DISCLAIMER: no seré responsable si alguien decide seguir mis pasos y se carga su aspiradora. En principio todo lo que cuento debería ser seguro, pero por motivos obvios no me puedo responsabilizar de lo que hagan otras personas, sólo de lo que haga yo.
¡Victoria, victoria! ¡Mi conga ya me hace caso!
Lo que hice fue escribir un nuevo servidor, esta vez desde cero, que combina HTTP y el protocolo específico de la conga. El código he decidido no hacerlo público hasta que termine el análisis completo, no vaya a ser que meta la pata en algo…
El motivo de no utilizar el código de http.server que ya tenía ha sido, fundamentalmente, porque debido a todos los trucos que tuve que utilizar para que funcionase, al final no usaba casi nada, con lo que me compensaba escribir mi propio servidor. Además, al hacerlo yo todo con select y sockets podía integrar mucho mejor en un único hilo la gestión del puerto 80 y la del 20008.
Básicamente creé una primera clase, BaseServer, que tiene un socket y que gestiona las funcionalidades básicas de éste, incluyendo un método vacío para cada vez que se reciben datos nuevos, y otros métodos para gestionar cuando se cierra. Sobre esta clase he construido absolutamente todo.
Luego creé la clase HTTPConnection, la cual es la que gestiona una conexión HTTP concreta. Cada vez que se hace una petición HTTP, se crea un objeto de este tipo, y es él quien analiza lo que llega. Su función es la misma que el código que hice antes con http.server. Para gestionar esto está la clase HTTPServer, que es la que abre el puerto 80 y crea los objetos anteriores tras cada conexión.
De la misma manera están las clases RobotConnection y RobotServer, pero esta vez para gestionar las conexiones al puerto 20008. El tenerlo dividido así permite controlar varios robots a la vez (aunque no creo que lo implemente de momento, no está de más que la arquitectura subyacente lo esté preparada).
La clase RobotConnection tiene un método llamado send_command, que lo que hace es, básicamente, emitir exactamente las mismas secuencias que registré anteriormente, copiadas byte a byte. Esto, al final, es bastante sencillo porque todos los comandos se emiten con el mismo tipo de paquete, y sólo cambia el número de comando y, en un par de casos, un parámetro extra.
Por otro lado, en base al contenido del segundo, tercero y quinto enteros de los paquetes enviados por la aspiradora puedo saber si es un paquete que espera una respuesta por mi parte, o un ACK de un comando enviado por mí, por lo que en el método de recepción de datos me limito a hacer una lista de comparaciones para ver qué tengo que responder; y si recibo una combinación desconocida, la imprimo.
Todas estas clases están gestionadas por una clase maestra llamada Multiplexer, que lanza primero una instancia de HTTPServer y otra de RobotServer, y va gestionando las nuevas instancias creadas por estos dos objetos mediante select.
Por último, hay una clase llamada Robot que está asociada permanentemente con un robot concreto, aunque éste no esté conectado. De momento se crea bajo demanda, pero en el futuro podría incluir algún tipo de persistencia, por ejemplo para que recuerde la configuración deseada por el usuario o los mapas, aunque se apague la aspiradora. Cada vez que un robot se conecta, se utiliza su identificador único para encontrar el objeto correspondiente y enlazarlo, y cada vez que se pierde la conexión, se informa de ello al objeto Robot para que borre la referencia al objeto RobotConnection.
Para la primera prueba decidí aprovechar el mismo servidor web que ya tengo para los robots e implementar un control sencillo por REST, mediante una sencilla página web. Es justo lo que se ve en el vídeo.
El siguiente paso es analizar y añadir los comandos para configurar el método de trabajo, la potencia del ventilador y el uso de la fregona, y por supuesto el control manual (aunque ya adelanto que parece que es en este caso donde entra en juego el puerto 8888 y la conexión directa con la tablet… a ver si hay suerte y me la puedo saltar).
También quiero analizar cómo se transmite la información de los mapas, pero eso será al final.
DISCLAIMER: no seré responsable si alguien decide seguir mis pasos y se carga su aspiradora. En principio todo lo que cuento debería ser seguro, pero por motivos obvios no me puedo responsabilizar de lo que hagan otras personas, sólo de lo que haga yo.
Hay que reconocer que cuando las cosas se complican, se complican de verdad. No se si lo que ha pasado demuestra que el programador que lo hizo es un genio y metió una sutil protección antihacking, o un chapuzas que hizo un código que funciona de milagro.
