalla y… ¡¡¡El volcado necesitó dos barridos y medio de pantalla, cuando debería haber sido bastante menos de dos!!!
Aquello no tenía ningún sentido: ni aún suponiendo que todas las filas sufriesen contienda podía ocurrir aquello, era demasiado tiempo de más.
Decidí poner un punto de ruptura en cada uno de los LDIs de una fila, a ver qué sacaba en claro, y comencé a ejecutar. Y entonces me encontré con algo rarísimo: cada LDI tardaba 24 Testados en ejecutarse. ¿Por qué, si se supone que dura 16? Podría tener sentido que el primer LDI de los 32 tardase más porque sufriese contienda, pero el resto tenían que encajar exactamente en cada hueco que dejaba la ULA, pues 16 es múltiplo de 8.
Decidí buscar en la documentación online sobre la contienda si había algo que afectase a LDI, y me encontré con esto:
pc:4,pc+1:4,hl:3,de:3,de:1 ×2
No entendía qué significaba, así que le di vueltas y vueltas hasta que, de pronto, caí: LDI es una instrucción de dos bytes (prefijo + código de instrucción). Los prefijos, al igual que los códigos de instrucción, necesitan 4 ciclos de reloj para leerse desde la memoria, de ahí pc:4, pc+1:4: el bus de direcciones contiene la dirección del contador de programa, PC, durante cuatro ciclos de reloj (para leer el prefijo), y luego, durante otros cuatro ciclos, el valor PC+1, cuando lee la instrucción en sí. Luego se lee el byte a copiar, y como es una lectura de un dato, sólo necesita tres ciclos, de ahí hl:3: el valor de HL aparece en el bus de direcciones durante tres ciclos de reloj. A continuación se escribe el byte en el destino en la dirección contenida en el par de registros DE, lo que también consume tres ciclos de reloj, de:3. Y ahora viene la clave: 4+4+3+3=14 ciclos de reloj. Pero la instrucción consume 16. ¿Qué pasa con esos dos ciclos extra? Pues son los necesarios para incrementar HL y DE y decrementar BC. La cuestión, y esta es la clave, es que durante ese tiempo el bus de direcciones conserva el valor de DE, y si recordamos, DE apunta a una dirección de memoria de pantalla, por lo que se verá afectado por la contienda.
El motivo de que DE continúe en el bus de direcciones es que, dado que este bus es sólo de salida, no es necesario ponerlo en tercer estado, por lo que cada vez que se pone un valor, éste permanece, y solo cambia cuando es sobreescrito por un nuevo valor.
¿Y por qué el mero hecho de que haya una dirección de pantalla en el bus es suficiente para disparar el mecanismo de contienda? Para saberlo, vamos a explicar cómo funciona dicho mecanismo.
Recordemos que el objetivo original del Spectrum es que fuese barato. Ese era EL factor clave que condicionaba absolutamente todo el diseño, por lo que la ULA no podía contener circuitos muy complejos sino que tenía que ser lo más simple posible (y así poder utilizar el modelo más barato posible de los que ofertaba Ferranti).
