Para un juego, es necesario leer el teclado. Normalmente el Spectrum utiliza la interrupción de la ULA para llamar a la rutina de lectura del teclado situada en la dirección 0x38. Sin embargo, en la última entrada vimos cómo utilizar el modo 2 de interrupciones para llamar a nuestra propia función de respuesta. Eso significa que ya no se llama a la vieja función.
La primera solución consiste en llamar nosotros al final de nuestra ISR a la rutina de lectura de teclado en la dirección 0x38 (página 6), pero el código de la ROM es bastante complejo pues realiza muchas funciones extra, tales como decodificar la tecla concreta y gestionar la autorrepetición. Además, asume que puede escribir en las variables del sistema del Spectrum, las cuales no tienen por qué existir si hemos arrancado un emulador desde un fichero .Z80.
Otra solución consiste en llamar a la rutina KEY-SCAN de la ROM, en la dirección 0x028E, que se llama desde la anterior y es la misma que se utiliza para la funcion INKEY$. Sin embargo, sigue siendo demasiado complicada para lo que necesitamos, pues realmente para un juego no necesitas detectar SHIFT + tecla, por ejemplo. Por eso decidí hacer mi propia rutina de escaneo de teclado. Esto me ha permitido reducir al mínimo su complejidad y, sobre todo, el tiempo que necesita para ejecutarse. Para entenderla, empecemos por ver cómo es el teclado en el Spectrum:
Vemos que las cuarenta teclas forman una matriz de 5×8 teclas. Las columnas están conectadas por un lado a 5 voltios a través de unas resistencias de 10Kohms, las cuales mantienen a las líneas a uno lógico por defecto. Por el otro lado, las cinco columnas están conectadas a la ULA, que es quien se encarga de enviar al procesador el dato cuando se lee del puerto 254. En cuanto a las filas, vemos que están conectadas a las ocho líneas superiores del bus de direcciones (y para evitar cortocircuitos, mediante un diodo 1N4148).
Si todas las líneas A8-A15 están a 1, da igual que pulsemos una tecla o no, pues la línea correspondiente del bus de datos (D0-D4) recibiría cinco voltios. Sin embargo, si colocamos una de estas líneas del bus de direcciones a 0 y pulsamos una tecla cualquiera de dicha fila, el pulsador de la tecla conectará dicha fila a la columna correspondiente, con lo que el procesador leerá un 0 en esa línea.
Así, si queremos saber si la tecla B, por ejemplo, está pulsada o no, tenemos que poner A15 a cero y el resto (A14-A8) a uno, leer el puerto 254, y comprobar si D4 está a cero (en cuyo caso la tecla estará pulsada) o a uno (en cuyo caso la tecla no estará pulsada).
Veamos ahora mi rutina de lectura de teclado:
ld BC, 0xFEFE
ld DE, 0x001F
IM2_LOOP:
in A, (C)
cpl
and E
jr NZ, IM2_LOOP2
rlc B
ld A, 0x20
add A, D
ld D, A
jr NC,IM2_LOOP
IM2_LOOP2:
or D
ld (CURRENT_KEY), A
Dado que vamos a usar IN A, (C), empezamos cargando 0xFE en el registro C para direccionar el puerto 254 (el de la ULA) y leer el teclado. Además, cargamos también 0xFE en B pues su valor será el que aparezca en la parte superior del bus de direcciones. Por otro lado, ponemos D a cero, pues lo usaremos para contar las semifilas en sus tres bits superiores.
Ahora leemos el puerto 254 y así tendremos el valor en el registro A. Invertimos los bits de manera que la tecla pulsada esté a uno en lugar de a cero, y eliminamos los tres bits superiores, que no se necesitan para nada (recordemos que el bit D6 es el del puerto del casete, y su valor, en ausencia de señal, suele ser aleatorio). Si el valor es cero significa que no hay ninguna tecla pulsada en esta semifila, así que rotamos B a la izquierda de manera que el bit que está a cero pase a la siguiente posición, y así escanear la siguiente semifila. Le sumamos también 32 al valor actual de D para contar la siguiente semifila. Hecho esto, si detectamos acarreo tras la suma significa que ya hemos hecho las ocho semifilas y podemos salir del bucle.
Sin embargo ¿qué pasa si el valor leído no es cero? Eso significa que alguna tecla está pulsada. En ese caso lo que hacemos es mezclar con una operación OR el valor leído y el del registro D, de manera que los cinco bits inferiores tendrán un bit a 1 por cada tecla pulsada en la semifila, y los tres bits superiores tendrán el número de semifila en la que se ha detectado la pulsación.
Obviamente esta función es muy sencilla, pero es suficiente para asignar un valor de ocho bits único a cada tecla pulsada, aunque no es capaz de identificar bien si hay varias pulsaciones simultáneas (sólo si son de la misma semifila), pero para lo que necesitaremos es más que suficiente.
Sin embargo, lo interesante de esta rutina es que es MUY rápida. En concreto, en el peor de los casos tardará 528 Testados en ejecutarse. Eso es menos de lo que duran tres scanlines, lo que significa que podemos ejecutarlo antes del bucle que detecta cuando empieza la ULA a pintar en la zona del PAPER de la pantalla, pues la zona del BORDER que está antes son 64 scanlines, por lo que tenemos tiempo más que de sobra. El resultado es que podemos aprovechar parte de ese tiempo que nos quedábamos esperando.
La tecla pulsada se almacena al final en la posición de memoria CURRENT_KEY, y será cero si no hay ninguna pulsada, o un valor único para cada tecla si sí está pulsada. Para asociar cada valor a una tecla basta con saber que los tres bits superiores contienen la semifila (000 -> A8, 001 -> A9, … , 110 -> A14, 111 -> A15), y los cinco bits inferiores qué teclas están pulsadas en esa semifila.
Y con esto ya tenemos todo listo para empezar a pintar el MAPA.
En esta entrada vamos a hacer un cambio pequeño en el código para que pinte mediante interrupciones. Aunque ya antes utilizábamos la instrucción HALT para sincronizarnos con las interrupciones y saber cuando empezar a pintar en pantalla, tiene el inconveniente de que desperdiciamos tiempo, tiempo que podríamos aprovechar para ir adelantando trabajo. Aunque ahora mismo no hay nada que hacer entre que hemos pintado un frame y esperamos a que el barrido de pantalla vuelva al principio, en el futuro, cuando implemente la lógica del juego, tiene sentido que una vez que hemos terminado de pintar los sprites en el buffer intermedio, y esperamos a que termine de trazarse en pantalla en frame actual, podamos ir adelantando trabajo ejecutando la lógica del juego en sí, en lugar de desperdiciar un tiempo precioso simplemente no haciendo nada.
El Z80 tiene dos tipos de interrupciones: enmascarables (INT) y no-enmascarables (NMI). La interrupción no enmascarable siempre se atiende: cada vez que un periférico ponga a cero el pin 17, en cuanto el procesador termine de ejecutar la instrucción actual, guardará la dirección actual del contador de programa y saltará a la dirección 0x66. Para retornar de una NMI se utiliza la instrucción RETN. En el Spectrum, sin embargo, esta interrupción está bloqueada por software, pues en la dirección 0x66 está la ROM con una rutina que comprueba dos bytes de la RAM: si valen 0, saltará a la dirección que contengan dichos bytes (o sea, a la dirección 0x0000, con lo que el ordenador se reiniciará), mientras que si tienen un valor diferente, simplemente retornará sin hacer nada, con lo que el resultado es que, sencillamente, no se puede utilizar para nada. Lo «divertido» es que sólo cambiando un bit en esa rutina el comportamiento sería exactamente el opuesto: si la dirección almacenada es cero, retornaría; y si es diferente, saltaría a dicha dirección, lo que sería un comportamiento muchísimo más útil. Lo más probable es que fuese un cambio de última hora para evitar que se pueda utilizar de manera sencilla para copiar programas.
La interrupción enmascarable, por su parte, se llama así porque es posible desactivarla (en el Z80 mediante la instrucción DI; tras ejecutarla, no se responderá a ninguna INT; para activarlas de nuevo se utiliza la instrucción EI). Como ya dijimos, en el Spectrum se genera una cada vez que la ULA comienza a pintar un nuevo frame en la pantalla, en el primer scanline del BORDER (salvo que estemos en un Inves Specrum+, en cuyo caso la interrupción se genera justo al comenzar a pintar la zona de PAPER). El Z80 tiene tres modos de trabajo para estas interrupciones, seleccionables mediante las instrucciones IM0, IM1 e IM2.
En el modo IM0 (que es el modo por defecto cuando se resetea el procesador, y compatible con el 8080 de Intel), cuando un periférico pone a cero el pin 16 para solicitar una interrupción, tiene que poner, además, en el bus de datos el código de una instrucción para que el procesador la ejecute. Normalmente esa instrucción será una de las ocho instrucciones RST (RST #00, RST #08, RST #10, RST #18, RST #20, RST #28, RST #30 o RST #38) para saltar a una dirección de memoria concreta y ejecutar ahí una rutina de interrupción, aunque en teoría podría ser cualquier instrucción, incluso instrucciones de varios bytes.
En el modo IM1, que es el modo que utiliza la ROM del Spectrum por su simplicidad, cada vez que se produce una INT se saltará a la dirección 0x38, por lo que tiene un comportamiento similar a la NMI, aunque a una dirección diferente. Cabe señalar que el opcode de la instrucción RST #38, que hace una llamada a subrutina a la dirección 0x38, es 255, lo que significa que el Spectrum se comportará igual tanto en modo 0 como en modo 1. En efecto, si recordamos, cuando leemos el bus y nadie está poniendo un dato, leeremos 255, por lo que si el procesador está en modo 0, será eso lo que lea y ejecutará una instrucción RST #38, que saltará a la misma dirección que si estuviésemos en modo 1.
Finalmente, el modo IM2 es el más versátil, aunque también el más complejo de utilizar. Cuando estamos en este modo y se produce una INT, el procesador lee el bus de datos y lo utiliza como la parte baja de una dirección de memoria. La parte alta la tomará del contenido del registro I. Una vez hecho esto, leerá el contenido de esa posición de memoria y de la siguiente y saltará a la dirección de memoria indicada por esos dos bytes leídos. La idea es que si cargamos el registro I con el valor 0xYY, debemos almacenar una tabla de 256 bytes a partir de la dirección 0xYY00 conteniendo direcciones de memoria de las rutinas de interrupción de cada periférico que pueda generar una interrupción. La idea original es que cuando un periférico genere la interrupción, pondrá en el bus de datos el offset o desplazamiento en la tabla en que se encuentra la dirección de memoria de su rutina de gestión. Así, supongamos que I vale 0xF0, y que tenemos esta tabla a partir de 0xF000:
DEFW 0x4012
DEFW 0x5200
DEFW 0x2103
Si tuviésemos un periférico que genera una interrupción y pone el valor 0 en el bus, el Z80 compondrá la dirección 0xF000 (usando el registro I y el valor presente en el bus), y leerá los dos bytes que haya en dicha dirección. En este caso leerá 0x4012, así que comenzará a ejecutar código a partir de esa dirección, que se supone que será el código para gestionar ese periférico concreto. En cambio, si otro periférico genera una interrupción y pone el valor 4 en el bus, el Z80 compondrá la dirección 0xF004 y leerá en dicha zona de la tabla el valor 0x2103, y será esa la dirección de memoria en la que comenzará a ejecutar código. Este sistema permite que cada periférico indique quien es a la vez que genera una interrupción, de manera que el Z80 puede saltar directamente a la rutina que lo gestiona. Por supuesto, la única manera de aprovechar al 100% las tablas es si todos los valores que pueden poner los periféricos son pares, o impares, pues si se mezclan, algunos periféricos podrían llamar a una rutina compuesta por parte de una dirección y parte de la siguiente.
Sin embargo, en el Spectrum no tenemos ningún periférico que trabaje así: el único periférico que genera interrupciones es la ULA, y ésta no pone ningún valor en el bus, por lo que éste siempre valdrá 255. Eso significa que, en teoría, sólo necesitamos una única entrada en nuestra tabla; pero siendo un valor impar, vemos que se «saldría por arriba», en el sentido de que se utilizarían los bytes de las direcciones 0xF0FF y 0xF100.
Veamos un ejemplo de código para inicializar las interrupciones, y cómo lo integramos con nuestro código actual:
ORG 32768
; buffer intermedio de pantalla
BUFFER:
DEFS 6912
; espacio vacío para tener INTM2 alineado en el punto que necesitamos
DEFS 255
INTM2:
DEFW IM2FUNC
[...]