Me explico: decidí hacer una prueba rápida de la conexión de la aspiradora con un servidor mío, así que escribí un miniservidor con Python3 que escuchaba en el puerto 80, y que cuando recibía una petición a alguno de los documentos a los que responde el de bona robots (/baole-web/common/sumbitClearTime.do y /baole-web/common/getToken.do), anotaba los valores que pasaban y respondía lo que la aspiradora esperaba.
Pero claro, la aspiradora se empeña en conectarse a bl-app-eu.robotbona.com o a bl-im-eu.robotbona.com, así que tenía que engañarla para que se conectase a mi ordenador y no al servidor chino. La solución consistió en dos pasos:
primero, editar el fichero /etc/hosts de la Raspberry Pi que usaba como Access Point para conectar la aspiradora, y definir ahí esos dos dominios (además de robotbona.com, por si acaso), de manera que apuntasen a mi ordenador. Si la IP del ordenador fuese 192.168.0.89, habría que añadir:
relanzar dnsmasq en dicha Raspberry Pi con sudo systemctl restart dnsmasq, para que lea los cambios.
Y con esto, cuando la aspiradora se conecte a dicha red y pida la dirección IP de esos dominios, éste le devolverá la de mi equipo, con lo que lo usará como servidor en lugar del real. Por supuesto, cuando termine todo esto habrá que montar el servidor en la Raspberry y que todo se conecte a la WiFi normal, pero eso ya lo haré en el último capítulo.
Ahora bien, como utilicé el módulo http.server, mi programa no implementaba la parte del puerto 20008 (donde realmente se reciben todos los comandos), y como para ello tenía que hacer más cosas, decidí, de momento, no complicarme la vida para una simple prueba, y limitarme lanzar un netcat en dicho puerto en un terminal. Así, cuando la aspiradora se conectase, vería por la pantalla lo que ésta enviase.
Así pues, apagué y encendí la aspiradora, la puse en modo emparejamiento, la emparejé desde mi ordenador, ésta apagó su Access Point, se conectó a la WiFi, hizo la petición sumbitClearTime.do, mi servidor respondió, hizo luego la petición getToken.do, mi servidor respondió también… y volvió a pedir getToken.do… Y otra vez lo volvió a pedir… Y el netcat sin inmutarse.
Algo raro ocurría, porque después de pedir getToken.do, netcat debería mostrar una conexión, pero ahí no ocurría nada. Decidí probar a quitar la redirección en el DNS por si acaso le había pasado algo a la aspiradora, de manera que se conectase al servidor real, y entonces funcionó de nuevo.
Esto era muy raro, así que volví a configurar mi DNS y lancé el tcpdump en la Raspberry para capturar el tráfico que se intercambiaba entre la aspiradora y mi servidor, y ver qué podía estar pasando. Tenía que ser algo en la segunda orden, porque la primera sí funcionaba bien.
Comparé las respuestas de mi servidor simulado con las del servidor real y eran idénticas: los mismos campos, el mismo orden… ¡Espera, había una diferencia sutil entre los JSON que yo enviaba y los que enviaba el servidor! En mi caso, en getToken.do utilizaba las funciones de python para convertir de un diccionario a JSON, y éste lo estaba embelleciendo añadiendo espacios detrás de las comas, de los dos puntos, etc. Sin embargo, en sumbitClearTime.do generaba la cadena «tal cual», por lo que no tenía espacios, igual que la que enviaba el servidor. Aunque un JSON debería funcionar igual con ellos que sin ellos, probablemente quien escribió el código que lo analizaba en la aspiradora podría haber hecho la chapuza de esperarlo de una determinada manera (o bien exigirlo así para detectar hackeos), así que eliminé ese trozo de código y generé la salida «a pelo», juntando cachos de código. Ahora sí funcionaría.
Volví a lanzar todo, encendí la aspiradora, me senté a ver en pantalla las conexiones al servidor… y volvió a fallar otra vez. Había alguna otra diferencia. ¿Pero cual?
Volví a revisar todo, y me di cuenta de que mi código estaba enviando una línea con el nombre del servidor. En concreto, el campo Server valía BaseHTTP/0.6 Python/3.8.3, mientras que el servidor real no enviaba dicho campo.