Fijémonos primero en cómo es un acceso a memoria del Z80 si queremos leer una instrucción:
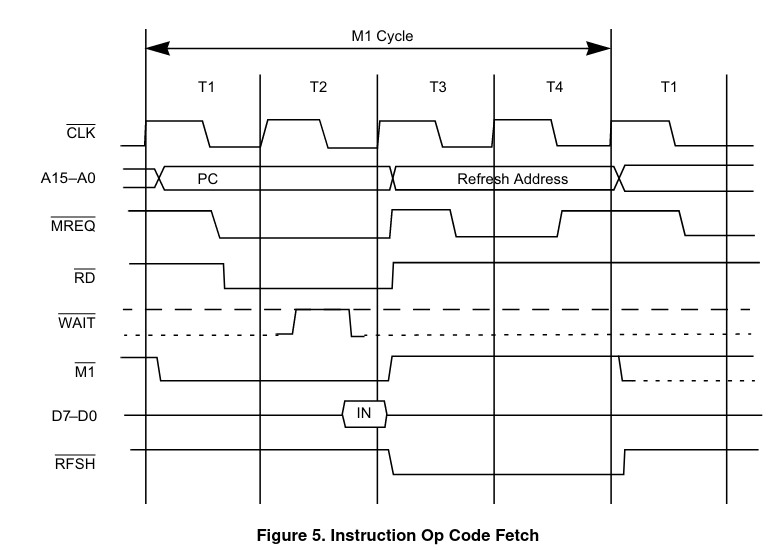
Comparémoslo ahora con el acceso a RAM para leer o escribir un byte «en general» (por ejemplo cuando leemos un dato inmediato, o un dato de la RAM… cualquier cosa que no sea el bytecode de una instrucción):
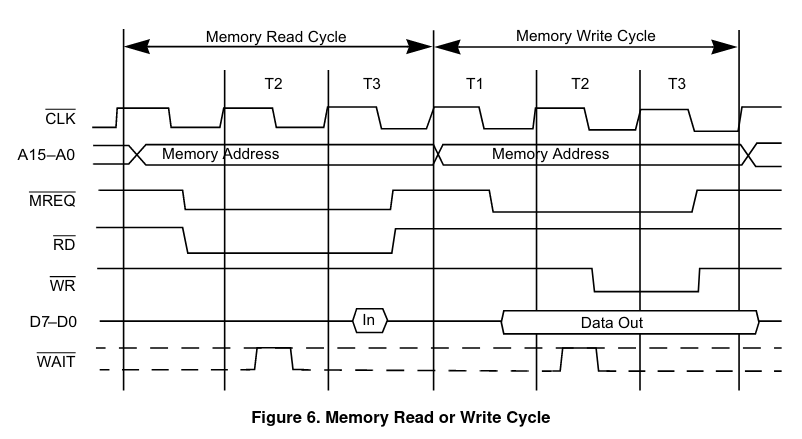
Vemos que en ambos casos, el Z80 comienza poniendo en el bus de direcciones la dirección de memoria a la que quiere acceder, muy poquito después del flanco de subida del primer ciclo de reloj, y no es hasta inmediatamente después del flanco de bajada de ese mismo ciclo que el procesador pone a cero la línea MREQ para indicar que va a realizar un acceso a memoria, para así dar tiempo a que las tensiones en el bus de direcciones se estabilicen y evitar transitorios. Además, vemos que la única diferencia práctica entre un acceso a memoria «normal» o uno para «instrucción» es que en el primer caso el dato se lee durante el flanco de bajada situado a la mitad del tercer ciclo, mientras que el segundo se lee durante el flanco de subida situado entre el segundo y tercer ciclo.
¿Y cómo aprovecha esto la ULA para realizar la contención? Pues básicamente lo que hace es vigilar constantemente el bus de direcciones, de manera que si durante la parte alta de un ciclo de reloj el bit A15 es cero y el bit A14 es uno, considera que se va a realizar un acceso a memoria de vídeo y activa el mecanismo de contención. Si estamos en alguno de los dos ciclos de reloj en los que el acceso está permitido, entonces no pasa nada y el procesador accede normalmente, accediendo al dato entre un ciclo y medio y dos ciclos más tarde; pero si estamos en alguno de los seis ciclos en los que la ULA está accediendo a memoria, entonces ésta bloquea el reloj del Z80, manteniéndolo a nivel alto hasta alcanzar el punto en el que el acceso está permitido. Entonces liberará el reloj y el Z80 continuará como si no hubiese pasado nada, bajando entonces la señal MREQ (Memory REQest) para indicar que es un acceso a memoria. Con esto ya tenemos resuelto el problema de detectar cuando el procesador va a intentar leer de, o escribir en, la memoria de vídeo.
Sin embargo, queda un segundo problema: la dirección de memoria permanece en el bus durante los tres ciclos completos de acceso a la RAM si estamos leyendo un dato, o durante los dos ciclos completos de acceso para leer una instrucción. ¿Por qué entonces no se activa el bloqueo durante el tercer ciclo, cuando ya han pasado los dos huecos libres y la ULA va a acceder para leer los datos de vídeo? Pues porque el mecanismo de contienda se desactiva cuando la línea MREQ está baja. De esta manera, cualquier acceso que comience en los dos ciclos libres que deja la ULA tendrán la línea MREQ baja durante el resto del tiempo, garantizando que la ULA no bloqueará al procesador hasta que termine el acceso y la línea MREQ vuelva a estado alto (obviamente esto significa también que los dos ciclos «libres» están situados dos ciclos de reloj ANTES de que la ULA termine de leer datos, para que cuando el procesador vaya a leer o escribir realmente el dato, lo haga en el momento en el que la memoria está realmente libre).