INIT_IM2:
di
ld a, 0x9B
ld i, a
im 2
ei
ret
[...]
IM2FUNC:
; código a ejecutar por la interrupción
[...]
RETI
Vemos que el código que ya teníamos empezaba en la dirección de memoria 0x8000 (o sea, 32768, tal y como especifica el ORG del principio). A continuación tenemos el buffer intermedio, donde pintamos los sprites para que más tarde, cuando hayamos terminado, se vuelque de manera sincronizada en el buffer de pantalla. Este bloque termina en la dirección 0x9AFF, lo que significa que el primer byte libre está en 0x9B00, y como es una dirección redonda (tiene la parte baja a cero) nos sirve para meter la tabla de interrupciones. Sin embargo, recordemos que el bus del Spectrum siempre valdrá 255 (aunque de esto hablaré más un poco más adelante), así que no necesitamos poner la tabla entera, sino sólo la última entrada, y eso es lo que hacemos: dejamos 255 bytes libres, y justo a continuación reservamos dos bytes. Esos 255 bytes los podemos aprovechar para meter otras variables (por ejemplo, la tabla de direcciones de la rutina de volcado del buffer intermedio, u otras), pues no se utilizan para nada.
Vamos ahora a la función INIT_IM2: lo primero que tenemos que hacer es desactivar las interrupciones, pues no queremos que nos llegue una justo en mitad de la configuración y que el procesador salte a vete-tú-a-saber-donde. Una vez hecho esto, cargamos el registro I con el valor 0x9B, de manera que apunte a la tabla que hemos definido antes (que, como recordamos, empieza precisamente en la dirección de memoria 0x9B00). A continuación cambiamos a modo 2, activamos las interrupciones, y salimos.
Ahora, cada vez que la ULA genere una interrupción, al estar el procesador en modo 2 procederá a leer el bus de datos, que valdrá 255, y lo combinará con el registro I para componer la dirección de memoria 0x9BFF. Ahora leerá el valor de 16 bits de dicha dirección, que es justo el que está almacenado en INTM2 gracias a los espacios que hemos dejado en el código, y este valor será el de la dirección de la rutina IM2FUNC, por lo que pasará a ejecutar su código. Cuando termine, tenemos que retornar con RETI para que restaure el estado de las interrupciones (en lugar de RETI también podríamos utilizar EI + RET, pues EI tiene la particularidad de que activa las interrupciones después de la siguiente instrucción, por lo que no hay peligro de que llegue justo una interrupción entre el EI y el RET y que la pila se llene sin control).
Integrando las interrupciones
Todo esto está muy bien, pero ¿y qué se supone que hacemos ahora? Pues la idea consiste en reservar una dirección de memoria para indicar a la rutina de interrupciones que ya hemos terminado de pintar en el buffer intermedio, y que ya puede copiarlo en la pantalla cuando pueda. Y en la rutina de interrupciones lo que pondremos será el código de nuestra vieja amiga paint_screen, la rutina que vimos en las tres primeras entradas para volcar el buffer intermedio en la pantalla real. La idea sería algo así:
DO_REPAINT:
; esta variable nos servira para notificar que el buffer
; intermedio está listo para ser volcado a la pantalla (si vale 1)
DEFB 0
IM2_FUNC:
; Esta es la ISR para la interrupción. Se ejecutará cada vez
; que la ULA genere una interrupción
push AF
ld A, (DO_REPAINT)
and A
jp Z, IM2_EXIT ; si DO_REPAINT vale cero significa que el buffer
; intermedio aún no está listo, así que no hacemos
; nada
push BC
push DE
push HL
exx
push BC
push DE
push HL ; Tenemos que preservar todos los registros que
push IX ; utilicemos dentro de paint_screen
; código de paint_screen
pop IX
pop HL
pop DE
pop BC
exx
pop HL
pop DE ; y restaurarlos al terminar, antes de retornar
pop BC
xor A
ld (DO_REPAINT), A ; notificamos que hemos terminado
IM2_EXIT:
pop AF
reti ; y devolvemos la ejecución al código principal
[...]
; código principal. Pintamos la pantalla en el buffer intermedio
[...]
; ya terminamos de pintar la pantalla, así que notificamos
; que hemos terminado poniendo DO_REPAINT a 1
ld a, 1
ld (DO_REPAINT), a
; hacemos otras cosas, como lógica del juego o demás.
; Cuando llegue la siguiente interrupción, se copiará
; el buffer a la pantalla automáticamente
[...]
; si hemos terminado de actualizar la lógica del juego y
; queremos pintar el siguiente frame, tenemos que esperar
; a que la rutina de interrupción nos notifique que ha acabado.
; Si no lo hacemos, podríamos estar sobreescribiendo el frame
; anterior.
WAIT_PAINTED:
ld A, (REPAINT)
and A
jr nz, WAIT_PAINTED
; ahora ya estamos seguros de que el frame ha sido copiado a
; la pantalla, así que podemos empezar a pintar el siguiente
; en el buffer intermedio
[...]
Así, vemos que en la rutina de interrupciones guardamos en la pila el contenido del registro AF, y luego leemos el valor que hay en la posición de memoria DO_REPAINT. Si es cero, significa que el buffer intermedio aún está a medio pintar y aún no debemos hacer nada, por lo que simplemente saltamos al final de la función, donde restauramos el valor de AF y retornamos.
En cambio, si DO_REPAINT es diferente de cero significa que el buffer intermedio está listo para ser transferido a la pantalla, así que guardamos en la pila el resto de registros que vamos a utilizar (sin olvidarnos de los registros alternativos), copiamos los datos del buffer a la pantalla, restauramos los registros, y retornamos.
Esto es muy útil pues nos permite aprovechar un tiempo que, antes, sencillamente perdíamos. Así, cuando ejecutábamos HALT para esperar al retrazado vertical y empezar a volcar el buffer intermedio a la pantalla, el procesador se quedaba literalmente congelado esperando a que se produjese una interrupción. Ahora, en cambio, podemos empezar a procesar otros datos en cuanto hemos terminado de pintar el frame, y el propio procesador saltará a la rutina de volcado automáticamente en el momento preciso, lo que nos permitirá exprimir al máximo el procesador.
Es fundamental guardar el valor de los registros, pues no hay que olvidar que la rutina de interrupciones se puede llamar en cualquier momento de la ejecución del código principal, y que lo único que se guarda es la dirección de retorno; es nuestra responsabilidad guardar absolutamente el resto de cosas.
Una tabla llena de 255
En mucha literatura sobre el uso de interrupciones en el Spectrum se recomienda crear una tabla de 257 elementos, todos ellos con el mismo valor, y utilizarla como tabla de vectores de interrupción. Es más: recomiendan aprovechar para ello un bloque de algo más de 1 Kbyte de la ROM que está todo él a 255, y así no desperdiciar memoria RAM. El motivo, explican, es que el bus no siempre tiene el valor 255, por lo que si cuando se produce una interrupción el valor no es el esperado, podríamos saltar a vete-tu-a-saber-donde y que se nos cuelgue el ordenador. Esto, como veremos luego, no es cierto (o, al menos, no es cierto en condiciones normales), por lo que no es necesario hacerlo. Pero, de todas formas, voy a describir el proceso porque nunca está de más entenderlo, en caso de que queramos, por ejemplo, desensamblar un programa que lo utilice, entender de qué va.
Veamos con detalle la idea: primero creamos una tabla de 257 bytes, todos ellos con el valor 255, y que empiece en una dirección de memoria cuyo byte bajo sea cero (por ejemplo 0xFE00 hasta 0xFF00 ambos incluídos), o bien aprovechamos que en la ROM del Spectrum 48K, a partir de la dirección 0x386D hay 1179 bytes sin usar, todos ellos a 255, tomando como tabla el bloque que va desde 0x3900 hasta 0x3A00. A continuación, cargamos en el registro I el valor necesario para utilizar ese bloque como tabla de interrupciones (0xFE en el primer caso, 0x3A en el segundo). Esto hará que cuando se produzca una interrupción no importe qué valor hay en el bus: siempre resultará en que comenzará a ejecutar a partir de la dirección 0xFFFF (o sea, el último byte de memoria). Aparentemente esto nos deja muy limitados, pues sólo podríamos ejecutar un único byte antes de dar la vuelta al contador de programa. Pero dado que el primer byte de la ROM del Spectrum es 0xF3 (instrucción DI), si ponemos el valor 0x18 en la dirección 0xFFFF lo que tendremos es que se ejecutará la instrucción JR -13. Por tanto, esa instrucción saltará a la dirección 65524 (no hay que olvidar que después de leer los dos bytes del JR -13, el contador de programa estará apuntando a la dirección 1). Es en esa dirección donde podemos poner una instrucción JP que salte a donde quiera que esté nuestra rutina real.
Alambicado, sí, pero nos da una gran seguridad a la hora de trabajar con interrupciones… ¿o no?
Para empezar, está la cuestión de que ese bloque de más de 1 kbyte a 255 sólo está disponible en el Spectrum 48K. En el modelo de 128K y posteriores ese bloque tiene una serie de rutinas extra, por lo que no está disponible. Esto significa que si utilizamos esto, sólo funcionará en equipos de 48K, pero no en modelos de 128K, ni siquiera aunque cambiemos a modo 48K.
Pero la verdadera cuestión es que, en condiciones normales, el bus de datos del Spectrum siempre estará a 255. Obviamente si nos dedicamos a leer el bus directamente, como ya comenté en entradas anteriores, veremos que a veces muestra otros valores porque estamos viendo el dato que la ULA está leyendo en ese momento para generar la pantalla. Pero la cuestión es que el único valor que nos interesa es el que encontraremos cuando se produzca una interrupción, y dado que éstas se generan cuando la ULA va a comenzar a pintar la parte superior del borde, en ese momento no leerá nada de la RAM, por lo que siempre, siempre, se leerá un 255.
Existe, sin embargo, un caso en el que esto puede no cumplirse, y es si tenemos un periférico conectado a un ordenador real, y este periférico, por diseño, fuerza un valor diferente en el bus. Un ejemplo es el infame sistema de protección SD1 de Dinamic, utilizado en el Camelot Warriors. Se trata de un pequeño conector que incluye una resistencia de 1000 ohmios entre el bit D5 del bus de datos y masa, lo que hace que cuando se lee el bus, si ningún periférico fuerza un valor, se leerá 223 en lugar de 255. Según el artículo, esto también ocurría al leer del puerto 254, el de la ULA, lo que me hace sospechar que, para ahorrar celdas, la ULA sólo fuerza los bits 0-4 (teclado) y 6 (cassete), pero no hace nada con los bits 5 y 7.
Así que, por esto, realmente considero que no es necesario utilizar una tabla. Pero si te empeñas, cuidado en los modelos Plus 2A y Plus 3, pues dos de sus cuatro ROMs no empiezan con 0xF3, por lo que lo mejor es asegurarse de paginar la correcta antes. Eso sí, ya puestos, puede ser una mejor solución hacer una tabla de 256 elementos situada a partir 0xFF00 y con el valor 0xF3, lo que hará que la interrupción salte a la dirección 0xF3F3 (62451). Esto permite compactar algo más el código de las interrupciones.
En esta entrada vamos a ver el último punto que nos falta: cómo sincronizarnos con el barrido de la pantalla. Ya comenté en la primera entrada que esto es algo fundamental para asegurarnos de que copiamos todos los datos desde nuestro buffer hasta la memoria de vídeo sin que se produzcan efectos indeseados como parpadeos o tearing.
El primer detalle importante que tenemos que saber es que en el Spectrum, cada vez que se comienza a generar una imagen, la ULA genera una interrupción enmascarable. Por defecto, la ROM pone las interrupciones en Modo 1, lo que hace que el procesador salte a la dirección 0x38 cada vez que se genera una interrupción enmascarable. En esta dirección de la ROM está la rutina que lee el teclado y hace otras operaciones básicas, como incrementar el contador de frames. Por lo tanto, la manera más sencilla de sincronizarnos con el haz es ejecutar una instrucción HALT, que espera a que se produzca una interrupción antes de proseguir la ejecución de instrucciones (¡¡Pero no hay que olvidarse de habilitar antes las interrupciones, o el sistema se quedará colgado!!!). Sin embargo, en este momento el haz estará todavía en la parte superior del BORDER, por lo que tenemos que esperar aún a que llegue a la zona del PAPER.