El problema es que el módulo http.server no permite eliminar ese campo… ¿Como resolverlo? La solución consitió en sobrescribir el método send_header del objeto, de manera que ignorase dicho campo. Esto funciona porque el módulo la usa para añadir sus campos propios. Así pues, añadí esto al servidor:
def send_header(self, token, data):
if token != 'Server':
super().send_header(token, data)
¡Y con esto por fin funcio…! No, seguía fallando. No era eso tampoco.
Hmm… En el código de error estoy enviando, después del 200, el texto OK, mientras que su servidor no envía nada, sólo hay un espacio detrás del 200 y ya luego el retorno de carro. ¡Seguro que es eso!
¡Agh, tampoco! No lo entiendo, estoy enviando exactamente lo mismo que su servidor: tanto las cabeceras como el contenido es idéntico. ¿Por qué no funciona? Si abro el wireshark y comparo las capturas reales con las mías a nivel de byte… son iguales. ¿Qué demonios está pasando? Es exactamente lo mismo, con la única excepción de…
No…
No habrán sido capaces…
No pueden haberlo hecho…
Lo fueron. Resulta que su servidor envía en un solo paquete la cabecera HTTP y el primer bloque de los datos en formato chunk, y en un paquete diferente el segundo y último bloque de los datos chunk; o sea, esto va en un paquete IP:
Obviamente, en condiciones normales eso daría igual, pues TCP es un protocolo orientado a byte y se supone que da igual que un trozo viaje en un paquete IP y otro en el siguiente, pero es que esa era la única diferencia que quedaba, y efectivamente, en cuanto cambié el código para que lo emitiese de esa manera, por fin funcionó y se conectó al puerto 20008. ¿Será algún tipo de protección antihacking, o simplemente que, a nivel de programación del microcontrolador hicieron alguna chapuza? Sin analizar el firmware no puedo saberlo, y la verdad, es una tarea que, en este momento, no me llama nada. Pero da igual, porque lo importante es que…
DISCLAIMER: no seré responsable si alguien decide seguir mis pasos y se carga su aspiradora. En principio todo lo que cuento debería ser seguro, pero por motivos obvios no me puedo responsabilizar de lo que hagan otras personas, sólo de lo que haga yo.
Estaba empezando a preparar un programita para intentar dar órdenes a la aspiradora, y me encontré con que el emparejado no es tan sencillo como creía: simplemente entrando en el servidor web de la aspiradora y rellenando el formulario no era suficiente, así que tocaba seguir analizando.
Como ya comenté en la primera parte, cuando la aspiradora se pone en modo emparejamiento, lo que hace es convertirse en un punto de acceso WiFi con la IP 192.168.4.1, de modo que la app se conecta a dicha red y configura los parámetros de la WiFi real, además de algo más. Para conseguir esos datos, lo que hice fue ir de nuevo a mi Raspberry Pi configurada como punto de acceso, y modificar, primero, el fichero /etc/hostapd/hostapd.conf para dejarlo de manera que parezca una aspiradora. Para ello añadí un # a estas líneas para comentarlas y que no se procesasen (de manera que la red WiFi estaría abierta), y cambié el SSID por CongaGyro_123456:
A continuación, en /etc/dnsmasq.conf cambié los rangos de direcciones IP que se sirven para que sea 192.168.4.10 a 192.168.4.40, y asigné al gateway la IP 192.168.4.1.
Por último, edité el fichero /etc/dhcpcd.conf y en él asigné a la WLAN la dirección IP 192.168.4.1, la misma que tendría una aspiradora.
Tras esto reinicié la placa para que los nuevos valores tomasen efecto, entré por la ethernet, y lancé una instancia de netcat para que el puerto 80 estuviese abierto y me permitiese capturar todo. Al ser, además, un puerto por debajo de 1024, es necesario utilizar sudo:
sudo nc -l -p 80
Y tras esto, lo que hice fue ir a la app oficial, borrar mi aspiradora e indicarle que quería configurar una nueva. La app encontró la falsa aspiradora, se conectó a su WiFi, intentó configurarla mediante el puerto 80, y… ¡Bingo!
Vemos que envía algo más que el SSID y la clave; en concreto añade dos dominios de Internet, que es a donde se conecta para la parte HTTP y la parte de su propio protocolo. Es posible que se pueda cambiar directamente por la IP de un servidor, pero de momento prefiero montar un DNS propio y que tire de él, para asegurarme de que todo funciona.
