En esta entrada vamos a hacer un cambio pequeño en el código para que pinte mediante interrupciones. Aunque ya antes utilizábamos la instrucción HALT para sincronizarnos con las interrupciones y saber cuando empezar a pintar en pantalla, tiene el inconveniente de que desperdiciamos tiempo, tiempo que podríamos aprovechar para ir adelantando trabajo. Aunque ahora mismo no hay nada que hacer entre que hemos pintado un frame y esperamos a que el barrido de pantalla vuelva al principio, en el futuro, cuando implemente la lógica del juego, tiene sentido que una vez que hemos terminado de pintar los sprites en el buffer intermedio, y esperamos a que termine de trazarse en pantalla en frame actual, podamos ir adelantando trabajo ejecutando la lógica del juego en sí, en lugar de desperdiciar un tiempo precioso simplemente no haciendo nada.
El Z80 tiene dos tipos de interrupciones: enmascarables (INT) y no-enmascarables (NMI). La interrupción no enmascarable siempre se atiende: cada vez que un periférico ponga a cero el pin 17, en cuanto el procesador termine de ejecutar la instrucción actual, guardará la dirección actual del contador de programa y saltará a la dirección 0x66. Para retornar de una NMI se utiliza la instrucción RETN. En el Spectrum, sin embargo, esta interrupción está bloqueada por software, pues en la dirección 0x66 está la ROM con una rutina que comprueba dos bytes de la RAM: si valen 0, saltará a la dirección que contengan dichos bytes (o sea, a la dirección 0x0000, con lo que el ordenador se reiniciará), mientras que si tienen un valor diferente, simplemente retornará sin hacer nada, con lo que el resultado es que, sencillamente, no se puede utilizar para nada. Lo «divertido» es que sólo cambiando un bit en esa rutina el comportamiento sería exactamente el opuesto: si la dirección almacenada es cero, retornaría; y si es diferente, saltaría a dicha dirección, lo que sería un comportamiento muchísimo más útil. Lo más probable es que fuese un cambio de última hora para evitar que se pueda utilizar de manera sencilla para copiar programas.
La interrupción enmascarable, por su parte, se llama así porque es posible desactivarla (en el Z80 mediante la instrucción DI; tras ejecutarla, no se responderá a ninguna INT; para activarlas de nuevo se utiliza la instrucción EI). Como ya dijimos, en el Spectrum se genera una cada vez que la ULA comienza a pintar un nuevo frame en la pantalla, en el primer scanline del BORDER (salvo que estemos en un Inves Specrum+, en cuyo caso la interrupción se genera justo al comenzar a pintar la zona de PAPER). El Z80 tiene tres modos de trabajo para estas interrupciones, seleccionables mediante las instrucciones IM0, IM1 e IM2.
En el modo IM0 (que es el modo por defecto cuando se resetea el procesador, y compatible con el 8080 de Intel), cuando un periférico pone a cero el pin 16 para solicitar una interrupción, tiene que poner, además, en el bus de datos el código de una instrucción para que el procesador la ejecute. Normalmente esa instrucción será una de las ocho instrucciones RST (RST #00, RST #08, RST #10, RST #18, RST #20, RST #28, RST #30 o RST #38) para saltar a una dirección de memoria concreta y ejecutar ahí una rutina de interrupción, aunque en teoría podría ser cualquier instrucción, incluso instrucciones de varios bytes.
En el modo IM1, que es el modo que utiliza la ROM del Spectrum por su simplicidad, cada vez que se produce una INT se saltará a la dirección 0x38, por lo que tiene un comportamiento similar a la NMI, aunque a una dirección diferente. Cabe señalar que el opcode de la instrucción RST #38, que hace una llamada a subrutina a la dirección 0x38, es 255, lo que significa que el Spectrum se comportará igual tanto en modo 0 como en modo 1. En efecto, si recordamos, cuando leemos el bus y nadie está poniendo un dato, leeremos 255, por lo que si el procesador está en modo 0, será eso lo que lea y ejecutará una instrucción RST #38, que saltará a la misma dirección que si estuviésemos en modo 1.