Y ya con todo esto podemos entender qué ocurre con LDI: cuando va a realizar la escritura del dato que leyó antes, el Z80 pone la dirección de destino (contenida en el registro DE) en el bus de datos. En ese momento la ULA congelará, si procede, el reloj del Z80 hasta llegar al primer ciclo libre en el que pueda acceder, momento en el cual el Z80 continuará su ejecución y pondrá a cero la línea MREQ, activándola, y durante los dos ciclos siguientes leerá el dato. Ahora estamos dos ciclos y medio más tarde que antes (recordad que ya se consumió medio ciclo al comprobar si la dirección es del bloque de pantalla), por lo que ya volvemos a estar en zona de contienda, pero no importa porque MREQ aún está a nivel bajo, por lo que la ULA no va a bloquear el reloj.
Ah, pero en cuanto termina ese acceso, el Z80 desactiva MREQ poniéndolo a nivel alto, pero el bus de direcciones conserva la última dirección puesta en él, con lo que, de pronto, la ULA se encuentra de nuevo con que en el bus está una dirección pertenece al bloque de pantalla (pues estamos escribiendo en pantalla) y con MREQ desactivado, por lo que asume que la CPU va a realizar un nuevo acceso a memoria de pantalla y bloqueará el reloj hasta el siguiente ciclo libre, cinco ciclos más adelante, cuando en realidad no son más que dos ciclos extra de la instrucción actual y la siguiente lectura o escritura no comenzará realmente hasta dos ciclos más tarde. Cuando llega el primer ciclo libre, el Z80 puede ejecutar dos ciclos, justo los dos ciclos que faltaban por terminar. ¿Resultado? La CPU estuvo bloqueada cinco ciclos de más. Ahora el procesador leerá el siguiente LDI (8 ciclos, con lo que volvemos a estar justo al principio de un grupo de seis ciclos de contienda), pero no se bloqueará el reloj porque la instrucción está en la memoria alta; lee el dato a copiar, también desde la memoria alta (tres ciclos más, quedan tres para terminar el bloque de ciclos de contienda actual) e intentará escribir el dato en la memoria de vídeo… con lo que la ULA bloqueará el Z80 durante esos tres ciclos que faltan. Conclusión: cinco ciclos de retardo de la instrucción anterior, más estos tres, suman justo los ocho ciclos extra. Caso cerrado.
El problema, claro, es que por culpa de esto la copia tarda demasiado, y ya sí que no nos da tiempo a volcar toda la pantalla sin que nos pille el haz. Así que la pregunta es ¿qué podemos hacer?
La solución está en utilizar PUSH y POP, las instrucciones de acceso a la pila. Estas instrucciones son muy rápidas, 11 y 10 ciclos de reloj respectivamente; pero además, transfieren DOS bytes en una sola instrucción, lo que es muy interesante. Y además, si revisamos en la tabla de ciclos, vemos que PUSH tiene:
pc:4,ir:1,sp-1:3,sp-2:3
y POP tiene:
pc:4,sp:3,sp+1:3
En otras palabras: POP no tiene ningún ciclo extra, y PUSH tiene uno, pero al estar situado justo después de la lectura del código de la instrucción, lo que hay en el bus es el contenido de los registros I y R, por lo que tampoco nos afecta (ese es el dato que pone el Z80 en el bus durante el refresco de memoria). Bueno, en realidad sí nos afectará un poco: tras la primera escritura, quedarán cinco ciclos hasta que acabe la contienda y se pueda escribir el segundo dato. Tras grabarlo nos quedarán de nuevo cinco ciclos hasta el siguiente, pero… eso son justo los cinco ciclos que necesitamos para leer el código del siguiente PUSH más el ciclo extra, por lo que no tendremos contienda en el primer byte del siguiente PUSH, pero sí en el segundo. Por tanto, necesitaremos 16 ciclos para grabar dos bytes, y ya contando con la contienda, lo que hace que esta instrucción parezca más del doble de rápida que LDI. ¿Mola o no mola?