Para estar seguro de que con esto ya funcionaba, escribí un pequeño programa en python que se conectase al puerto 80, enviase exactamente eso, y luego esperase la respuesta (por completitud). Obviamente, al ser HTTP, cada nueva línea tiene que ser con \r\n, y el final se indica con \r\n\r\n. Y esta fue la respuesta:
Actualizado: varios comandos de servidor a aspiradora terminaban con un LF. Añadidos.
DISCLAIMER: no seré responsable si alguien decide seguir mis pasos y se carga su aspiradora. En principio todo lo que cuento debería ser seguro, pero por motivos obvios no me puedo responsabilizar de lo que hagan otras personas, sólo de lo que haga yo.
Ahora que ya sabía la estructura básica del protocolo de la aspiradora, decidí escribir un pequeño programa en Python que me extrajese la información de manera más clara, y así no tener que andar con Wireshark, que es bastante peñazo. Con él tengo las secuencias y el orden en que se transmiten disponibles de un vistazo. El código se puede bajar desde mi web.
Lo primero que hice fue apagar completamente la aspiradora para que se borrase todo lo que tuviese en memoria, y emparejarla de nuevo, a ver si cambiaba algo en el proceso. Tras comparar ambas, todo es igual excepto:
el campo nonce
el campo sign (aunque esto es, probablemente, porque actualicé el firmware)
el campo token
el campo authcode
A mayores, la aspiradora envió una petición HTTP extra a POST /baole-web/common/uploadLog.do HTTP/1.1 con información de un fallo, pero no parece nada importante.
Siguiendo con el análisis, decidí que tocaba empezar a enviar comandos, así que inicié la captura de paquetes y ordené a la aspiradora que comenzase a funcionar. Este fue el resultado (el campo targetId es, en realidad, un valor hexadecimal aparentemente aleatorio, pero único para cada aspiradora, así que lo anonimizo aquí. Es el mismo valor todas las veces que aparece). El número decimal es el instante de tiempo (en segundos) desde que empecé a registrar los datos, y el sentido del paquete se indica con s->a si es de servidor a aspiradora, a->s si es de aspiradora a servidor:
Bueeeeeeno… menuda parrafada. Sin embargo empezamos a sacar ya cosas en claro: para poner en marcha la aspiradora y que comience a limpiar, la clave parece estar en este bloque, que parece servir para enviar un comando específico: en este caso, el servidor envía un paquete con el comando 100, como se especifica en transitCmd.
Otro detalle interesante es que siempre que la aspiradora envía un paquete, su séptimo byte es 00, pero si lo envía el servidor es C8. Esto también se cumplía en las comunicaciones anteriores, salvo en los paquetes ping, los que aparentemente sólo son necesarios para mantener la comunicación. A pesar de todo, esa parte aún va a requerir más investigación.
Una vez que la aspiradora está en marcha, el servidor envía repetidamente el comando 131, el cual parece que pide a la aspiradora que devuelva información sobre su posición y estado actual.
La darle a la opción de dejar de aspirar, los comandos que se intercambian son:
Y, efectivamente, el comando es el 104. ¿Serán pares todos los comandos?
Además, parece que cuando la aspiradora ha llegado al cargador, emite automáticamente una trama para indicarlo (la del instante de tiempo 13.785572052001953). También vemos que el servidor envía repetidamente el comando 131 durante el trayecto, lo que parece confirmar que, efectivamente, se utiliza para pedir la posición y estado de la aspiradora mientras se está moviendo.
Y con esto ya están analizados los tres comandos más importantes. En la próxima entrega intentaré enviar yo mis propios comandos haciéndome pasar por el servidor, y en la cuarta espero analizaré el resto de comandos: selección del modo de aspirado, potencia del motor, fregona y control manual.
Actualizado: varios comandos de servidor a aspiradora terminaban con un LF (o sea, \n). Añadidos.
Recientemente decidí comprarme un aspirador robótico, así que empecé a ver opciones. Es cierto que, siendo el primero, no quería gastarme mucho por si no me convencía, pero a la vez no quería tampoco comprar algo cutre que luego no funcionase. Así que al final, después de mucho pensar, decidí comprarme un Conga de Cecotec. Mi intención era comprar el más bajo de gama, pero estaba agotado, así que al final me pillé el Conga 1490, que tiene como característica diferenciadora que se puede controlar desde el móvil.
Y claro, me ponen un caramelito así, delante, y lo primero que se me pasó por la cabeza fue «no estaría mal meter las narices a ver cómo funciona».