La primera idea, la más naive, es hacer un bucle de retardo que espere el tiempo exacto que necesita el haz para llegar a la zona del PAPER. Teniendo en cuenta que la parte superior del borde son 64 líneas y que cada una dura 224 Testados, sólo tenemos que esperar 14 336 Testados desde el instante posterior al HALT.
Sin embargo, en la práctica esto no es una buena idea por dos motivos: para empezar, en los modelos de 128Kbytes cada línea dura 228 Testados, por lo que tendríamos que detectar si estamos en un equipo de 48 o de 128Kbytes y, según el resultado, esperar 14 336 o 14 592 Testados. Esperar siempre el tiempo máximo tampoco es bueno, porque entonces en los modelos de 48Kbytes desperdiciamos 256 Testados, que son dos scanlines completas.
Por otro lado, no hay que olvidar que la instrucción HALT continuará la ejecución después de que se haya ejecutado la rutina de interrupción, la cual tardará un tiempo desconocido. Eso significa que estaremos perdiendo una vez más un valioso tiempo que necesitamos utilizar para pintar, no para desperdiciar.
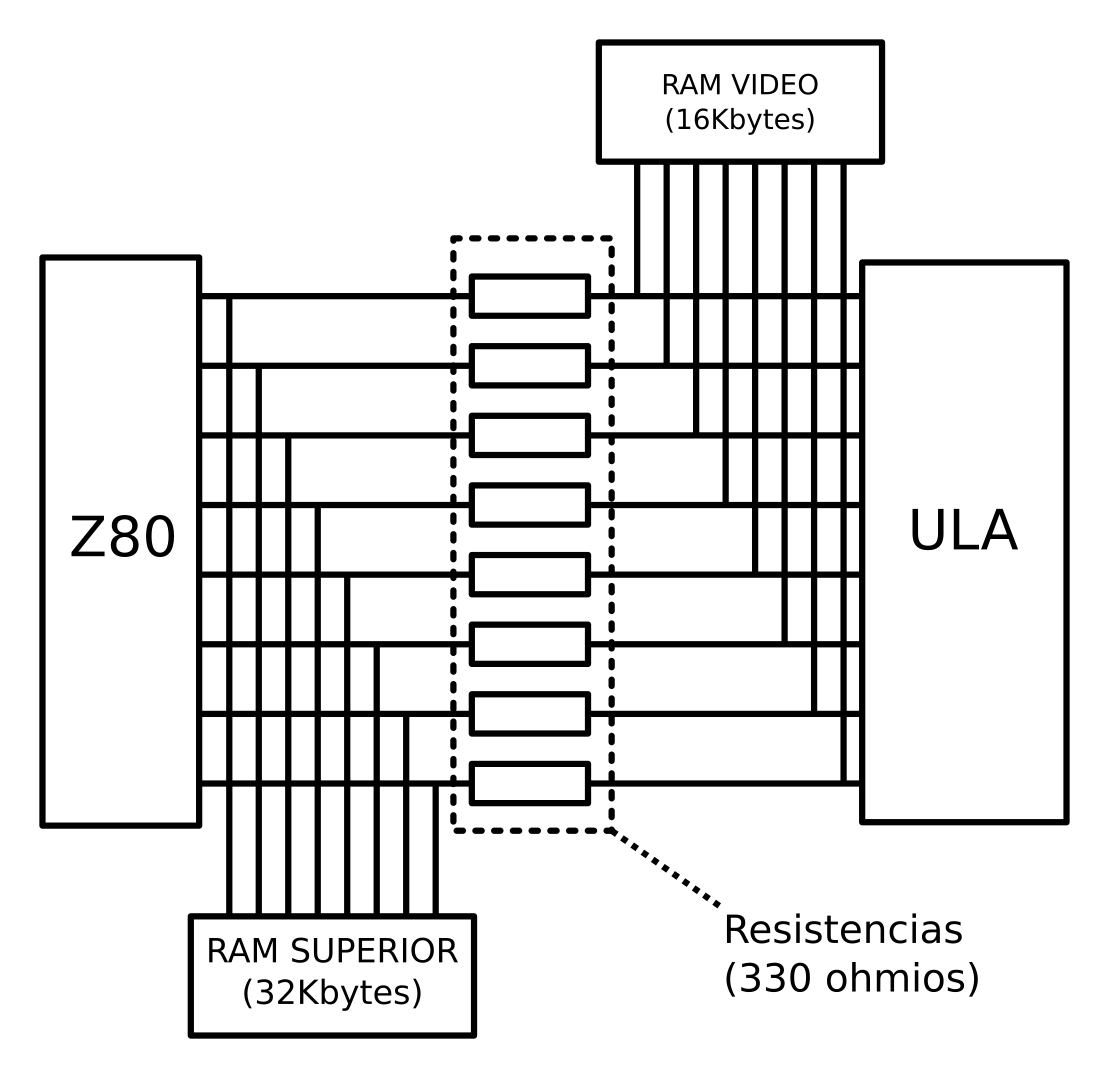
Es por esto necesitamos algún método para saber con precisión cuando el barrido ha llegado al PAPER realmente. Afortunadamente, esta vez el que el Spectrum se diseñase para ser lo más barato posible nos ofrece la solución. Echemos un vistazo a cómo está conectada la CPU y la ULA a la memoria:
La imagen muestra únicamente la conexión del bus de datos, pues es la parte que nos interesa. Si nos fijamos, vemos que el bus de datos de la ULA está conectado directamente a la RAM de vídeo. Por su parte, el bus de datos del Z80 está conectado directamente sólo a la RAM superior (bueno, y a la ROM y al bus trasero, pero no me apetecía pintarlo todo). Esto significa que la ULA tiene prioridad absoluta a la hora de trabajar con la RAM de vídeo, mientras que el Z80 la tiene al trabajar con la RAM superior, la ROM y todo aquello que esté conectado al bus externo. Pero, y esta es la clave, el bus de datos del Z80 está conectado al bus de datos de la RAM de vídeo (y de la ULA) a través de un conjunto de resistencias de 330 ohmios. Estas resistencias permiten aislar ambos buses cuando la ULA accede a la memoria RAM a la vez que el Z80 accede a la ROM, a la RAM superior o a un periférico externo. En efecto, las resistencias absorben la diferencia de potencial cuando en un lado del bus hay un 1 (5 voltios) y en el otro hay un 0 (0 voltios), de manera que cada lado del bus puede tener un dato diferente sin riesgo de cortocircuitos. Sin embargo, a la vez, permiten que el Z80 lea los datos de la RAM de vídeo cuando la ULA no está accediendo a ella, pues si no hay ningún periférico que imponga un valor en el bus de datos del Z80, la corriente atravesará las resistencias y el valor que haya en el bus de datos de la ULA/RAM de vídeo será visible en el bus de datos del Z80. Y ésta es precisamente la clave: si leemos del bus de datos sin activar ningún periférico, podremos ver qué está leyendo la ULA en ese momento. La cuestión es que la ULA sólo lee de la RAM de vídeo cuando está pintando el PAPER, pues cuando pinta el BORDER utiliza un valor almacenado internamente, con lo cual, la clave para saber cuando la ULA ha empezado a pintar el PAPER es leer repetidamente el bus sin acceder a ningún dispositivo: si la ULA no está leyendo la RAM de vídeo, el bus no estará conectado a nada, con lo que leeremos 255 (por la tecnología utilizada en el Z80, cuando una entrada está al aire, se lee un 1 lógico, por lo que si las ocho líneas del bus de datos están sin conectar a nada, estarán todas a 1 y leeremos 255), mientras que si la ULA está leyendo, leeremos el dato de la RAM de vídeo correspondiente: bien el byte de píxeles que se va a pintar, bien el byte de atributos de color correspondiente. Obviamente, si cometemos la torpeza de llenar las primeras líneas de la memoria de vídeo con el valor 255 (sí, yo lo hice 😀 ) retrasaremos la detección, por lo que es recomendable evitar ese valor al menos en la primera fila (aunque como veremos luego, tampoco es tan desastroso si lo ponemos sólo en los píxeles, pero no en los atributos).
Ahora llega la siguiente cuestión: ¿cómo podemos leer el bus sin que ningún dispositivo intente meter un dato? No podemos hacerlo leyendo de la RAM, salvo que estemos en un Spectrum 16K, pues si leemos en los primeros 16Kbytes nos responderá la ROM, si leemos en los siguientes 16Kbytes nos responderá la RAM de vídeo (y, además, sólo cuando la ULA no esté leyendo nada), y si leemos los 32Kbytes últimos nos responderá la RAM superior. Ante esto, la única solución es leer de un puerto de entrada/salida (E/S) en el que sepamos que no hay ningún periférico.
Por convenio, en el Spectrum se utilizan los ocho bits inferiores del bus de direcciones para direccionar periféricos, y para simplificar la circuitería se le asigna un único bit a cada uno, que debe ponerse a cero para seleccionar el dispositivo. Así, el bit A0 selecciona la ULA como periférico, el bit A1 la impresora ZX, el bit A2 se reservó por Sinclair en los modelos de 48Kbytes, y se utiliza para la paginación y el chip de sonido en los modelos de 128Kbytes; los bits A3 y A4 son para la interfaz 1, y los bits 5, 6 y 7 están disponibles para otros periféricos (por ejemplo, el bit 5 direcciona la interfaz Kempston para joysticks). Por supuesto, no debemos poner más de uno de estos bits a cero, o correremos el riesgo de provocar un cortocircuito y que el ordenador se resetee.
Sabiendo esto, es fácil deducir que hay que evitar poner cualquiera de esos bits a cero para que, de esa manera, ningún periférico intente darnos sus datos y así que no fuercen un valor del bus; por tanto, tenemos que leer del puerto 255 (todos los bits del bus de direcciones a 1… o al menos los ocho bits inferiores). Como no hay ningún periférico que responda a esa dirección, se leerá el valor del bus al aire, y eso incluirá lo que sea que la ULA esté leyendo de la RAM de vídeo (si está leyendo en ese momento, claro).
Así, en principio bastaría con esperar por una interrupción para saber que estamos en la parte superior de la pantalla, y entonces entrar en un bucle que lea repetidamente de dicho puerto 255 hasta que el valor leído sea diferente de 255, momento en el que sabremos que la ULA ha empezado a pintar el PAPER y, por tanto, podemos empezar a copiar los datos del buffer a la memoria de vídeo. Una posible rutina sería esta:
ld B, 255
halt
loop:
in A, (255)
cp B
jp NZ, loop
Por desgracia, ahora vienen los detalles escabrosos, y es que, para empezar, la rutina anterior sólo hace una lectura cada 25 Testados, lo que significa que si tenemos la mala suerte de que haga una lectura justo antes de que empiece a leer datos, tendremos que esperar al menos 25 ciclos de reloj antes de poder volver a leer el bus. Pero esto no es todo, pues, además, la ULA no está leyendo constantemente de la RAM. Si recordamos lo que vimos en la entrada 4, la ULA aprovechaba una característica de las RAMs dinámicas para leer dos posiciones de memoria (píxeles y atributos de color) en tres ciclos de reloj en lugar de los cuatro necesarios normalmente, y además agrupaba dos grupos de lecturas juntas de manera que en seis ciclos seguidos leía los datos (píxeles y atributos de color) de dos caracteres consecutivos, dejando así libres dos ciclos de reloj consecutivos para que el procesador pueda acceder a la RAM de vídeo mientras la ULA está pintando el PAPER. La cuestión es que de esos tres ciclos, sólo los dos últimos tendrán un dato de la RAM, mientras que el primero no tendrá nada (y, por tanto, dejará el bus a 255). En otras palabras: de cada ocho Testados, sólo el segundo, tercero, quinto y sexto pondrán un valor diferente a 255 en el bus. En el primero y en el cuarto la ULA estará enviando la parte inferior de la dirección de memoria a leer, y el séptimo y el octavo son los dos ciclos en los que el Z80 podría acceder al RAM de vídeo para leer o escribir cuando la ULA no está pintando el borde. Esto significa que, por si fuera poco, la ULA podría estar ya pintando el PAPER pero nosotros no detectarlo a la primera porque hemos tenido la mala suerte de que la instrucción IN se ejecutó justo en alguno de esos cuatro ciclos de reloj en los que la memoria RAM de vídeo no está enviando datos. Pero aún peor: si el periodo entre lecturas es múltiplo de 4, habrá algunos casos en los que jamás podremos detectar si la ULA está pintando el PAPER: en efecto, supongamos que tenemos un bucle que lee cada 28 ciclos (que es un múltiplo entero de 4); si tenemos la mala suerte de que la instrucción IN se ejecute justo en el cuarto ciclo de un proceso de lectura de la ULA, el procesador leerá 255 pues en ese momento la ULA está enviando la parte baja de la dirección de memoria a leer, no está leyendo aún; pero 28 ciclos después estará en el octavo ciclo del grupo de ocho, que está libre para el Z80 y no hay acceso por parte de la ULA; 28 ciclos después volverá a estar en el ciclo 4… y así ad finitum. Por tanto, es necesario que el periodo del bucle de lectura y el periodo de acceso de la ULA sean primos relativos.