Finalmente, el modo IM2 es el más versátil, aunque también el más complejo de utilizar. Cuando estamos en este modo y se produce una INT, el procesador lee el bus de datos y lo utiliza como la parte baja de una dirección de memoria. La parte alta la tomará del contenido del registro I. Una vez hecho esto, leerá el contenido de esa posición de memoria y de la siguiente y saltará a la dirección de memoria indicada por esos dos bytes leídos. La idea es que si cargamos el registro I con el valor 0xYY, debemos almacenar una tabla de 256 bytes a partir de la dirección 0xYY00 conteniendo direcciones de memoria de las rutinas de interrupción de cada periférico que pueda generar una interrupción. La idea original es que cuando un periférico genere la interrupción, pondrá en el bus de datos el offset o desplazamiento en la tabla en que se encuentra la dirección de memoria de su rutina de gestión. Así, supongamos que I vale 0xF0, y que tenemos esta tabla a partir de 0xF000:
DEFW 0x4012 DEFW 0x5200 DEFW 0x2103
Si tuviésemos un periférico que genera una interrupción y pone el valor 0 en el bus, el Z80 compondrá la dirección 0xF000 (usando el registro I y el valor presente en el bus), y leerá los dos bytes que haya en dicha dirección. En este caso leerá 0x4012, así que comenzará a ejecutar código a partir de esa dirección, que se supone que será el código para gestionar ese periférico concreto. En cambio, si otro periférico genera una interrupción y pone el valor 4 en el bus, el Z80 compondrá la dirección 0xF004 y leerá en dicha zona de la tabla el valor 0x2103, y será esa la dirección de memoria en la que comenzará a ejecutar código. Este sistema permite que cada periférico indique quien es a la vez que genera una interrupción, de manera que el Z80 puede saltar directamente a la rutina que lo gestiona. Por supuesto, la única manera de aprovechar al 100% las tablas es si todos los valores que pueden poner los periféricos son pares, o impares, pues si se mezclan, algunos periféricos podrían llamar a una rutina compuesta por parte de una dirección y parte de la siguiente.
Sin embargo, en el Spectrum no tenemos ningún periférico que trabaje así: el único periférico que genera interrupciones es la ULA, y ésta no pone ningún valor en el bus, por lo que éste siempre valdrá 255. Eso significa que, en teoría, sólo necesitamos una única entrada en nuestra tabla; pero siendo un valor impar, vemos que se «saldría por arriba», en el sentido de que se utilizarían los bytes de las direcciones 0xF0FF y 0xF100.
Veamos un ejemplo de código para inicializar las interrupciones, y cómo lo integramos con nuestro código actual:
ORG 32768
; buffer intermedio de pantalla
BUFFER:
DEFS 6912
; espacio vacío para tener INTM2 alineado en el punto que necesitamos
DEFS 255
INTM2:
DEFW IM2FUNC
[...]
INIT_IM2:
di
ld a, 0x9B
ld i, a
im 2
ei
ret
[...]
IM2FUNC:
; código a ejecutar por la interrupción
[...]
RETI
Vemos que el código que ya teníamos empezaba en la dirección de memoria 0x8000 (o sea, 32768, tal y como especifica el ORG del principio). A continuación tenemos el buffer intermedio, donde pintamos los sprites para que más tarde, cuando hayamos terminado, se vuelque de manera sincronizada en el buffer de pantalla. Este bloque termina en la dirección 0x9AFF, lo que significa que el primer byte libre está en 0x9B00, y como es una dirección redonda (tiene la parte baja a cero) nos sirve para meter la tabla de interrupciones. Sin embargo, recordemos que el bus del Spectrum siempre valdrá 255 (aunque de esto hablaré más un poco más adelante), así que no necesitamos poner la tabla entera, sino sólo la última entrada, y eso es lo que hacemos: dejamos 255 bytes libres, y justo a continuación reservamos dos bytes. Esos 255 bytes los podemos aprovechar para meter otras variables (por ejemplo, la tabla de direcciones de la rutina de volcado del buffer intermedio, u otras), pues no se utilizan para nada.
Vamos ahora a la función INIT_IM2: lo primero que tenemos que hacer es desactivar las interrupciones, pues no queremos que nos llegue una justo en mitad de la configuración y que el procesador salte a vete-tú-a-saber-donde. Una vez hecho esto, cargamos el registro I con el valor 0x9B, de manera que apunte a la tabla que hemos definido antes (que, como recordamos, empieza precisamente en la dirección de memoria 0x9B00). A continuación cambiamos a modo 2, activamos las interrupciones, y salimos.