Sin embargo, cuando me leí las condiciones de uso de la app y descubrí que envía tu IP, tu correo-e y los mapas que hace la aspiradora no sólo a Cecotec (que, a fin de cuentas, es una empresa española y está sujeta a las normas comunitarias de protección de datos), sino directamente al verdadero fabricante, que es chino (y te dicen claramente que él sí que no está sujeto a esas normas), la cosa empezó a mosquearme, y mis ganas de tocar dentro aumentaron bastante.
Pero no se vayan todavía, que aún hay más… resulta que se me ocurre ver qué permisos pide para funcionar, y me encuentro con que en el manifiesto pide, entre otras cosas:
hacer llamadas
acceso total a Internet
acceso al micrófono
acceso a la cámara y al flash
acceso de lectura y escritura a todo el almacenamiento del dispositivo
obtener datos del propietario
acceso a los logs del sistema
acceso a la lista de aplicaciones
arrancar automáticamente en el inicio del sistema
Esto ya me parecía el colmo: una aplicación china con acceso a TODO, y que encima se lanza automáticamente en el arranque… ni-de-co-ña.
Y sí, se lo que dirán algunos: la mitad de esos permisos (cámara, micrófono, llamadas y almacenamiento) no sólo se pueden desactivar en las propiedades de la aplicación, sino que, de intentar usarlos, el sistema operativo avisaría; y la otra mitad (acceso a datos del propietario y lista de aplicaciones) han sido eliminados en versiones recientes de Android. Pero pese a todo, es una cuestión de que no basta con ser bueno, también hay que parecerlo. Y esta app, por mucho de que en la práctica no haga nada malo, que dejen todo eso así queda, como mínimo, feo.
Pero es que, además, como veremos luego, la app y la aspiradora precisan de una conexión a internet para trabajar, lo que significa que si, por el motivo que sea, el fabricante decide que ya no le compensa tener encendido su servidor, MI aspiradora, por la que he pagado dinero, dejará de funcionar de la manera que me vendieron que funcionaría.
Así que toca arremangarse y empezar a trabajar.
DISCLAIMER: no seré responsable si alguien decide seguir mis pasos y se carga su aspiradora. En principio todo lo que cuento debería ser seguro, pero por motivos obvios no me puedo responsabilizar de lo que hagan otras personas, sólo de lo que haga yo.
Lo primero que hice fue echar un vistazo al manual, y como cabía suponer, la aspiradora tiene WiFi y hay que emparejarla primero con el router. Para ello hay dos maneras, la automática y la manual. En ambos casos se comienza pulsando el botón de encendido de la aspiradora durante tres segundos, de manera que el piloto de la WiFi empieza a parpadear, y a continuación se mete la clave de la WiFi en la app (el SSID ya aparece, poniendo por defecto el mismo que usa el móvil).
Ahora, en modo automático, simplemente se deja que sea la propia app quien configure todo. Sin embargo, en modo manual hay que ir a Ajustes -> WiFi en el móvil y escoger una red con el identificador CongaGyro_XXXXXX, pulsar el botón de configurar, y volver a la WiFi normal. Efectivamente: al ponerse en modo emparejamiento, la aspiradora se convierte en un punto de acceso sin clave.