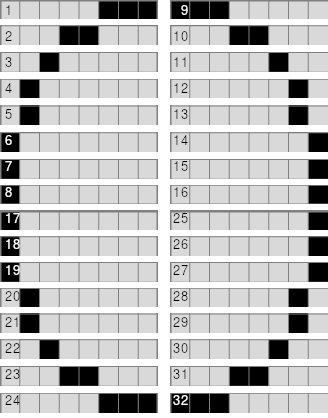
Sin embargo, incluso unos primos son mejores que otros; y es que por las características de las operaciones modulares, puede ocurrir que un valor más pequeño sea peor que uno mayor. Por tanto ¿qué periodo de lectura será el óptimo, teniendo en cuenta que no podemos hacer que dure menos de 25 Testados? ¿Será 25 el valor óptimo, o un valor mayor puede ser mejor? Por desgracia, si tenemos en cuenta que, a priori, no sabemos si vamos a necesitar más de una línea para detectar si la ULA está leyendo, y que la ULA sólo lee durante 128 Testados que dura el PAPER, y el resto hasta los 224 Testados que dura cada línea no lee nada, la cosa se complica, así que decidí hacer un programita que me calcule cuantos Testados como máximo puedo tardar en detectar una lectura de la ULA (y ya de paso, cuantos en promedio) con cualquier periodo de lectura, y este es el resultado:
Tal y como sospechaba, vemos que utilizar un periodo de 25 Testados es mucho peor que uno de 26 (ambos marcados con un asterisco a la izquierda), pues con esta última perderemos un máximo de 73 Testados en detectar una lectura de la ULA, y un promedio de 27,5 Testados, mientras que con un periodo de 25 Testados podemos llegar a tardar hasta 96 Testados y un promedio de 33 Testados. Por tanto, tenemos que sustituir IN A, (255), que consume 11 Testados, por IN A, (C), que consume 12 Testados, e inicializar BC fuera del bucle a 0xFFFF:
ld BC, 0xFFFF
halt
loop:
in A, (C)
cp B
jp NZ, loop
Así pues, colocando este pequeño bucle justo antes de la rutina de copia que vimos en las tres primeras entradas, la sincronizaremos perfectamente con el haz y empezaremos a copiar como mucho 73 Testados más tarde de que la ULA haya empezado a pintar. Pero lo mejor es que podemos, si queremos, aprovechar parte de los 14 336 Testados que hay entre la interrupción y ese momento para realizar otras tareas, como por ejemplo reproducir música simultáneamente, y todo ello sin tener que preocuparnos de calcular con precisión cuanto vamos a tardar (siempre y cuando estemos seguros de tardar menos de 14 336 Testados, claro), pues el bucle anterior nos sincronizará.
¿Y qué ocurre si cometemos el error de poner los bytes de píxeles a 255, y sólo los de los atributos son diferentes de 255? En ese caso, con un bucle que dure 26 Testados tardaremos un máximo de 99 Testados en detectar el PAPER y un promedio de 49,5 Testados. Tampoco es exactamente una catástrofe.
El Inves Spectrum Plus y el Plus 2A/Plus 3
Por último, añadir un par de comentarios extra; el primero sobre un ordenador muy especial: el Inves Spectrum Plus. Este equipo se lanzó al mercado en 1986 y no era de Sinclair, sino de la empresa española Investrónica. Se trata de un modelo que intenta ser compatible con el ZX Spectrum original, pero que por desgracia tiene algunas diferencias que hacen que no lo sea del todo.
La primera gran diferencia es que no tiene contienda de memoria. El sistema que utiliza para conseguirlo es realmente ingenioso, y lo explican muy bien Miguel Ángel Rodríguez Jódar y César Hernández Bañó en un artículo que escribieron donde analizan el hardware del Inves Spectrum Plus en profundidad. La ventaja de esto es que este ordenador es más rápido que el Spectrum original a pesar de trabajar a la misma velocidad de reloj. Por desgracia, la implementación de este sistema hace que el Z80 nunca pueda ver los accesos a memoria de la ULA, sino que el bus de datos siempre valdrá 255 cuando ningún periférico ponga un dato en el. Eso significa que el bucle anterior sencillamente se colgará.
Afortunadamente hay un segundo cambio que viene en nuestra ayuda, y es que la interrupción ya no se genera al comenzar un cuadro, sino justo cuando se va a comenzar a pintar el PAPER. Esto significa que, en un Inves, hay que eliminar completamente el bucle y empezar a copiar el buffer justo después del HALT.
En el caso del Plus 3 (y del Plus 2A, con quien comparte placa), la situación es peor, pues se ha eliminado completamente el efecto del bus flotante. Afortunadamente hay una manera sencilla de resolver el problema, tal y como se explica en este artículo que restaura el bus flotante en el Plus 3. Es importante recalcar que sólo lo restaura en el bit 7. Dado que este bit, en el byte de atributos de color, activa el FLASH, en general estará a cero, lo que garantiza que al menos se puede detectar una de las dos lecturas en caso de que todos los bytes de píxeles tengan el bit 7 a uno. De hecho es muy posible que este truco se pueda implementar en el Inves Spectrum también.
Un ejemplo
Después de la teoría, ha llegado la hora de juntarlo todo y hacer una microdemo. Y aquí está:
Partí de unos gráficos inspirados en Among Us para hacer un pequeño personajillo, y añadí una baldosa. Como vemos, no sólo se pintan los píxeles sino también los atributos de color, y todo ello de manera perfectamente sincronizada con el haz para conseguir un movimiento sin tearing. La velocidad que alcanza es algo más de ocho FPS haciendo un scroll de pantalla-cuasi-completa con color, lo que no está nada mal.
Para comparar, vamos a quitar la sincronización con el haz de electrones:
Vemos que en varios puntos se producen efectos de tearing que deslucen mucho el resultado.
En el primer vídeo vemos que sólo pinto 20 líneas en lugar de 22. El motivo es que, a pesar de todo, la última fila de atributos de color de esas 22, no siempre da tiempo a pintarla correctamente, así que ya puestos, opté por redondear a un múltiplo del tamaño de la baldosa (que es de 4×4 caracteres), de manera que quede una zona para el inventario de objetos recogidos por el usuario. Sí, porque… ¡¡¡voy a intentar convertir todo esto en un juego!!!
En la entrada anterior expliqué cómo crear un sprite, y puse una demostración que muestra cómo funciona, moviendo un sprite de un círculo en vertical. Y aunque en apariencia funciona bien cuando el fondo está vacío, si ponemos alguna imagen de fondo (en este ejemplo pongo «basura» copiada desde la zona de la ROM) y movemos el sprite por encima, vemos que hay un problema: aunque el sprite es un círculo, los límites del cuadrado que delimitan los caracteres son visibles.
Lo lógico sería que en las zonas externas del círculo pudiésemos ver el fondo, y que éste sólo estuviese tapado en donde está el círculo en sí.
Pues bien: este efecto es relativamente sencillo de conseguir, y para eso sólo necesitamos utilizar máscaras. Se trata de dividir el sprite en dos imágenes independientes: una contiene el sprite en sí, tal y como hasta ahora, y la otra es una máscara de transparencia, donde un bit puesto a 1 indica que ese pixel del sprite es transparente y se debe ver el fondo, y un bit a 0 especifica que el pixel correspondiente del sprite es opaco y debe pintarse.
En esta imagen vemos el sprite, la máscara, y cómo queda la transparencia al final:
Como vemos, en la máscara, la zona alrededor del círculo es de color negro (bit a 1), lo que significa que es transparente, mientras que la zona interna es blanca (bit a 0), lo que significa que es opaca. A la derecha podemos ver las zonas transparentes con un damero de ajedrez. Vemos que hemos dejado un margen de un píxel alrededor del círculo para que se vea mejor.
Todo esto está muy bien, pero ¿cómo hacemos para pintarlo? La clave está en utilizar operaciones lógicas: antes de copiar un byte del sprite en el buffer de la pantalla, tenemos que leer el byte que ya hay y hacer un AND lógico con la máscara. De esta manera, los bits del fondo que coincidan con un bit a 1 de la máscara se quedarán tal y como están, mientras que los bits que coincidan con un 0 en la máscara se pondrán a 0, «dejando un hueco» en donde podremos pintar luego el sprite. Por supuesto, para ello no podemos tampoco copiar directamente el byte del sprite, sino que tenemos que hacer un OR lógico de lo que haya en pantalla y el sprite, de manera que se mezclen.
Veámoslo de manera gráfica: supongamos que tenemos como fondo un damero de ajedrez, y queremos pintar encima nuestro sprite círculo. Primero aplicamos la máscara usando el operador AND entre cada byte de ella y el que hay en pantalla en la posición correspondiente, y almacenamos el resultado de nuevo en pantalla. Esto borrará sólo las partes que la máscara indica que son opacas, dejando intactas aquellas zonas marcadas como transparentes.
Hecho esto, copiamos los bytes del sprite en la misma zona pero utilizando esta vez la operación OR, de manera que «se mezcle» con lo que había. Dado que previamente habíamos «hecho un agujero» con la máscara, los píxeles del sprite se mezclarán exclusivamente donde nos interesa, dejando inalterados el resto de zonas.
Sin embargo, a la hora de implementarlo nos encontramos con el problema de que es un proceso muy ineficiente, pues tenemos que, literalmente, imprimir dos sprites realmente: primero la máscara, y luego los píxeles. Y por si fuera poco tenemos que hacer tres operaciones en memoria por cada sprite en lugar de dos, como hasta ahora: leer el dato de la pantalla, leer el byte del sprite (ya sea pixels o máscara), y escribir el nuevo valor.
La solución consiste en aplicar ambas operaciones a la vez. Para ello empezamos leyendo el primer byte de la zona de pantalla, hacemos AND con el primer byte de la máscara, luego OR con el primer byte de los píxeles, y finalmente escribimos el valor resultante en la memoria de pantalla. Hecho esto, incrementamos en uno los punteros de los píxeles y de la máscara, pasamos a la siguiente dirección de pantalla, y repetimos el proceso.
Este sistema permite aumentar mucho el rendimiento, pues no sólo reducimos los accesos a memoria a sólo dos tercios, sino que, además, se pueden compartir muchas operaciones comunes, como la inicialización de los bucles (e incluso la sobrecarga que supone ejecutar el bucle en sí). Sin embargo, todavía podemos optimizarlo un poquito más. Para entenderlo, pensemos en cómo almacenamos los píxeles y la máscara del sprite: la opción más inmediata es colocar la máscara justo a continuación de los píxeles, de manera que si conocemos la dirección inicial y el tamaño del sprite en caracteres, podemos obtener la dirección de la máscara simplemente con la operación MASCARA = PÍXELES + ANCHO * ALTO * 8. El resultado sería como tener un sprite del doble de tamaño, y almacenado así:
Es sencillo de describir, pero recordemos que el Z80 no tiene instrucción de multiplicación, lo que supone que hacer ese cálculo sea lento y ocupe bastante código. Además, nos obliga a tener tres punteros: uno para los píxeles, otro para la máscara, y otro para el buffer de pantalla.
Sin embargo, existe una manera de evitar todo esto, y es entrelazar los datos de la máscara y de los píxeles; esto es, almacenar en memoria un byte de máscara, un byte de píxeles, un byte de máscara, un byte de píxeles… así:
La ventaja de este sistema es que sólo necesitamos dos punteros: uno que apunte al sprite, y otro al buffer de pantalla. La mecánica es sencilla: leemos byte del puntero del buffer de pantalla y hacemos un AND con el byte del puntero del sprite. Incrementamos en uno el puntero del sprite y hacemos un OR del byte al que apunta con el resultado anterior. Hecho esto, incrementamos de nuevo el puntero del sprite y pasamos a la siguiente dirección de memoria del buffer de pantalla (según estemos todavía en el mismo scanline o tengamos que pasar al siguiente). Lo curioso es que pocos juegos utilizan este sistema, a pesar de sus claras ventajas. Un ejemplo de juego que lo usa es Knight Lore, uno de los primeros juegos en utilizar máscaras en sus sprites.