Ahora, cada vez que la ULA genere una interrupción, al estar el procesador en modo 2 procederá a leer el bus de datos, que valdrá 255, y lo combinará con el registro I para componer la dirección de memoria 0x9BFF. Ahora leerá el valor de 16 bits de dicha dirección, que es justo el que está almacenado en INTM2 gracias a los espacios que hemos dejado en el código, y este valor será el de la dirección de la rutina IM2FUNC, por lo que pasará a ejecutar su código. Cuando termine, tenemos que retornar con RETI para que restaure el estado de las interrupciones (en lugar de RETI también podríamos utilizar EI + RET, pues EI tiene la particularidad de que activa las interrupciones después de la siguiente instrucción, por lo que no hay peligro de que llegue justo una interrupción entre el EI y el RET y que la pila se llene sin control).
Integrando las interrupciones
Todo esto está muy bien, pero ¿y qué se supone que hacemos ahora? Pues la idea consiste en reservar una dirección de memoria para indicar a la rutina de interrupciones que ya hemos terminado de pintar en el buffer intermedio, y que ya puede copiarlo en la pantalla cuando pueda. Y en la rutina de interrupciones lo que pondremos será el código de nuestra vieja amiga paint_screen, la rutina que vimos en las tres primeras entradas para volcar el buffer intermedio en la pantalla real. La idea sería algo así:
DO_REPAINT:
; esta variable nos servira para notificar que el buffer
; intermedio está listo para ser volcado a la pantalla (si vale 1)
DEFB 0
IM2_FUNC:
; Esta es la ISR para la interrupción. Se ejecutará cada vez
; que la ULA genere una interrupción
push AF
ld A, (DO_REPAINT)
and A
jp Z, IM2_EXIT ; si DO_REPAINT vale cero significa que el buffer
; intermedio aún no está listo, así que no hacemos
; nada
push BC
push DE
push HL
exx
push BC
push DE
push HL ; Tenemos que preservar todos los registros que
push IX ; utilicemos dentro de paint_screen
; código de paint_screen
pop IX
pop HL
pop DE
pop BC
exx
pop HL
pop DE ; y restaurarlos al terminar, antes de retornar
pop BC
xor A
ld (DO_REPAINT), A ; notificamos que hemos terminado
IM2_EXIT:
pop AF
reti ; y devolvemos la ejecución al código principal
[...]
; código principal. Pintamos la pantalla en el buffer intermedio
[...]
; ya terminamos de pintar la pantalla, así que notificamos
; que hemos terminado poniendo DO_REPAINT a 1
ld a, 1
ld (DO_REPAINT), a
; hacemos otras cosas, como lógica del juego o demás.
; Cuando llegue la siguiente interrupción, se copiará
; el buffer a la pantalla automáticamente
[...]
; si hemos terminado de actualizar la lógica del juego y
; queremos pintar el siguiente frame, tenemos que esperar
; a que la rutina de interrupción nos notifique que ha acabado.
; Si no lo hacemos, podríamos estar sobreescribiendo el frame
; anterior.
WAIT_PAINTED:
ld A, (REPAINT)
and A
jr nz, WAIT_PAINTED
; ahora ya estamos seguros de que el frame ha sido copiado a
; la pantalla, así que podemos empezar a pintar el siguiente
; en el buffer intermedio
[...]
Así, vemos que en la rutina de interrupciones guardamos en la pila el contenido del registro AF, y luego leemos el valor que hay en la posición de memoria DO_REPAINT. Si es cero, significa que el buffer intermedio aún está a medio pintar y aún no debemos hacer nada, por lo que simplemente saltamos al final de la función, donde restauramos el valor de AF y retornamos.
En cambio, si DO_REPAINT es diferente de cero significa que el buffer intermedio está listo para ser transferido a la pantalla, así que guardamos en la pila el resto de registros que vamos a utilizar (sin olvidarnos de los registros alternativos), copiamos los datos del buffer a la pantalla, restauramos los registros, y retornamos.
Esto es muy útil pues nos permite aprovechar un tiempo que, antes, sencillamente perdíamos. Así, cuando ejecutábamos HALT para esperar al retrazado vertical y empezar a volcar el buffer intermedio a la pantalla, el procesador se quedaba literalmente congelado esperando a que se produjese una interrupción. Ahora, en cambio, podemos empezar a procesar otros datos en cuanto hemos terminado de pintar el frame, y el propio procesador saltará a la rutina de volcado automáticamente en el momento preciso, lo que nos permitirá exprimir al máximo el procesador.
Es fundamental guardar el valor de los registros, pues no hay que olvidar que la rutina de interrupciones se puede llamar en cualquier momento de la ejecución del código principal, y que lo único que se guarda es la dirección de retorno; es nuestra responsabilidad guardar absolutamente el resto de cosas.