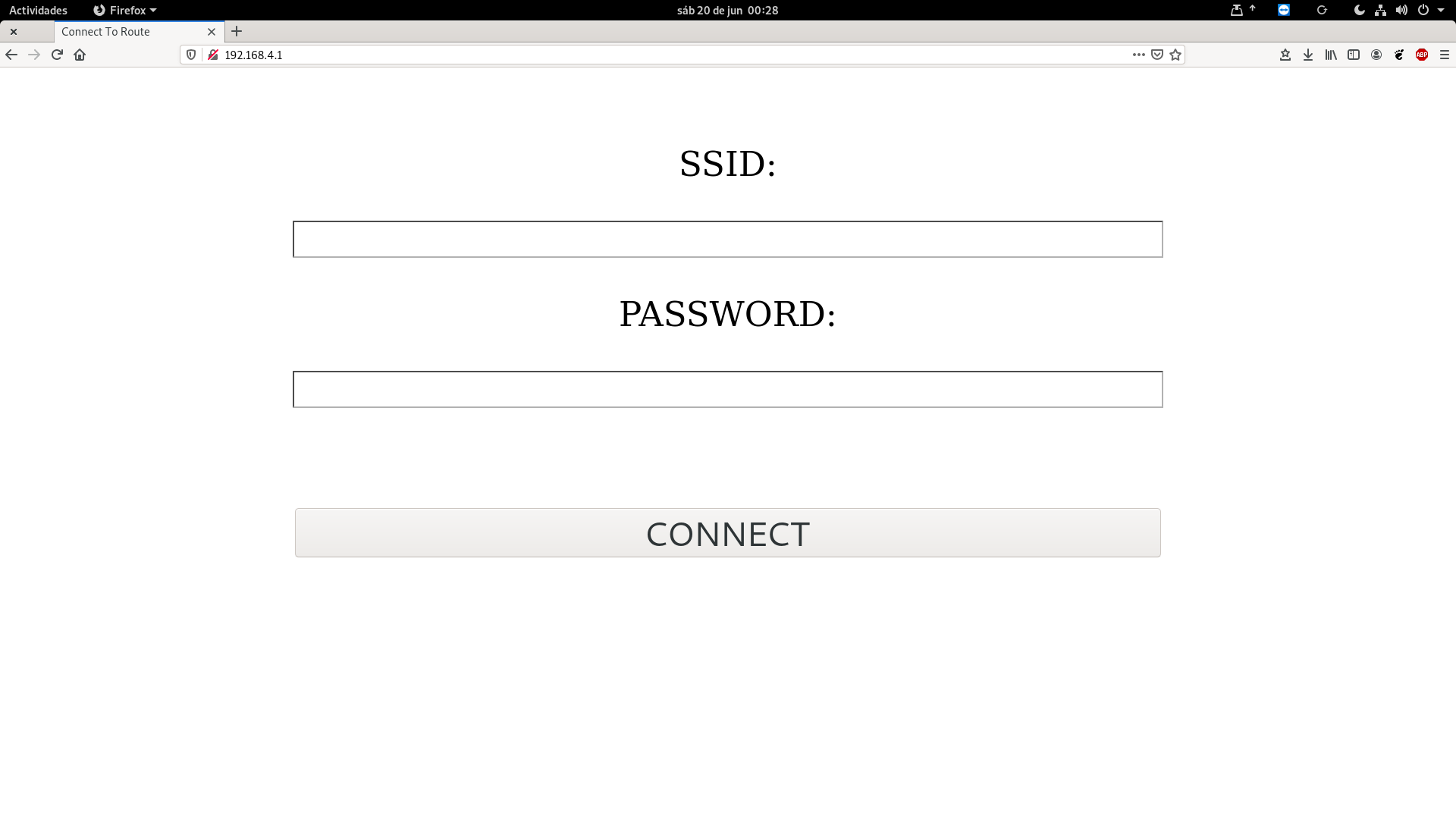
El primer paso, por tanto, era obvio: poner la aspiradora en modo emparejamiento, conectarse a esa WiFi desde el portátil (en mi caso me dio la IP 192.168.4.2), y hacer un escaneo de puertos con nmap:
nmap -p 1-49151 192.168.4.1
Y tal y como cabía esperar, el puerto 80 está abierto, y al entrar desde un navegador aparece esta página:
Tras escribir el SSID y la clave de mi WiFi, devuelve una página con un OK y el punto de acceso desaparece. Una simple comprobación con nmap nos devuelve la nueva IP de la aspiradora, ahora sí en la WiFi de verdad.
nmap -sP 192.168.18.0/24
Por supuesto, cada uno tiene que cambiar la IP por el valor de las IPs internas de su red. Una vez encontrada la IP, un nuevo escaneo de puertos me dejó descolocado: no había absolutamente ninguno, todos estaban cerrados a cal y canto.
Decidí que poco más podría hacer sin instalar la aplicación y esnifar los datos que intercambiaba con el aspirador, pero no me hacía ninguna gracia meterla en mi móvil, así que cogí una vieja tablet que no usaba para nada, la formateé, la registré con una cuenta de correo creada ex profeso, y me fui a la Play Store a instalar la app…
Y no estaba.
Probé con todo tipo de combinaciones, pero aunque estaban algunas otras apps de Cecotec, la que había visto para la Conga 1490 y 1590 no aparecía por ninguna parte. Curiosamente fue lo mismo que me ocurrió cuando probé con un Android X86 corriendo en una máquina virtual… Mi conclusión es que, dado que en el manifiesto de la app pide permitir hacer llamadas, la Play Store sólo deja instalarla en dispositivos con tarjeta SIM.