El código para hacer esto sería el siguiente:
pintar_sprite:
push HL
exx
pop HL ; metemos la dirección del sprite en HL'
exx
set 7, D ; DE ya casi tiene la dirección, le falta el bit 7 de D
ex de, hl ; metemos la dirección de la pantalla en HL
sla B
sla B ; rotamos tres veces B, que es igual que multiplicar por 8
sla B ; así tenemos en B la altura en scanlines
ld A, 32
sub C ; calculamos cuanto tenemos que sumar para pasar al
ld E, A ; siguiente scanline, y lo almacenamos en DE
ld D, 0
bucle:
push BC ; guardamos B (pues es el contador de scanlines) y C
ld B, C ; preparamos el bucle interno
bucle2:
ld a, (hl) ; leemos el byte actual de la pantalla
exx
and (hl) ; aplicamos la máscara
inc hl
or (hl) ; aplicamos los píxeles
inc hl
exx
ld (hl), a ; almacenamos el resultado en la pantalla
inc hl ; y pasamos a la siguiente posición de la pantalla
djnz bucle2 ; terminamos el scanline
add HL, DE ; y pasamos al siguiente scanline
pop BC ; recuperamos el número de scanlines que nos quedan
djnz bucle ; y repetimos hasta hacer todos los scanlines
call paint_screen ; llamamos a la función que vuelca el buffer
; en la pantalla (si hemos pintado todos los
; sprites)
y reemplazaría al código que escribimos en la entrada anterior. Existe un cambio extra a mayores: dado que ahora cada scanline ocupa el doble (pues contiene píxeles y máscara), en la parte donde comprobamos si el sprite está fuera de la pantalla por arriba tenemos que multiplicar por 16 en lugar de por 8, lo que se consigue añadiendo un add A, A extra.
Y este es el resultado: como se ve, es muchísimo mejor que el original, pues ya no hay ese cuadrado tan feo alrededor del sprite que hace que parezca pegado encima, sino que éste realmente aparece integrado con el fondo.
Como cabe suponer, mi editor de sprites ZXSpriter almacena los sprites precisamente en este formato. Pero no sólo eso, sino que si se incluyen atributos de color, puede también incluirlos entrelazados (aunque en este caso, es opcional). De esta manera, el sprite tendrá ocho scanlines con los bytes de máscara y píxeles entrelazados, tal y como hemos visto ya, y justo a continuación los bytes con los atributos de color para ese conjunto de scanlines; a continuación otros ocho scanlines, y otra vez los atributos de color para ese conjunto de scanlines. Y así sucesivamente. Esto permite pintar sprites de colores de manera óptima.
El código del ejemplo con máscaras está disponible aquí: ejemplo de sprites con máscaras. En él vuelvo a hacer uso de los registros alternativos (BC’, DE’ y HL’), y del hecho de que el registro A no se intercambia con A’ cuando se ejecuta la instrucción EXX, para tener en HL la dirección de la pantalla y en HL’ la del sprite.
Editado: el código completo del ejemplo de esta entrada está disponible en un enlace al final.
Llega la hora de pintar cosas en pantalla. La idea consiste en modificar los valores de la memoria RAM de vídeo para que, cuando la ULA (que es el chip encargado de generar la imagen) lea esos bytes, éstos muestren la imagen que queremos. Hay dos maneras de hacerlo: vectorial, y por sprites. En el caso de gráficos vectoriales, se tiene almacenada en memoria una lista de segmentos y vértices que deben pintarse sobre la pantalla para generar la imagen. Son ideales para gráficos 3D, y son los utilizados en juegos como Elite o Driller, sin embargo, en una máquina de 8 bits son muy limitados, por lo que de momento lo dejaremos de lado. Es verdad que hace tiempo estuve trabajando en una rutina para pintar triángulos vectoriales a alta velocidad en Spectrum, por lo que puede que retome el tema algún día.
Los sprites, por su parte, son mucho más sencillos, pues consisten en tener los bytes necesarios para pintar algo en pantalla ya preparados en otra zona de memoria, y lo único que necesitaremos será copiarlos en la dirección adecuada de pantalla. Además, cambiando la dirección de memoria en la que empezamos a pintar podremos cambiar la posición, con lo que podemos colocarlos en cualquier punto de la pantalla o, incluso, moverlos y animarlos.
Para pintarlo en pantalla, primero necesitamos encontrar la dirección de memoria en la que irá el primer byte, que, como recordaremos de la entrada anterior, se podía hacer de manera sencilla:
Obtención de la dirección en pantalla a partir de las coordenadas de un carácter trabajando con el buffer lineal. En verde va la coordenada Y, y en azul la coordenada X. En magenta va el número de scanline dentro del carácter.
Así, si recordamos, la pantalla del Spectrum está dividida en una matriz de 32×24 caracteres, con ocho scanlines cada uno, y si utilizamos la rutina de copia de buffer que vimos en las tres primeras entradas, obtener la dirección de un carácter a partir de sus coordenadas X e Y es tan sencillo como multiplicar la Y por 256, sumarle la X, y ese valor sumarlo a la dirección inicial del buffer. Alguno dirá que las multiplicaciones en ensamblador son muy costosas, pero es aquí donde viene lo divertido: digamos que queremos tener en el par de registros HL la dirección inicial del carácter situado en las coordenadas X, Y. Pues sólo tenemos que copiar el valor de Y en el registro H, el de X en el registro L, y sumarle a HL la dirección base del buffer. Pero si hemos sido cuidadosos y hemos puesto el buffer en la dirección 0x8000, ni siquiera necesitaremos una suma, sino simplemente poner a 1 el último bit del registro H.
Por supuesto, esto nos da la dirección del primer scanline del carácter, pero movernos al siguiente scanline es tan sencillo como sumar 32 a la dirección. Esto nos permite pintar sprites del tamaño de un carácter en pantalla, pero ¿como hacemos para pintar sprites de mayor tamaño?
La solución más inmediata consiste en dividir el sprite en bloques de 8×8 píxeles, almacenar cada bloque por separado, y luego pintarlos uno a uno en las posiciones correspondientes. Así, si tuviésemos por ejemplo el siguiente sprite de 16×16 píxeles:
Lo que haríamos sería dividirlo en bloques de 8×8 píxeles, de manera que cada uno se podría pintar como un carácter en pantalla, y almacenaríamos los bytes en este orden en memoria:
Vemos que primero viene el primer byte del carácter superior izquierdo, luego el inmediatamente inferior, y así hasta hacer ocho bytes del primer carácter. A continuación vendrían los ocho bytes del carácter de la parte superior derecha, luego los de la parte inferior izquierda, y por último los de la parte inferior derecha.
Digamos que queremos pintarlo en las coordenadas X=5 e Y=12. Lo primero sería calcular la dirección de 5,12, la cual vamos a almacenarla en el par de registros DE (para tener la regla mnemotéctica de DE = DEstino), y eso lo haremos escribiendo 12 en D y 5 en E, y sumándole 128 a D para activar el bit 7 y que apunte al inicio de nuestro buffer. Ahora ya tenemos la dirección de memoria donde tenemos que empezar a copiar los datos. Digamos, además, que en HL tenemos la dirección de memoria del primer byte de nuestro sprite. Bien, ahora sólo tenemos que leer el byte de la dirección de memoria apuntada por HL, y escribirlo en la dirección de memoria apuntada por DE. El siguiente paso es saltar al siguiente byte, y para ello sólo tenemos que incrementar HL en 1, y sumar 32 a DE para pasar al siguiente scanline, con lo que ya podemos copiar el segundo byte. Este proceso lo repetimos ocho veces para copiar los ocho bytes del carácter.
Ahora que ya tenemos el primer carácter copiado, pasamos al siguiente. Para ello tenemos que calcular la dirección de las coordenadas 6,12 y meter el resultado en DE. HL no debemos tocarlo pues ya está apuntando al segundo carácter. Una vez hecho esto, copiamos los bytes igual que hicimos arriba y volvemos a repetirlo para las coordenadas 5, 13 y 6, 13.
El método es directo, pero tiene el problema de que no es demasiado eficiente: tenemos que mantener en algún lado las coordenadas del carácter actual, así como el ancho y el alto para saber cuando hemos terminado, y recalcular la dirección de memoria de cada carácter. Todo esto consume mucho tiempo de proceso, y por eso pocos juegos lo usan (uno que sí lo hace, por ejemplo, es The trapdoor). Es por esto que, normalmente, se prefiere almacenar los sprites en formato scanline. La diferencia está en que, en lugar de almacenarlo carácter a carácter, se almacena por filas completas. Así, el orden para scanline en el ejemplo anterior sería el siguiente:
En este caso, la manera de trabajar es ligeramente diferente: partimos una vez más de las coordenadas X e Y en las que queremos pintar nuestro sprite, y procedemos a calcular la dirección de memoria de dichas coordenadas. Ahora sólo necesitamos hacer dos bucles, uno que cuente de cero a ANCHO-1, que será el interno, y otro que cuente de 0 a (ALTO*8)-1. En el bucle interno leeremos un byte del sprite y lo copiaremos en la dirección de pantalla, tras lo cual incrementaremos ambas direcciones en 1 y repetiremos la operación tantas veces como ancho sea el sprite. Con eso ya hemos copiado un scanline. Ahora sólo tenemos que sumar a la dirección de destino, la que apunta al buffer de pantalla, 32 – ANCHO para pasar al siguiente scanline de la pantalla y volver a repetir la copia anterior, y así tantas veces como scanlines tenga el sprite, que será ALTO * 8. Además, el valor de 32 – ANCHO lo podemos tener almacenado en un registro, por lo que sólo lo tendremos que calcular una vez, fuera de los bucles. Un ejemplo de código sería éste:
; B contiene el alto, C el ancho, ambos en caractéres
; HL contiene la dirección del primer byte del sprite
; D contiene la coordenada Y, E la coordenada X
; Asumimos que el buffer lineal de pantalla está en 0x8000
pintar_sprite:
set 7, D ; DE ya casi tiene la dirección, le falta el bit 7 de D
sla B
sla B ; rotamos tres veces B, que es igual que multiplicar por 8
sla B ; así tenemos en B la altura en scanlines
ld A, 32
sub C ; calculamos cuanto tenemos que sumar para pasar al
ld IXl, A ; siguiente scanline (32-ANCHO), y lo guardamos en IXl
bucle:
push BC ; guardamos B (pues es el contador de scanlines) y C
ld B, 0 ; preparamos el bucle interno
ldir ; copiamos C bytes (C contiene el ancho)
ld C, IXl ; sumamos IXl a DE para pasar al siguiente scanline
ex DE, HL ; funciona porque B vale cero después de LDIR
add HL, BC
ex DE, HL
pop BC ; recuperamos el número de scanlines que nos quedan
djnz bucle2 ; y repetimos por cada scanline
call paint_screen ; llamamos a la función que vuelca el buffer
; en la pantalla (si hemos pintado todos los
; sprites)
Con esta función podemos pintar fácilmente un sprite de cualquier tamaño en cualquier parte de la pantalla (a nivel de carácter). Sin embargo, hay una condición inexcusable: el sprite tiene que entrar completamente en la pantalla, no puede «estar medio fuera». Si no lo tenemos en cuenta ocurrirán «cosas raras». Así, si se sale por un lado aparecerá por el opuesto (parecido a Pacman), lo cual es erróneo pero no peligros; pero si se sale «por arriba» o «por abajo» escribiremos en zonas de memoria fuera del buffer de pantalla, por lo que lo más probable es que nuestro código se cuelgue. Afortunadamente este problema se puede solucionar.
En el caso vertical (que el sprite «se salga por arriba o por abajo») resolverlo es muy sencillo: supongamos que se sale «por abajo» porque la coordenada Y es tan grande que Y + ALTURA es mayor que la máxima coordenada «pintable» (24 en el caso del Spectrum). En ese caso simplemente tenemos que cambiar la altura del sprite (la que le pasamos a la función) por ALTURA – Y, con lo que el bucle externo pintará justo hasta el final de la pantalla, pero ni un solo byte más. Algo así:
y_no_negativa:
ld A, D
cp 24
ret NC ; si está completamente fuera de la pantalla, no pintamos nada
add A, B ; comprobamos Y + ALTURA
cp 24
; si hay acarreo, el sprite está completamente dentro de la pantalla
jr C, pintar_sprite ; lo pintamos normalmente
ld A, 24
sub D
ld B, A ; sustituimos la altura del sprite por 24 - Y
pintar_sprite:
...