Claro, ahora viene el problema: cada PUSH necesita un POP para leer antes la memoria, lo que significa que, en realidad, serán 26 ciclos para grabar dos bytes, o sea, trece ciclos por byte (no olvidemos que leeremos de un buffer que estará fuera de la memoria de pantalla, por lo que POP no sufrirá contienda). Que sigue estando muy bien, eso sí.
O no… porque mientras que POP lee en el sentido que nos gusta («hacia arriba»), PUSH escribe al revés («hacia abajo»), lo que significa que tenemos que poner el puntero de escritura «por delante» y escribir «hacia atrás». Esto ya empieza a complicarse.
Encima, PUSH y POP comparten el puntero de escritura (el registro de 16 bits SP), lo que significa que tras cada POP tenemos que cambiar su valor antes de hacer el PUSH, lo que lleva mucho tiempo (la instrucción más rápida es LD SP, HL, que son 6 ciclos de reloj… pero sólo nos serviría para una de las dos, pues la otra tendría que almacenar el valor actual en IX o IY, con lo que serían ya 10 ciclos de reloj).
Parece que la cosa no tiene buena pinta, pero en realidad aún no estamos acabados: en lugar de hacer un único POP seguido de un único PUSH, podemos hacer varios POPs seguidos, cambiar SP, hacer el mismo número de PUSH, volver a cambiar SP, hacer más POPs seguidos… y así sucesivamente.
Este es el bloque en el que he basado la solución, el cual utiliza HL para contener la dirección de origen de un bloque de 32 bytes (una scanline), y HL’ para la dirección de destino (en realidad HL’ debe contener la dirección de destino + 16, debido a que PUSH escribe en sentido inverso):
; Copia 32 bytes desde HL hasta HL'-16
ld sp, hl ; SP apunta al origen de los datos
ld a, 16 ; lo incrementamos para que ya apunte a los
add a, l ; siguientes 16 bytes
ld l, a
pop af ; leemos todos los datos que podamos en los
pop bc ; pares de registros de que disponemos
pop de
pop ix
exx ; también en el set alternativo, y los
ex af, af' ; registros índice
pop af
pop bc
pop de
pop iy
ld sp, hl ; cargamos la dirección de destino (HL', pues estamos
push iy ; en el juego alternativo)
push de ; escribimos los datos en orden inverso
push bc
push af
ld de, 16
add hl, de ; aprovechamos que DE ya está libre para incrementar
exx ; el puntero de destino hasta los siguientes 16 bytes
ex af, af' ; y copiamos el resto de los registros que quedaban
push ix
push de
push bc
push af ; ya hemos copiado 16 bytes, media scanline
ld sp, hl ; repetimos el proceso para copiar los otros 16 bytes
ld a, 16 ; Será casi igual, sólo hay una única diferencia...
add a, l
ld l, a
pop af
pop bc
pop de
pop ix
exx
ex af, af'
pop af
pop bc
pop de
pop iy
ld sp, hl
push iy
push de
push bc
push af
ld de, 240 ; al incrementar el puntero de destino, lo hacemos
add hl, de ; sumando 240, para que junto con los 16 que ya
exx ; copiamos en el bloque anterior, sume 256, que es
ex af, af' ; justo lo que hay que saltar para pasar al siguiente
push ix ; scanline de un caracter
push de
push bc
push af
Este bloque consume en total 490 Testados en el caso mejor (sin contienda) y 565 Testados en el peor (con contienda), pero copia 32 bytes, lo que nos da un tiempo entre 15,3125 y 17,65625 Testados por byte, lo que no está nada mal. Obviamente, una vez que añadimos código para leer la dirección de destino y el bucle, la cosa empeora un poco, pero no demasiado.