Una tabla llena de 255
En mucha literatura sobre el uso de interrupciones en el Spectrum se recomienda crear una tabla de 257 elementos, todos ellos con el mismo valor, y utilizarla como tabla de vectores de interrupción. Es más: recomiendan aprovechar para ello un bloque de algo más de 1 Kbyte de la ROM que está todo él a 255, y así no desperdiciar memoria RAM. El motivo, explican, es que el bus no siempre tiene el valor 255, por lo que si cuando se produce una interrupción el valor no es el esperado, podríamos saltar a vete-tu-a-saber-donde y que se nos cuelgue el ordenador. Esto, como veremos luego, no es cierto (o, al menos, no es cierto en condiciones normales), por lo que no es necesario hacerlo. Pero, de todas formas, voy a describir el proceso porque nunca está de más entenderlo, en caso de que queramos, por ejemplo, desensamblar un programa que lo utilice, entender de qué va.
Veamos con detalle la idea: primero creamos una tabla de 257 bytes, todos ellos con el valor 255, y que empiece en una dirección de memoria cuyo byte bajo sea cero (por ejemplo 0xFE00 hasta 0xFF00 ambos incluídos), o bien aprovechamos que en la ROM del Spectrum 48K, a partir de la dirección 0x386D hay 1179 bytes sin usar, todos ellos a 255, tomando como tabla el bloque que va desde 0x3900 hasta 0x3A00. A continuación, cargamos en el registro I el valor necesario para utilizar ese bloque como tabla de interrupciones (0xFE en el primer caso, 0x3A en el segundo). Esto hará que cuando se produzca una interrupción no importe qué valor hay en el bus: siempre resultará en que comenzará a ejecutar a partir de la dirección 0xFFFF (o sea, el último byte de memoria). Aparentemente esto nos deja muy limitados, pues sólo podríamos ejecutar un único byte antes de dar la vuelta al contador de programa. Pero dado que el primer byte de la ROM del Spectrum es 0xF3 (instrucción DI), si ponemos el valor 0x18 en la dirección 0xFFFF lo que tendremos es que se ejecutará la instrucción JR -13. Por tanto, esa instrucción saltará a la dirección 65524 (no hay que olvidar que después de leer los dos bytes del JR -13, el contador de programa estará apuntando a la dirección 1). Es en esa dirección donde podemos poner una instrucción JP que salte a donde quiera que esté nuestra rutina real.
Alambicado, sí, pero nos da una gran seguridad a la hora de trabajar con interrupciones… ¿o no?
Para empezar, está la cuestión de que ese bloque de más de 1 kbyte a 255 sólo está disponible en el Spectrum 48K. En el modelo de 128K y posteriores ese bloque tiene una serie de rutinas extra, por lo que no está disponible. Esto significa que si utilizamos esto, sólo funcionará en equipos de 48K, pero no en modelos de 128K, ni siquiera aunque cambiemos a modo 48K.
Pero la verdadera cuestión es que, en condiciones normales, el bus de datos del Spectrum siempre estará a 255. Obviamente si nos dedicamos a leer el bus directamente, como ya comenté en entradas anteriores, veremos que a veces muestra otros valores porque estamos viendo el dato que la ULA está leyendo en ese momento para generar la pantalla. Pero la cuestión es que el único valor que nos interesa es el que encontraremos cuando se produzca una interrupción, y dado que éstas se generan cuando la ULA va a comenzar a pintar la parte superior del borde, en ese momento no leerá nada de la RAM, por lo que siempre, siempre, se leerá un 255.