Y con esto, colocando este código justo antes de la función de pintar sprites, nuestro sprite ya se puede salir «por abajo» que no pasará nada. Para permitir que se pueda salir «por arriba» la solución es la misma, pero a mayores tenemos que cambiar la dirección de inicio del sprite, saltándonos tantos scanlines como se queden fuera. Dado que Y será negativa en este caso, el número de scanlines que nos tenemos que saltar es de (-Y * 8) (ojo al signo menos), y como cada scanline tiene tantos bytes como ancho sea el sprite, tenemos que hacer una multiplicación. Este será el código:
bit 7, D ; comprueba si Y es negativa
jr Z, y_no_negativa
ld A, D
add A, B; sumando Y al alto nos da la nueva altura (no olvidar que Y es negativo, por lo que realmente es una resta)
ret Z
ret NC ; si no hay acarreo, o es cero, significa que el sprite está completamente fuera de la pantalla (B < -Y)
ld B, A ; sustituimos la altura
push BC
push DE
ld A, C ; necesitamos calcular (-Y) * ANCHO * 8 para saber
add A, A ; cuantos bytes saltar
add A, A
add A, A ; multiplicamos ANCHO por 8
ld E, A
ld A, D
neg ; A contiene -Y, que es el número de filas a saltar (en caracteres)
ld B, A
ld D, 0
bucle1:
add HL, DE ; HL + 8 * ANCHO * (-Y)
djnz bucle1
pop DE
pop BC
ld D, 0 ; pintamos a partir de la coordenada 0
jr pintar_sprite ; pintamos el sprite
y_no_negativa:
Así, colocando este código justo antes del anterior, ya podrá salirse también «por arriba» sin que pase nada.
Para tener en cuenta el que se salga «por los lados» el proceso es el mismo, pero con la diferencia de que hay que modificar la función de pintado para que, al terminar de pintar un scanline del sprite (que será más corto que el ancho real), se salte tantos bytes como haya de diferencia.
Ha llegado el momento de empezar a pintar cosas en la pantalla. Obviamente lo que queremos pintar serán Sprites. Como explica la wikipedia, se trata de gráficos 2D que se integran con una escena de fondo. Como sabemos, el Spectrum no tiene soporte de sprites por hardware, lo que significa que nos toca a nosotros hacer todo el trabajo de pintarlos. Afortunadamente, en las entradas anteriores vimos cómo hacer una rutina que copie a la pantalla una imagen completa desde un buffer organizado de manera secuencial, y esto nos va a simplificar la tarea, como veremos.
Lo primero que necesitamos saber para pintar algo en pantalla es a partir de qué dirección de memoria tenemos que hacerlo. Si recordamos, la pantalla del Spectrum está formada por una matriz de 256 píxels de ancho por 192 de alto, y cada píxel puede tener dos colores, por lo que cada uno ocupa un bit. Esto significa que cada fila o scanline de la pantalla ocupa 32 bytes, y la parte de píxeles de la pantalla ocupa en total 6 144 bytes o 6 Kbytes exactos.
Sin embargo, justo a continuación viene una segunda zona denominada atributos, que define una matriz de 32 por 24 atributos y asigna un byte a cada uno. Este byte de atributos especifica qué colores tendrán un grupo de píxeles. En concreto, cada byte define dos colores para cada grupo de 8×8 píxeles de la pantalla: uno será el color que se mostrará cuando el bit correspondiente al píxel esté a cero, y el otro cuando esté a uno. Esta zona empieza en la dirección de memoria 22 528 y ocupa un total de 768 bytes. Este sistema permite al Spectrum mostrar hasta 16 colores simultáneos en pantalla pero consumiendo muy poca memoria.
Como ya vimos en la primera entrada, la organización de la pantalla es algo caótica. Veámoslo en un gráfico:
Vemos que los bytes situados en las direcciones de memoria en hexadecimal 0x4000, 0x4100, 0x4200, 0x4300, 0x4400, 0x4500, 0x4600 y 0x4700 se corresponden con el bloque de 8×8 píxeles superior izquierdo de la pantalla, y que los atributos de dicho bloque están almacenados en la dirección 0x5800, que especifica que los dos colores de ese grupo de píxeles son blanco y negro. El siguiente bloque de 8×8 píxeles está en las direcciones 0x4001, 0x4101, 0x4201, 0x4301, 0x4401, 0x4501, 0x4601 y 0x4701, y sus atributos, que indican que los dos colores mostrados serán celeste y rojo, están en la dirección 0x5801. Y así sucesivamente. Esta disposición puede parecer absurda, pero si nos fijamos, vemos que la dirección de memoria de un scanline de píxeles y la de los atributos que le corresponden tienen el mismo valor en los ocho bits inferiores. Gracias a esta característica, es posible leer los dos bytes necesarios para mostrar los ocho píxeles en sólo tres ciclos de reloj, en lugar de los cuatro que se necesitarían si ambas direcciones no tuviesen siempre un byte idéntico (lo que se denomina fast-page). Y si tenemos en cuenta que cada bloque de 8 píxeles tarda cuatro ciclos de reloj en ser pintado, salta a la vista de donde sale el ciclo de contención de memoria que vimos en el primer artículo: la circuitería «compacta» la lectura de dos grupos de 8 píxeles consecutivos, de manera que en lugar de bloquear al procesador durante tres ciclos y liberarlo uno, lo bloquea durante seis ciclos y lo libera durante dos consecutivos. Además, de esta manera se garantiza también que los siete bits bajos se recorren completos aproximadamente cada milisegundo, lo que es más que de sobra para garantizar el refresco de la RAM.
Obviamente este sistema se implementó porque permite abaratar y simplificar el hardware, pero tiene el inconveniente de que, a la hora de programar para él, es bastante engorroso calcular la dirección de memoria que se corresponde con cada coordenada. Así, si dividimos la pantalla en caracteres (bloques de 8×8 píxeles) y queremos encontrar las ocho direcciones de memoria de sus ocho bytes, la operación que hay que hacer es la siguiente (gráficamente):
En azul tenemos la coordenada X, que puede valer entre 0 y 31 para las 32 columnas del Spectrum. En verde y magenta tenemos la coordenada Y en líneas: en la parte verde estaría la coordenada Y en caracteres (de 0 a 23), y en magenta sería el scanline dentro de ese carácter, todo de arriba a abajo y de izquierda a derecha. A mayores es necesario poner los tres bits superiores a 010 para que apunte al bloque de memoria concreto. Como vemos, la cosa es bastante complicada y requiere rotaciones y máscaras. Sin embargo, gracias a las rutinas que vimos en las entradas anteriores esta complicación desaparece completamente. Si las utilizamos, la conversión es tan sencilla como:
Ponemos los tres bits superiores a 100 porque, para simplificar, colocamos el buffer en la dirección 0x8000 (32768). De esta manera, si ponemos la coordenada X en el byte inferior y la coordenada Y en la superior, sólo tendremos que poner a uno el bit 7 del byte inferior y ya tendremos la dirección de memoria del scanline superior del carácter con dichas coordenadas; para pasar al siguiente carácter sólo tenemos que sumar uno; para pasar al anterior, restar uno; para pasar al que está encima, restar 32, y para pasar al que está debajo, sumar 32. Tan simple como esto. ¿Y si tenemos una dirección de píxeles, cómo calculamos la de sus atributos? Pues sólo tenemos que hacer esto:
Sencillo ¿no? Aunque para los que no se quieran complicar, aquí está un trozo de código que lo hace:
; Asumimos que HL contiene la dirección de memoria
; de un byte de pantalla
ld a, l
and 0x1F
ld l, a
ld a, h
rrca
rrca
rrca
ld h, a
and 0xE0
or l
ld l, a
ld a, h
and 3
or 0x98
ld h, a
; Ahora HL contiene la dirección de memoria del atributo
; que corresponde con el byte de pantalla inicial
Y como esta entrada quedó ya algo larga, seguiré en la siguiente.
Editado: ya había un programa llamado ZXEditor, así que he renombrado mi editor a ZXSpriter
Después de mis tres entradas anteriores, llegó el momento de empezar a pintar cosas en el Spectrum, pero me encontré con que no había ninguna herramienta que me convenciese para hacer gráficos compatibles, así que me lié la manta a la cabeza y he escrito ZXSpriter. Se trata de un editor de Sprites que se adapta a mis necesidades, pues no sólo permite crear un número ilimitado de sprites y exportarlos a formato ensamblador, listos para integrarse con mi código, sino que permite que cada sprite sea de diferente tamaño, que tenga o no máscara de transparencia, o incluso datos de atributos de color.
Ahora que tengo este editor, en un par de días espero publicar una nueva entrada explicando cómo pintar sprites.
El código anterior es funcional, pero tiene el problema de que ocupa 541 bytes (código más la tabla de direcciones). Teniendo en cuenta que la memoria de vídeo son casi siete kbytes, y otros siete más para el segundo buffer, tenemos que esos 541 bytes pueden ser un gasto excesivo de los 34,5 kbytes restantes de un Spectrum 48K (en un 128K tenemos doble página por hardware, con lo que no necesitamos nada de esto).
Para solucionarlo, en lugar de utilizar una tabla con todas las direcciones de memoria podemos utilizar una tabla sólo con las direcciones de inicio de cada bloque de caracteres (o sea, una de cada ocho filas de píxels). Esto es posible porque pasar de una fila a la siguiente en un bloque de caracteres es relativamente sencillo: sólo hay que incrementar el byte alto. Así, si tenemos en DE la dirección de un byte en una fila, sólo necesitamos hacer INC D para pasar a la siguiente fila (siempre que no sea la última fila de un carácter, claro).
Así que combinando todo lo anterior, podemos usar esta función:
LD SP, tabla_direcciones
LD HL, buffer
LD BC, 0
EXX
LD HL, buffer + 6144
LD DE, 0x5800 ; zona de atributos de color
LD BC, 768 ; 32 columnas * 24 lineas
loop_l1:
EXX
INC B ; como BC es cero, esto es igual que LD BC, 256
; esto son 32 x 8 bytes en una fila de caracteres
POP DE ; obtenemos la dirección inicial de la fila de caracteres
LD IXh, E ; usamos una instrucción no oficial porque
; estamos justos de registros
LD A, D
loop_l2:
INC A ; preparamos ya la dirección de la siguiente fila
; hay que hacerlo antes de LDI porque INC modifica
; los flags
LDI
... ; 32 LDIs en total
LDI
LD E, IXh ; recuperamos la posición inicial
LD D, A ; y la siguiente fila
JP PE, loop_l2
EXX
LDI
... ; 32 LDIs en total
LDI
JP PE, loop_l1
...
tabla_direcciones:
DEFW 0x4000, 0x4020, 0x4040, 0x4060, 0x4080, 0x40A0, 0x40C0, 0x40E0
DEFW 0x4800, 0x4820, 0x4840, 0x4860, 0x4880, 0x48A0, 0x48C0, 0x48E0
DEFW 0x5000, 0x5020, 0x5040, 0x5060, 0x5080, 0x50A0, 0x50C0, 0x50E0
Y con esto lo tenemos ya, y altamente optimizada, pues en realidad esto ha sido el final de muchas iteraciones. Empecé utilizando DJNZ para las ocho iteraciones del bucle interno (loop_l2), y para conservar la dirección inicial de la fila de caracteres, lo que hacía era meter DE de nuevo en la pila con un PUSH, para sacarlo después de los LDIs y poder incrementar D para pasar a la siguiente fila. Esto era mucho más rápido que almacenarlo en alguna zona de la memoria (20 Tstados) o que decrementar dos veces el puntero de pila para que volviese a apuntar al valor inicial (12 Tstados).