Sin embargo, si nos bajamos el APK desde otra fuente, lo copiamos a la tablet y lo instalamos (tras permitir la instalación desde fuentes no confiables, claro) la aplicación funciona perfectamente.
Con ella ya instalada, llega la segunda parte: configurar un punto de acceso que nos permita esnifar todo el tráfico. El problema surge cuando nos damos cuenta de que es muy difícil hacer eso en WiFi, así que mi solución fue usar una Raspberry Pi configurada como punto de acceso, y correr en ella tcpdump para capturar todo el tráfico que pasase.
Para configurar una Raspberry Pi como punto de acceso basta con seguir estas instrucciones:
Yo utilicé la res 192.168.18.X para la WiFi, y así asegurarme de que no haya interferencias con nada más. Luego, para capturar todo el tráfico, uso el comando:
Siendo 192.168.18.4 la dirección IP de mi ordenador de sobremesa, para que no capture los paquetes que se intercambian cuando entro por SSH, y así tener una captura limpia. El parámetro w almacena los paquetes en bruto en el fichero datos.pcap, lo que nos permite luego abrirlo en, por ejemplo, WireShark, para analizarlos con más detenimiento.
Y con esto está todo listo para empezar, así que puse en marcha la captura de paquetes, y en la tablet lancé la aplicación, rellené los campos con una dirección de correo nueva, creada para la ocasión, emparejé la aspiradora, y lancé un escaneo de puertos… ¡y ahora la aspiradora tenía uno abierto, el 8888!
Buena cosa, pues, pero ahora tocaba parar la captura y empezar a analizar qué habían hecho la aspiradora y la app.
Una vez copiado el fichero con el volcado, procedí a abrirlo con el Wireshark. Lo primero que hace la aspiradora, como cabe esperar, es obtener una IP, pero luego resulta que lo siguiente que hace es conectarse a Ibl-app-eu.robotbona.com, y enviar una petición POST a baole-web/common/sumbitClearTime.do con un formulario con el siguiente contenido (en realidad va en formato URLEncode:
Donde xxxxxxx e yyyyyyy son unas ristras de números hexadecimales que, probablemente, identifiquen a mi aspiradora. La respuesta es un OK con el siguiente texto:
2b {"msg":"ok","result":"0","version":"1.0.0"} 0
Que resulta ser un bloque en formato chunked con un resultado en formato JSON. A continuación otra conexión al mismo servidor, pero esta vez pidiendo:
Una vez más lo he anonimizado just in case. La respuesta es la misma que antes:
2b {"msg":"ok","result":"0","version":"1.0.0"} 0
Hasta aquí la aspiradora se ha conectado al puerto 80 del destino, lo que es consistente con el uso de REST. Sin embargo, ahora la aspiradora se conecta al puerto 20008 del destino, y comienza un intercambio de mensajes diferente. La siguiente petición desde la aspiradora es un bloque que comienza con una secuencia de 20 bytes binarios, seguidos por 349 bytes en ASCII en formato JSON (el JSON, en realidad, se transmite en una única línea y sin formato, pero lo he embellecido para mejorar la lectura. Si en algún punto incluyese un LF, incluiría el símbolo \n):
Aquí ya empieza a haber cosas interesantes: la aspiradora comunica al servidor cual es la IP interna y el puerto que ha abierto para comunicarse. Estos datos son importantes para la app. Se repiten los campos deviceId, appKey y authCode de mensajes anteriores, pero ahora se añade un token.
La respuesta también es complicada. En este caso es de 99 bytes, y comienza también con una ristra de 20 valores binarios, seguido de 79 bytes con un JSON normal:
En el primer mensaje, los dos primeros bytes en formato little endian forman el número 369, que coincide con la suma de los 20 bytes binarios y los 349 bytes de JSON. En el segundo mensaje, los dos primeros bytes coincide con 99 en decimal, por lo que parece que, como mínimo, los dos primeros bytes indican el tamaño de la respuesta, probablemente para poder reservar la cantidad de memoria que necesite en el momento, y no tener que reservar de más, o ampliando bloques. ¿Qué significan el resto de bytes? De momento no tenemos información suficiente para saberlo.