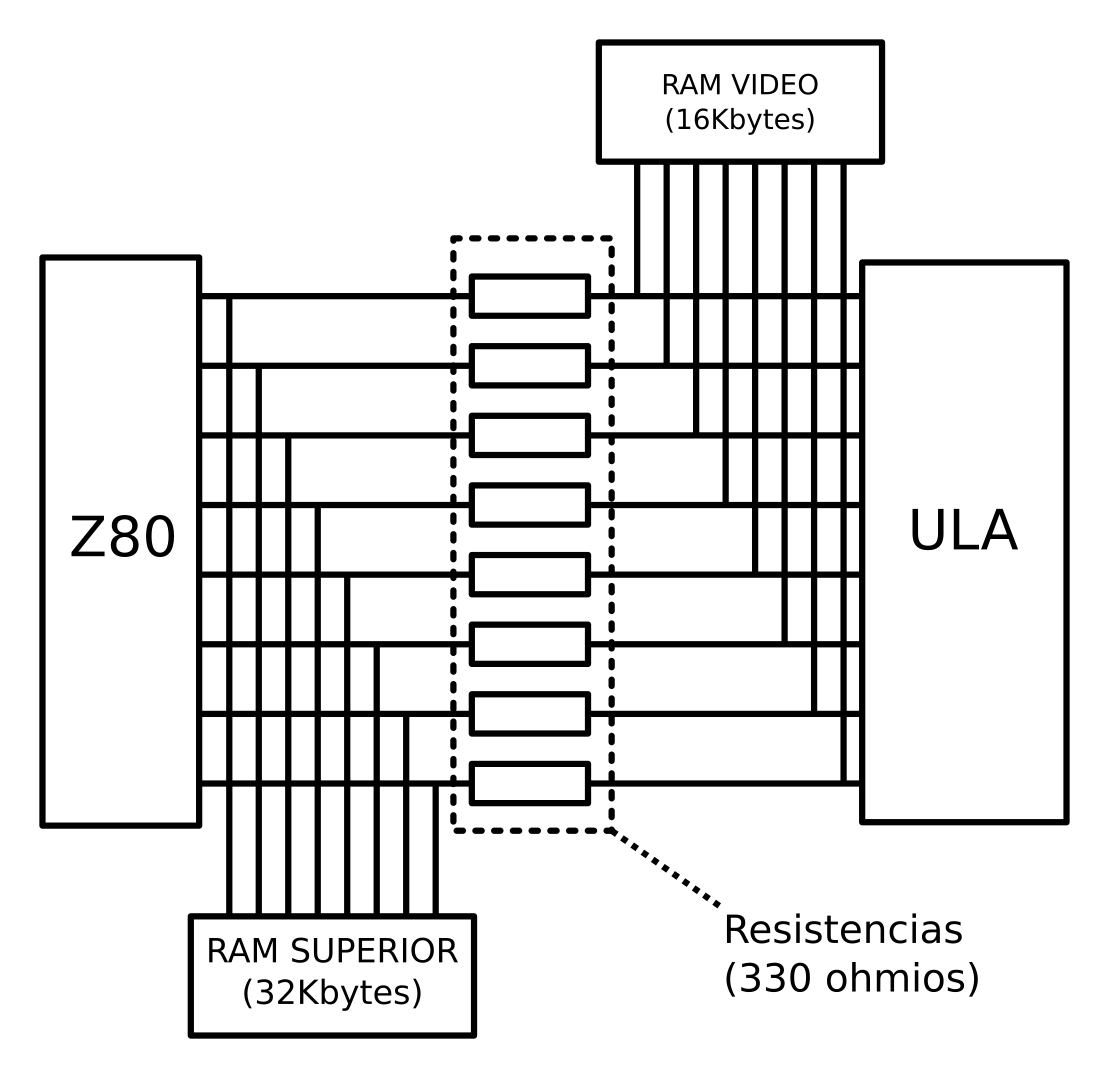
Existe, sin embargo, un caso en el que esto puede no cumplirse, y es si tenemos un periférico conectado a un ordenador real, y este periférico, por diseño, fuerza un valor diferente en el bus. Un ejemplo es el infame sistema de protección SD1 de Dinamic, utilizado en el Camelot Warriors. Se trata de un pequeño conector que incluye una resistencia de 1000 ohmios entre el bit D5 del bus de datos y masa, lo que hace que cuando se lee el bus, si ningún periférico fuerza un valor, se leerá 223 en lugar de 255. Según el artículo, esto también ocurría al leer del puerto 254, el de la ULA, lo que me hace sospechar que, para ahorrar celdas, la ULA sólo fuerza los bits 0-4 (teclado) y 6 (cassete), pero no hace nada con los bits 5 y 7.
Así que, por esto, realmente considero que no es necesario utilizar una tabla. Pero si te empeñas, cuidado en los modelos Plus 2A y Plus 3, pues dos de sus cuatro ROMs no empiezan con 0xF3, por lo que lo mejor es asegurarse de paginar la correcta antes. Eso sí, ya puestos, puede ser una mejor solución hacer una tabla de 256 elementos situada a partir 0xFF00 y con el valor 0xF3, lo que hará que la interrupción salte a la dirección 0xF3F3 (62451). Esto permite compactar algo más el código de las interrupciones.