La siguiente optimización que hice fue almacenar el valor de E en el registro A, de manera que después de los LDIs sólo tenía que hacer un LD E, A y ya tendría el valor original. Por desgracia esto CASI funcionaba, pues en las filas de caracteres 7, 15 y 23, al llegar al final de la línea se producía un desbordamiento y se sumaba uno a D, con lo que fallaba. Una solución sería reducir el número de columnas de 32 a 31, pero no era una solución muy elegante, así que al final decidí que era mejor almacenar D en A, y guardar E en una posición de memoria. Pero como no existe LD (nn), E ni la inversa, no podía hacerlo directamente… a menos que usase código automodificable. ¿Qué es esto? La instrucción LD E, 0 se codifica como 0x1E 0x00, siendo el segundo byte el valor a meter en el registro E. Así que lo que hacía era poner un LD E, 0 justo después de todos los LDIs, y después del primer POP DE almacenaba el valor de E justo en el segundo byte de la instrucción LD E, 0. De esta manera, cada vez que se hace una pasada en el bucle, el código ha cambiado. Aunque es más rápido, pues mientras que el par PUSH-POP son 22 Tstados en cada fila, con esto eran sólo 11 Tstados dentro de loop_l2, no me gusta nada usar código automodificable, así que me devané los sesos hasta que me acordé de que tenía cuatro registros extra de 8 bits: las mitades de IX e IY. Es cierto que son funcionalidades no documentadas, pero funcionan en todos los Z80. Así que la solución fue almacenar E en IXh (que consume 8 Tstados), y guardar D en A. Y además, el resultado es ligeramente más rápido también: aunque dentro del bucle pierdo ocho Tstados, pues LD E, 0 es 1 Tstado menos que LD E, IXh y el bucle se repite ocho veces, los compenso fuera, pues LD A, E son 4 Tstados y LD (nn), A son 13, 17 Tstados en total, mientras que LD IXh, E son sólo 8, con lo que, al final, usando IXh en lugar de código automodificable ahorro 1 Tstado por cada fila de caracteres (8 filas de píxels). Además, no hay que olvidar tampoco que esos 7 Tstados se convertirían en más siempre que hubiese contienda en la memoria, con lo que es un win-win.
Y con esto tenemos una función que ocupa 195 bytes en total (171 bytes más 24 de la tabla), a costa de ser un poco más lenta. ¿Cuanto más? El bucle interno son 4 + 512 + 8 + 4 + 10 = 538 Tstados, y hay que repetirlo 8 veces. Pero en caso de contienda, serán 544 Tstados, luego la duración será entre 4 304 y 4 352 Tstados. El bucle externo son 4 + 4 + 11 + 8 + 4 + 4 + 512 + 10 = 557 Tstados, pero con contienda serán 560 Tstados, y esto repetido 24 veces, una por cada fila de caracteres. Con esto tenemos que copiar una pantalla completa serán entre 116 664 y 117 888 Tstados. Aplicando la fórmula de la entrada anterior podemos aproximar a 117 597 Tstados, lo que es superior a los 112 800 Tstados de una pantalla completa. Si sólo hacemos 23 filas necesitamos 112 696 Tstados para copiar la pantalla frente a 111 008 Tstados disponibles antes de que nos alcance el haz. Pero si hacemos 22 filas, tardaremos 107 797 Tstados, frente a 109 216 Tstados que tarda el haz en alcanzar ese punto, por lo que con esta rutina, aunque ahorramos casi dos tercios de memoria, perdemos una fila respecto a la rutina anterior.
Sin embargo, no debemos olvidar que esto sólo significa que no podemos tener animaciones fluidas en las dos últimas filas de la pantalla, pero sí podemos tener gráficos estáticos o semi-estáticos como un marcador, un inventario… cosas que no cambien demasiado a menudo de manera que un artifact durante su modificación pase desapercibido.
Esta mañana estaba revisando mi código y se me ocurrió una pequeña optimización. JP cc, nn (salto condicional) necesita 10 Tstados, mientras que DJNZ necesita 13 cuando no se cumple la condición, y 8 cuando sí se cumple. Dado que siete veces no se cumple pero una sí se cumple, si podemos sustituir el DJNZ por un JP pe, nn, ahorraremos 19 Tstados en cada fila. Sólo tenemos que cargar BC con 256, que es el número de transferencias que tenemos que hacer entre grupos de atributos. Pero además, dado que cada vez que terminamos una fila de caracteres BC valdrá cero, podemos simplemente incrementar B en uno, que es una operación más rápida que cargar un número, con lo que ahorraremos 3 Tstados más. Así quedaría el código:
LD SP, tabla_direccionesLD HL, buffer
LD BC, 0 ; mismo valor que si hubiésemos hecho una fila entera
EXX ; cambiamos al juego de registros alternativoLD HL, buffer + 6144 ; apunta a los atributos de color del bufferLD DE, 22528 ; zona de atributos de la pantallaLD BC, 768 ; tamaño de los atributos
loop1:
EXX ; volvemos al juego original con los datos de píxeles
INC B ; como BC aquí vale cero, esto es igual que LD BC, 256
; pero más rápido
loop2:
POP DE
LDI
… ; 32 LDIs en total
LDI
JP PE, loop2
EXX
LDI
… ; 32 LDIs en total
LDI
JP PE, loop1 ; no podemos usar DJNZ porque el salto es
; de más de 128 bytes
…
tabla_direcciones:
DEFW 0x4000, 0x4100, 0x4200, 0x4300, 0x4400, 0x4500, 0x4600, 0x4700
DEFW 0x4020, 0x4120, 0x4220, 0x4320, 0x4420, 0x4520, 0x4620, 0x4720
; completar hasta las 192 líneas
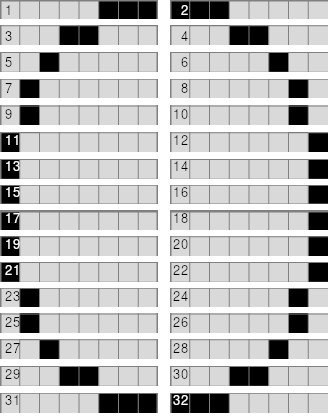
Ahora el bucle interno dura 11 + 512 + 10 = 533 Tstados, aunque en las zonas con contienda serán 536, por lo que necesitaremos entre 4 264 y 4 288 Tstados por cada fila de caracteres. Sumando la parte de los atributos tenemos que serán 4 + 4 + 4 + 512 + 10 = 534 Tstados extra, que cuando haya contienda subirá a 536 Tstados. Y esto para cada una de las 24 filas de la pantalla, lo que nos da entre 115 152 y 115 776 Tstados, lo que significa que en el peor de los casos estamos igual, pero en el mejor ahorramos algo.
¿Pero realmente existe ese «mejor de los casos» si, al escribir en pantalla, siempre tenemos contienda? En realidad esto sólo es verdad a medias: sólo tenemos contienda cuando la ULA está leyendo de la memoria para pintar el paper, pero no cuando está pintando el borde. Teniendo en cuenta que de las 312 líneas de la pantalla, sólo 192 tienen contienda, y las 192 las recorremos dos veces (pues primero el haz va por delante nuestra, pero al llegar al final de la pantalla y volver al principio va por detrás hasta que nos alcanza) tenemos un total de 504 líneas, de las cuales 120 no tienen contienda. Eso significa que el tiempo real será, aproximadamente, 0,762 * tiempo_peor + 0,238 * tiempo mejor. Por tanto, en este caso, tenemos que tardaremos 115 627 Tstados, frente a los 115 764 Tstados del caso anterior. No es mucha diferencia, pero cualquier Tstado que ahorremos es tiempo que podemos emplear luego en generar el siguiente frame. Y teniendo en cuenta que antes de pintarlo tenemos que sincronizarnos con la pantalla, el pasarnos tan solo un Tstado puede hacer que tengamos que esperar al siguiente frame de la pantalla.
Cuando tenía 12 años heredé el Sinclair ZX Spectrum de mi hermano. Era un ordenador que me fascinaba, y con él aprendí a programar, primero en BASIC, y luego directamente en Ensamblador. También aprendí rudimentos de electrónica digital, y gracias a ello construí varios circuitos que le acoplé, como un teclado nuevo, un puerto de E/S de 16 bits, y más.
Es una máquina a la que siempre le tuve mucho cariño, y por eso me lancé hace unos años a escribir mi propio emulador, FBZX, cuando los que había en aquel entonces no me acababan de convencer. Y recientemente, a raíz de varios canales de youtube de «nostalgia de 8 bits», me he puesto un poquito así y he decidido intentar programar algo. Al principio probé a usar el compilador de Z88dk para poder utilizar lenguaje C, hasta que vi la chapuza de código que genera (algo que no es culpa de los desarrolladores, sino de la propia arquitectura del Z80, que no es nada adecuada para C y, sencillamente, es imposible generar mejor código). Ante esto, decidí pasarme a Z80ASM y trabajar desde cero en ensamblador. A fin de cuentas, en una máquina de 8 bits cada bit cuenta, y el poder optimizar cada rutina hasta la última instrucción puede ser la diferencia entre conseguir o no conseguir algo concreto.
Y precisamente una de las cosas en donde la velocidad es crítica es a la hora de pintar en la pantalla, pues, por desgracia, el Spectrum original no tiene ninguna ayuda para esa tarea, si siquiera una doble página (a pesar de que sólo habría requerido añadir un único flip-flop a la ULA). El Spectrum 128K sí tiene dos páginas de vídeo, lo que permite que la ULA muestre una de ellas mientras el código genera el siguiente fotograma en la otra página, y cuando haya terminado, sólo tiene que esperar a que la ULA empiece a pintar un nuevo cuadro para cambiar la página activa, de manera que ahora se mostrará lo que haya en la segunda página y el programa podrá pintar el siguiente fotograma en la primera página.
Cuando se usa el sistema de doble página, las animaciones van fluidas y sin parpadeos ni deformaciones. Por desgracia, los modelos de 48K, al no tener esta capacidad, obligan al programador a sincronizarse con el haz de electrones de la pantalla para evitar que «le pille el rayo» en mitad de un acceso a la pantalla. Hay mucha literatura al respecto, así que no voy a entrar en explicar en qué consiste lo de «competir con el haz«. Sí voy a dar, sin embargo, algunas notas sobre cómo funciona la pantalla en el Spectrum. Para ello, veamos este dibujo de una televisión con la imagen generada por la circuitería del ordenador (la famosa ULA):
Una televisión con la imagen generada por un Spectrum.
En el dibujo vemos una televisión, y en la pantalla podemos ver las dos zonas en las que se divide la imagen generada por la ULA en el Spectrum: el border (en color verde en el dibujo) y el paper, o la zona de trabajo, en color blanco. También vemos esquematizado el recorrido del haz de electrones, de derecha a izquierda y de arriba a abajo, aunque exagerado. El border es una zona en la que sólo podemos definir qué color global queremos, pero no podemos pintar en ella. Sólo en el paper podemos pintar píxeles escribiendo en una zona de memoria, a partir de 0x4000 hasta 0x5800, en donde cada bit se corresponde con un pixel. Esta zona se divide en 256×192 pixels. A mayores, justo a continuación se encuentra la zona que almacena los atributos de color, que mide 768 bytes. Esta zona ocupa un byte para cada grupo de 8×8 píxels, y especifica qué color se usará para cuando el bit asociado a cada pixel está a 0 o a 1.Para más detalles, recomiendo leer la información de World of Spectrum sobre la memoria de vídeo. Edito: o bien la entrada número 4 de esta misma serie, donde entro en más profundidad en cómo es la distribución de la pantalla en el Spectrum. Siento no haber hecho las cosas en orden.
La ULA refresca la pantalla a una tasa de 50 veces por segundo. Además, para simplificar la circuitería, no utiliza entrelazado, sino que siempre pinta únicamente las líneas impares. Y dado que el reloj de la CPU va a 3,5 MHz, eso significa que desde que comienza a pintar la imagen, en la esquina superior izquierda del borde, hasta que ha terminado y empieza a pintar la siguiente, tenemos, en teoría, 3 500 000 / 50 = 70 000 ciclos de reloj o Tstados. Y como tenemos 312,5 líneas (recordemos que sólo utilizamos medio campo, por lo que es la mitad de 625), cada línea dura 224 Tstados. En la práctica no podemos tener media línea, por lo que, en realidad, cada frame dura 69 888 Tstados y tenemos un total de 312 líneas. Además, sabemos que cada vez que se empieza a pintar un frame, la ULA genera una interrupción, la cual podemos utilizar para sincronizarnos con la generación de la imagen. Por último, hay 64 líneas de border antes de que empiece a pintarse el paper.
Con todo esto ya podemos hacer un primer cálculo, que nos dice que si queremos estar seguros de que hemos pintado todo en pantalla antes de que el haz llegue al paper, tenemos que hacerlo en menos de 64 * 224 = 14 336 Tstados. Por desgracia esto es muy poco tiempo.