En este punto, la app se conecta a la aspiradora y empieza a intercambiar datos con este mismo formato, pero de momento vamos a dejar esa parte de lado, pues esta conexión con el servidor remoto sigue estando activa. De hecho, 30 segundos después del envío anterior, la aspiradora envía de nuevo otra secuencia, en concreto:
Lo interesante es que empieza a haber un patrón aquí. Si asumimos que son cinco números de cuatro bytes cada uno, el cuarto número es un número de secuencia: en efecto, comienza en 2 en la primera petición, y su respuesta tiene el 2 también. La siguiente petición tiene el valor 3, y su respuesta también. Luego viene el 4, y otra vez la respuesta, el 5 y otra vez la respuesta, el 6 y su respuesta… Además, el resto de los números de las peticiones y respuestas 4, 5 y 6 son iguales, lo que hace suponer que se utilizan para mantener la conexión activa. Por otro lado, en las peticiones, el quinto byte tiene el bit 0 a cero, y en las respuestas están a uno. En el sexto byte, además, el bit 0 está a cero en peticiones con datos, y a 1 en las que son sólo para mantener la conexión.
Veamos ahora qué pasa con la app en sí. Como ya dije, se conecta al puerto 8888, pero lo raro es que establece dos conexiones en vez de una. ¿Por qué? Ni idea. Pero veamos con calma qué hace.
En la primera conexión tenemos este intercambio, antes de que la aspiradora la cierre (t es tablet, a es aspiradora):
Estoy preparando una entrada nueva y me apeteció añadir memes en el texto, porque ayudan a leerlo al permitir descansar la vista entre párrafo y párrafo, y le dan un toque más divertido y agradable.
Por desgracia, la cosa no es tan sencilla. Una primera opción es buscar GIFs animados, pero esto tiene varios problemas:
El tamaño de un GIF es bastante grande
El número de colores es limitado
La solución obvia es utilizar vídeos en su lugar, algo que WordPress soporta perfectamente. Para ello hay que embeberlo, activar la reproducción automática, el bucle, quitar los controles y, sobre todo, quitar el sonido. Esto último es muy importante, pues si no, el navegador se negará a reproducirlo hasta que el usuario haya interaccionado con la página (lo que obliga a haber hecho click en ella, pero no sirve con hacer scroll). El motivo para esto es evitar que una página recién cargada empiece a reproducir sonido por sorpresa, pues es algo muy molesto. Si no se hace, el vídeo no se reproducirá hasta que el usuario lo ponga en marcha a mano.
Aunque es muy fácil, por desgracia tiene el problema de que obliga a acordarse de todos los pasos, con lo que es bastante sencillo que, por despiste, se nos cuele alguno y nos quede el meme mal. Por eso decidí hacer un poco de JavaScriptpara solucionar esto de manera sencilla.
Lo primero es bajarse algún plugin que permita añadir JavaScript a nuestra plantilla. Yo uso WordPress, por lo que escogí Simple Custom CSS and JS. Una vez instalado y activado, sólo tenemos que añadir en nuestra plantilla este trozo de código:
let memeList = []; function setPlayStatus(element) { // check if it is visible var rect = element.getBoundingClientRect(); let isVisible = ( rect.bottom >= 0 && rect.right >= 0 && rect.top <= (window.innerHeight || document.documentElement.clientHeight) && rect.left <= (window.innerWidth || document.documentElement.clientWidth) ); if (isVisible != element.memeData.isVisible) { if (isVisible) { element.memeData.video.play(); } else { element.memeData.video.pause(); } element.memeData.isVisible = isVisible; } }
function checkForMemes() { let elements = document.getElementsByTagName(«figure»); for (let element of elements) { if (!element.classList.contains(‘meme’)) { continue; } memeList.push(element); element.memeData = {}; for (let child of element.childNodes) { if (‘controls’ in child) { element.memeData.video = child; element.memeData.isVisible = false; child.muted = true; child.controls = false; child.loop = true; child.autoplay = true; setPlayStatus(element); } } } }
function refreshMemesStatus() { for (let meme of memeList) { setPlayStatus(meme); } return true; }
Con esto lo único que tenemos que hacer es añadir al elemento video la clase CSS meme, y automáticamente se establecerán los parámetros necesarios para que el vídeo funcione a la primera. A mayores, cuando el meme/vídeo se sale de la zona visible de la pantalla, se le da la orden de pausa para que no consuma nada de procesador. Aunque es probable que los navegadores lo tengan en cuenta, no es mala idea dejar indicado de manera explícita que nos da igual que el vídeo no siga avanzando mientras no lo vemos.
Utilizamos cookies para garantizar que tenga la mejor experiencia en nuestro sitio web.