Vemos que el puntero de destino siempre lo incremento con una suma de 16 bits, pero el de origen lo hago con una de 8 bits, incrementando sólo la parte baja de cada vez. Esto lo hago así porque esa operación completa de ocho bits (cargar A, sumarle L y copiar A en L) consume seis ciclos de reloj menos que la operación de suma completa de 16 bits (cargar DE y sumar a HL), pero también significa que cada ocho bloques, tenemos que incrementar manualmente en uno el registro H para que el valor sea correcto, aunque esto lo podemos hacer con un simple INC HL.
También significa que, sin más cambios, sólo nos sirve para copiar las ocho scanlines de una fila de caracteres, pero no puede saltar de un carácter al siguiente, sino que cada ocho repeticiones tendremos que recargar «a mano» (en mi caso, desde una tabla) la dirección de la scanline siguiente.
Al principio, para no consumir demasiada memoria, decidí meter el bloque en un bucle de ocho repeticiones, pero por desgracia tardaba demasiado, así que probé a repetir tres veces el código dentro del bucle, ejecutarlo dos veces, y poner sendas copias extra fuera, de manera que sumasen las ocho copias para un carácter, tras lo cual se leería la siguiente dirección de destino desde una tabla. El resultado era bueno: casi podía pintar 22 caracteres en pantalla sin que hubiese tearing. Lo malo es que, realmente, sí había tiempo de sobra para las 22 filas con sus atributos de color, pero por desgracia, cuando terminaba de copiar los atributos de la última fila, el haz ya había empezado a pintar las primeras scanlines de dicha fila, y obviamente había cogido los atributos incorrectos.
Probé a cambiar el orden, copiando primero los atributos y luego los píxeles, de manera que cuando el haz llegase a la primera scanline de la fila 22 los atributos y los píxeles ya estuviesen allí, aunque los píxeles de la última fila aún no. Y funcionó… en parte, porque entonces ahora el problema era el inverso: las primeras ocho filas veían sus atributos de color cambiados antes de que el haz ya hubiese pasado, con lo que aparecían con el color futuro.
Ante esto se me ocurrió la solución: copiar primero la mitad de los scanlines de píxeles, de manera que nunca me pueda adelantar al rato catódico, copiar entonces los atributos de color, aprovechando que el haz estará pintando en borde inferior, y finalmente seguir copiando las scanlines restantes desde el buffer. Es más: haciendo pruebas, la solución óptima es copiar siete filas, luego los atributos, y terminar de nuevo con el resto de las filas. Sin embargo, como la pila no está disponible, no puedo hacer una llamada con call y luego volver con ret, así que tuve que hacer un truco con código automodificable, y almacenar las direcciones de retorno en mitad de la lista de direcciones de cada fila.
El resultado era casi perfecto, porque por desgracia las 22 líneas me sabían a poco: sobraba espacio en blanco y no me gustaba nada, así que decidí intentar llegar hasta las 23 líneas de caracteres. Para ello desenrrollé completamente el bucle anterior, poniendo ocho copias de él seguidas, una detrás de la otra, con lo que me ahorraba el tiempo de ejecutar el bucle. Con eso conseguí algo más de 22 filas y media. Eso significa que habrá un poco de tearing en las dos/tres últimas líneas del último carácter, algo que puedo decir que no se nota nada.
El bus flotante en el +2A y +3
Para finalizar, añado un detalle importante: en la entrada 7 comenté cómo sincronizarnos con el haz fácilmente aprovechando el bus flotante del Spectrum y saber cuando está la ULA leyendo la zona del PAPER. Comenté también que en los modelos +2A y +3 esto no funcionaba si no se hacía una pequeña modificación a nivel hardware. Sin embargo resulta que sí hay una manera de conseguir que funcione sin cambio alguno, lo que pasa es que está ligeramente escondida. Resulta que el bus flotante del +2A/+3 sí funciona si el puerto es de la forma 0000 xxxx xxxx xx01, tal y como descubrió Chernandezba (aunque sólo si estamos en modo 128K; en modo 48K no funciona). He incluido este cambio en mi código, usando el puerto 0x0FFD, y ahora ya funciona en cualquier Spectrum (con la excepción del Inves, claro).
![]() Pintando en el Spectrum (10) por A cuadros está licenciado bajo una Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.
Pintando en el Spectrum (10) por A cuadros está licenciado bajo una Licencia Creative Commons Atribución-CompartirIgual 4.0 Internacional.