Una solución consiste en esperar a que la ULA haya terminado de pintar el paper y, entonces, pintar lo que necesitemos. En este caso tendremos 69 888 – (224 * 192) = 26 880 Tstados, que es el tiempo que tarda en pintar la parte inferior y la superior del borde. Ya es un poco más, pero todavía no llega para demasiado.
La solución que usan muchos juegos consiste en implementar una doble página por software. Para ello, pintan toda la imagen en una zona diferente de memoria, y cuando está lista, la copian de golpe en la memoria de pantalla. De esta manera la imagen que aparece siempre es definitiva y no hay parpadeos. El inconveniente es que consume casi siete Kbytes extra.
El problema es que, como de costumbre, la cosa no es tan sencilla. Veamos por qué. La primera idea, la más naive, sería utilizar la instrucción LDIR del Z80. Esta instrucción permite copiar un bloque de memoria a otra posición, y recibe tres parámetros: la dirección inicial del bloque (en el registro HL), la dirección de destino (en el registro DE), y el tamaño del bloque (en el registro BC), y hace todo el trabajo por nosotros: lee el byte contenido en la dirección de memoria apuntada por HL, lo escribe en la dirección de memoria apuntada por DE, incrementa en uno ambos registros, decrementa en uno el registro BC, y repite la operación hasta que este último valga cero. ¡Una bicoca! Así que lo único que tendríamos que hacer es esperar a la interrupción, cargar los valores en los registros, y ejecutar LDIR. ¿O no?
El problema es que cada iteración de LDIR consume 21 Tstados. Eso significa que una pantalla completa, que ocupa 6 912 bytes, tardará 145 152 Tstados en copiarse… ¡que es más del doble de lo que se tarda en generarse! Eso significa que el haz nos alcanzará como mínimo dos veces en cada volcado. Y sí, digo «como mínimo», porque por cuestiones de diseño, la pantalla no se almacena de manera secuencial en memoria, sino que primero viene la fila 0 de pixels, ocupando 32 bytes, luego la fila 8, luego la 16, 24, 32, 40, 48 y la 56, momento en que vuelve atrás hasta la fila 1, luego la 9, la 17… Eso hace que podamos cruzar el haz varias veces, y complica aún más la gestión de la pantalla.
Por si fuera poco, hay un segundo problema, y es que la ULA interfiere en el acceso a la RAM cuando está generando la imagen. Esto es debido a que en chips de RAM normales no es posible que dos sistemas lean o escriban a la vez, sino que se tienen que turnar. La ULA necesita leer dos bytes (uno con los pixels, y otro con los atributos de color) cada cuatro Tstados mientras está pintando el paper, y sólo deja la memoria libre cuando está pintando el borde. Para conseguir esto, lo que hace es monitorizar constantemente a la CPU, y si intenta acceder a la zona de vídeo mientras la ULA está pintando el paper, le detiene el reloj a la CPU hasta que termine.
Por suerte, gracias a un ingenioso diseño, la ULA sólo necesita tres Tstados para leer esos dos bytes, así que lo que hace es agrupar dos lecturas seguidas y dejar los dos Tstados restantes para la CPU. Esto significa que, si queremos que la escritura en la zona de vídeo no se vea penalizada por la ULA, tenemos que hacer accesos con un periodo que sea múltiplo de ocho Tstados. De esta manera, el primer acceso se verá retrasado entre uno y seis Tstados según donde caiga, pero el resto coincidirán exactamente en el siguiente hueco. Y este es otro de los problemas de LDIR: como cada ciclo dura 21 Tstados, que no es múltiplo de ocho, significa que, en la práctica, será como si la instrucción durase 24 Tstados (la primera hará la escritura en el primer hueco libre; la segunda lo hará en el segundo hueco, tres periodos después, con lo que ambas durarán 21 Tstados; la tercera, en cambio, se retrasará seis Tstados, la cuarta no sufrirá retraso, la quinta se retrasará seis Tstados… y así sucesivamente).
Sin embargo, si vemos el juego de instrucciones, comprobaremos que existe también una instrucción similar, LDI, que hace lo mismo excepto repetir la operación, y sólo consume 16 Tstados, que, además, es múltiplo de 8 y, por tanto, no sufriría penalización por parte de la ULA. ¿Qué pasaría si pusiésemos una laaaaaarga ristra de ellas, una detrás de otra? Pues que necesitaríamos 6 912 * 16 = 110 592 Tstados. Aún es más que el tiempo que se necesita para refrescar una pantalla, pero aún nos queda un as en la manga. ¿Qué ocurriría si esperamos a que el haz llegue hasta el principio del paper, y justo entonces empezamos a pintar? En ese caso, el haz iría por delante nuestra, y nunca lo adelantaríamos porque ya hemos visto que somos más lentos que él, y eso significa que cuando el haz haya pintado toda la pantalla y vuelto al punto de partida, ya llevaremos más de la mitad de la imagen pintada y, además, tendremos aún casi otro frame de tiempo antes de que nos alcance.
Veamos exactamente de cuanto tiempo disponemos. Tenemos los 69 888 Tstados que tarda en recorrer un frame, y ahora tenemos que sumarle el tiempo que tarda en llegar hasta el borde inferior derecho del paper. Esto será 224 Tstados_por_linea * 191 lineas_completas + 128 Tstados_de_la_ultima_linea = 42 912 Tstados. Esto significa que si utilizamos este truco, tendremos disponibles un total de 112 800 Tstados para copiar la pantalla antes de que nos alcance el haz, que es más de lo que tarda la ristra de LDIs. ¡Buena cosa!
Por desgracia, esta idea tiene dos problemas:
Para que funcione, tenemos que escribir los datos de manera lineal en la pantalla, de manera que nos mantengamos siempre por detrás del haz. Pero si usamos LDI directamente, se hará de manera escalonada por cómo está organizada la pantalla del Spectrum, y adelantaremos y retrasaremos al haz constantemente.
Cada instrucción LDI ocupa dos bytes, lo que significa que necesitaríamos una ristra de instrucciones que ocuparía el doble que el tamaño del bloque a copiar, lo que supone un desperdicio exagerado de memoria.
Así, dado que la única secuencia consecutiva que tenemos son los 32 bytes de cada línea, la solución es utilizar una secuencia de 32 instrucciones LDI, y modificar entre medias los registros para ir línea a línea. El problema es que cómo hacerlo con el mínimo de instrucciones posible, pues de nada sirve si perdemos por un lado lo que ahorramos por otro.
La primera solución consiste en tener una tabla con las direcciones de cada scanline, de manera que sólo tenemos que coger la dirección actual, ejecutar 32 instrucciones LDI, y repetir el bucle hasta que el flag de desbordamiento (overflow) se active después de la última instrucción LDI. El problema es que LDI utiliza los tres pares de registros principales, con lo que no nos queda nada para mantener un puntero a la lista de direcciones…
¿O sí que lo tenemos? Porque podemos simplemente cargar el puntero de pila SP con la dirección de la tabla, y leer los valores directamente con POP DE. Esta instrucción tiene la ventaja de que con sólo 11 Tstados nos carga un valor de 16 bits e incrementa el puntero de la tabla.
El resultado sería este código:
LD SP, tabla_direcciones LD HL, buffer LD BC, 6144 ; tamaño del buffer. De momento prescindimos del color loop: POP DE LDI LDI … ; 32 instrucciones LDI en total LDI JP PE, loop … tabla_direcciones: DEFW 0x4000, 0x4100, 0x4200, 0x4300, 0x4400, 0x4500, 0x4600, 0x4700 DEFW 0x4020, 0x4120, 0x4220, 0x4320, 0x4420, 0x4520, 0x4620, 0x4720 …. ; completar hasta las 192 líneas
Este código es muy rápido: dado que la instrucción JP consume 10 Tstados, tenemos que copiar cada fila consume un total de 533 Tstados; pero como tenemos que redondear a un múltiplo de 8 para tener en cuenta la contienda de memoria, se nos quedan en 536 Tstados; y como una pantalla completa son 192 líneas, al final gastamos entre 102 336 y 102 912 Tstados (no olvidemos que sólo hay contienda mientras se pinta el paper, nunca mientras se pinta el border, por lo que el valor final estará entre ambos), lo que está muy por debajo del límite de 112 800 Tstados. ¡Buena cosa! Por desgracia, nos falta por copiar los atributos de color, y el problema es que tenemos que copiar una fila de atributos por cada ocho de píxels, pues tenemos que mantenernos por detrás del haz catódico; no podemos copiar primero todos los píxels y luego todos los atributos. El problema es que ya estamos usando absolutamente todos los registros con la instrucción LDI, y ni siquiera tenemos la pila disponible para almacenar los valores entre uno y otro grupo.
¡¡¡Pero tenemos el juego de registros alternativo!!! El Z80 tiene su conjunto principal de registros, AF, BC, DE y HL, pero también tiene un segundo juego, AF’, BC’, DE’ y HL’, que podemos intercambiar con sólo dos instrucciones: EX AF, AF’ (que intercambia los valores de AF y AF’) y EXX (que intercambia los valores de BC, DE y HL con los de sus homólogos). Así que, dado que los atributos de color sí siguen un formato normal, podemos copiar ocho filas primero usando la tabla, cambiar al juego alternativo de registros, copiar una fila de atributos de color, volver a cambiar el juego, copiar otras ocho filas de pixeles, etc. El código quedaría así:
LD SP, tabla_direcciones LD HL, buffer EXX ; cambiamos al juego de registros alternativo LD HL, buffer + 6144 ; apunta a los atributos de color del buffer LD DE, 22528 ; zona de atributos de la pantalla LD BC, 768 ; tamaño de los atributos loop1: EXX ; volvemos al juego original con los datos de píxeles LD B, 9 ; las ocho filas necesitan 256 LDIs. Cada uno resta ; uno a BC; luego al final de ellos, C valdrá lo mismo ; pero B se habrá decrementado en una unidad. Así ; que tenemos que tenerlo en cuenta para DJNZ loop2: POP DE LDI … ; 32 LDIs en total LDI DJNZ loop2 EXX LDI … ; 32 LDIs en total LDI JP PE, loop1 ; no podemos usar DJNZ porque el salto es ; de más de 128 bytes … tabla_direcciones: DEFW 0x4000, 0x4100, 0x4200, 0x4300, 0x4400, 0x4500, 0x4600, 0x4700 DEFW 0x4020, 0x4120, 0x4220, 0x4320, 0x4420, 0x4520, 0x4620, 0x4720 ; completar hasta las 192 líneas
El bucle interno consume un total de 512 + 11 + 13 = 536 Tstados cuando B es distinto de cero (que, además, es múltiplo de 8), y 512 + 11 + 8 = 531 Tstados cuando B es cero. Por tanto, para ocho filas tenemos un total de 536 * 7 + 531 = 4 283 Tstados. Pero a esto hay que sumar la inicialización previa y la copia de los atributos. Antes tenemos, del EXX y el LD B, 9, un total de 4 + 7 = 13 Tstados, y después 4 + 512 + 10 = 526 Tstados; luego cada fila completa de 8 píxels de altura y con atributos necesita un total de 4 283 + 13 + 526 = 4 822 Tstados. Pero para que sea múltiplo de 8 hay que subir a 4 824 Tstados. Y como tenemos 24 filas, el total estará entre 115 728 y 115 776 Tstados.
Vaya, ahora nos hemos pasado. Una pena, porque eso significa que no podemos animar algo a pantalla completa sin que haya artifacts. Pero si copiamos sólo 23 filas sí nos da tiempo, pues ahí no necesitaríamos más de 110 952 Tstados. Por tanto, una solución consiste en obviar la última fila, lo cual no tiene por qué ser un problema, pues normalmente se suele dejar la parte baja de la pantalla para marcadores y otros elementos relativamente estáticos. Además, tenemos la ventaja de que el buffer de trabajo está en un formato secuencial, lo que simplifica pintar en él.
Esta rutina ya sería utilizable, pero tiene el inconveniente de necesitar una tabla de 384 bytes para las direcciones, que es mucho mayor que los 157 bytes de la rutina en sí. Sin embargo, si renunciamos a las dos últimas filas en lugar de sólo a la última, podemos reducir muchísimo la memoria consumida. Pero eso será en el próximo artículo.
Utilizamos cookies para garantizar que tenga la mejor experiencia en nuestro sitio web.